机器学习(8)--异常检测算法isolation forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结。
孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或者基尼指数来选择。在建树过程中,如果一些样本很快就到达了叶子节点(即叶子到根的距离d很短),那么就被认为很有可能是异常点。因为那些路径d比较短的样本,都是因为距离主要的样本点分布中心比较远的。也就是说,可以通过计算样本在所有树中的平均路径长度来寻找异常点
iTree
提到森林,自然少不了树,毕竟森林都是由树构成的,看Isolation Forest(简称iForest)前,我们先来看看Isolation Tree(简称iTree)是怎么构成的,iTree是一种随机二叉树,每个节点要么有两个女儿,要么就是叶子节点,一个孩子都没有。给定一堆数据集D,这里D的所有属性都是连续型的变量,iTree的构成过程如下:
- 随机选择一个属性Attr;
- 随机选择该属性的一个值Value;
- 根据Attr对每条记录进行分类,把Attr小于Value的记录放在左女儿,把大于等于Value的记录放在右孩子;
- 然后递归的构造左女儿和右女儿,直到满足以下条件:
- 传入的数据集只有一条记录或者多条一样的记录;
- 树的高度达到了限定高度;
iTree构建好了后,就可以对数据进行预测啦,预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点;对于一个包含n条记录的数据集,其构造的树的高度最小值为log(n),最大值为n-1,论文提到说用log(n)和n-1归一化不能保证有界和不方便比较,用一个稍微复杂一点的归一化公式:

就是记录x在由n个样本的训练数据构成的iTree的异常指数,取值范围为[0,1],越接近1表示是异常点的可能性高,越接近0表示是正常点的可能性比较高,如果大部分的训练样本的s(x,n)都接近于0.5,说明整个数据集都没有明显的异常值。
随机选属性,随机选属性值,一棵树这么随便搞肯定是不靠谱,但是把多棵树结合起来就变强大了;
iForest
iTree搞明白了,我们现在来看看iForest是怎么构造的,给定一个包含n条记录的数据集D,如何构造一个iForest。iForest和Random Forest的方法有些类似,都是随机采样一一部分数据集去构造每一棵树,保证不同树之间的差异性,不过iForest与RF不同,采样的数据量不需要等于n,可以远远小于n,论文中提到采样大小超过256效果就提升不大了,明确越大还会造成计算时间的上的浪费,为什么不像其他算法一样,数据越多效果越好呢,可以看看下面这两个个图,
左边是元素数据,右边是采样了数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之和,异常样本和正常样本可以明显的分开。
除了限制采样大小以外,还要给每棵iTree设置最大高度,这是因为异常数据记录都比较少,其路径长度也比较低,而我们也只需要把正常记录和异常记录区分开来,因此只需要关心低于平均高度的部分就好,这样算法效率更高,不过这样调整了后,后面可以看到计算需要一点点改进,先看iForest的伪代码:
IForest构造好后,对测试进行预测时,需要进行综合每棵树的结果,于是
s(x,n)=2(−E(h(x))c(n))s(x,n)=2(−E(h(x))c(n))
E(h(x))E(h(x))表示记录x在每棵树的高度均值,另外h(x)计算需要改进,在生成叶节点时,算法记录了叶节点包含的记录数量,这时候要用这个数量SizeSize估计一下平均高度,h(x)的计算方法如下:
处理高维数据
在处理高维数据时,可以对算法进行改进,采样之后并不是把所有的属性都用上,而是用峰度系数Kurtosis挑选一些有价值的属性,再进行iTree的构造,这跟随机森林就更像了,随机选记录,再随机选属性。
只使用正常样本
这个算法本质上是一个无监督学习,不需要数据的类标,有时候异常数据太少了,少到我们只舍得拿这几个异常样本进行测试,不能进行训练,论文提到只用正常样本构建IForest也是可行的,效果有降低,但也还不错,并可以通过适当调整采样大小来提高效果。
主要参数和函数介绍
class
sklearn.ensemble.
