Coursera-吴恩达-机器学习-(第9周笔记)异常检测和推荐系统
2018-01-16 18:24
579 查看
此系列为 Coursera 网站Andrew Ng机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
目录
一异常检测
1-1 问题引入
1-2 高斯分布正态分布
1-3 异常检测算法
二 建立一个异常检测系统
2-1 评价一个异常检测系统
2-2 异常检测 vs 监督学习
2-3 选择使用哪些特征 features
三 多元高斯分布
3-1多元高斯分布数学
3-2 多元正态分布的特点
3-3 应用多元高斯分布进行异常检测
推荐系统
四 预测电影等级
4-1 任务设想
4-2 基于内容的推荐
五 协同滤波
5-1 协同滤波
5-2 协同滤波算法
六 低秩矩阵分解
6-1向量化低秩矩阵分解Low Rank Matrix Factorization
6-2 实现细节
为了解释这个概念 ,让我举一个例子吧: 假想你是一个 飞机引擎制造商, 当你生产的飞机引擎 从生产线上流出时 你需要进行 QA (质量控制测试), 而作为这个测试的一部分 你测量了飞机引擎的一些特征变量 ,比如 你可能测量了 引擎运转时产生的热量, 或者引擎的振动等等 。采集这些特征变量 这样一来 你就有了一个数据集 ,从x(1)到x(m), 如果你生产了m个引擎的话 也许你会将这些数据绘制成图表。
后来有一天 ,你有一个新的飞机引擎 从生产线上流出,而你的新飞机引擎 有特征变量x-test 。所谓的异常检测问题就是 我们希望知道, 这个新的飞机引擎是否有某种异常。
感性来理解一下,如图:

这些样本点 有很大的概率值 落在 在中心区域。
而稍微远离中心区域的点概率会小一些 ,
更远的地方的点 它们的概率将更小, 这外面的点 和这外面的点 将成为异常点 。
而这些圈是可以用一个概率模型P(x)来衡量的,我们的异常检测算法就是找到这样一个概率模型画出这个圈。
异常检测算法有很多用途,比如:
欺诈检测:把用户的使用习惯设为特征,若很反常有可能为欺诈。
制造业:产品的质量控制(QA)。
数据中心的计算监控:监控cpu、内存等的使用情况是否又反