IsolationForest(n_estimators=100, max_samples=’auto’, contamination=0.1, max_features=1.0, bootstrap=False, n_jobs=1, random_state=None, verbose=0)
参数:
n_estimators : int, optional (default=100)
森林中树的颗数
max_samples : int or float, optional (default=”auto”)
对每棵树,样本个数或比例
contamination : float in (0., 0.5), optional (default=0.1)
这是最关键的参数,用户设置样本中异常点的比例
max_features : int or float, optional (default=1.0)
对每棵树,特征个数或比例
函数:
fit(X)
Fit estimator.(无监督)
predict(X)
返回值:+1 表示正常样本, -1表示异常样本。
decision_function(X)
返回样本的异常评分。 值越小表示越有可能是异常样本。
IsolationForest实例
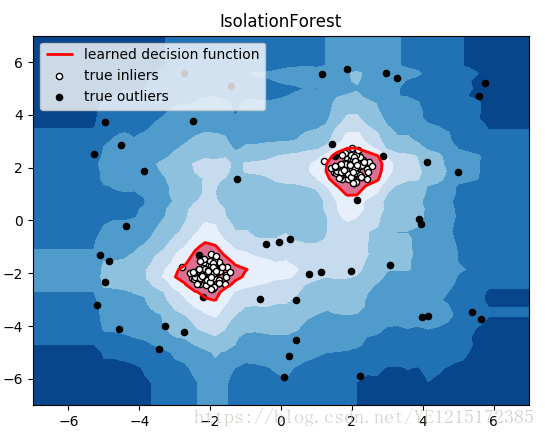
[code]#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
from scipy import stats
rng = np.random.RandomState(42)
# 构造训练样本
n_samples = 200 #样本总数
outliers_fraction = 0.25 #异常样本比例
n_inliers = int((1. - outliers_fraction) * n_samples)
n_outliers = int(outliers_fraction * n_samples)
X = 0.3 * rng.randn(n_inliers // 2, 2)
X_train = np.r_[X + 2, X - 2] #正常样本
X_train = np.r_[X_train, np.random.uniform(low=-6, high=6, size=(n_outliers, 2))] #正常样本加上异常样本
# fit the model
clf = IsolationForest(max_samples=n_samples, random_state=rng, contamination=outliers_fraction)
clf.fit(X_train)
# y_pred_train = clf.predict(X_train)
scores_pred = clf.decision_function(X_train)
threshold = stats.scoreatpercentile(scores_pred, 100 * outliers_fraction) #根据训练样本中异常样本比例,得到阈值,用于绘图
# plot the line, the samples, and the nearest vectors to the plane
xx, yy = np.meshgrid(np.linspace(-7, 7, 50), np.linspace(-7, 7, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("IsolationForest")
# plt.contourf(xx, yy, Z, cmap=plt.cm.Blues_r)
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), threshold, 7), cmap=plt.cm.Blues_r) #绘制异常点区域,值从最小的到阈值的那部分
a = plt.contour(xx, yy, Z, levels=[threshold], linewidths=2, colors='red') #绘制异常点区域和正常点区域的边界
plt.contourf(xx, yy, Z, levels=[threshold, Z.max()], colors='palevioletred') #绘制正常点区域,值从阈值到最大的那部分
b = plt.scatter(X_train[:-n_outliers, 0], X_train[:-n_outliers, 1], c='white',
s=20, edgecolor='k')
c = plt.scatter(X_train[-n_outliers:, 0], X_train[-n_outliers:, 1], c='black',
s=20, edgecolor='k')
plt.axis('tight')
plt.xlim((-7, 7))
plt.ylim((-7, 7))
plt.legend([a.collections[0], b, c],
['learned decision function', 'true inliers', 'true outliers'],
loc="upper left")
plt.show()

- 机器学习-异常检测算法(一):Isolation Forest
- Python机器学习笔记 异常点检测算法——Isolation Forest
- 使用IsolationForest 与Meanshift算法进行异常检测
- 白话异常检测算法Isolation Forest
- 异常检测算法--isolation forest
- 机器学习笔记(7)---K-近邻算法(5)---使用K近邻算法检测异常操作之二
- 【机器学习】异常检测算法(I)
- 机器学习笔记(6)---K-近邻算法(4)---使用K近邻算法检测异常操作之一
- 机器学习----无监督学习算法之异常检测
- 【异常检测】Isolation forest 的spark 分布式实现
- 斯坦福大学机器学习笔记——异常检测算法(高斯分布、多元高斯分布、异常检测算法)
- 斯坦福机器学习公开课笔记(十二)--异常检测
- 机器学习(八):AnomalyDetection异常检测_Python
- DAY 42 机器学习-风控-离群点检测(异常检测)
- Stanford机器学习---第十一讲.异常检测
- Coursera-吴恩达-机器学习-(第9周笔记)异常检测和推荐系统
- 霍夫森林(Hough Forest)目标检测算法
- 吴恩达机器学习笔记(十四)异常检测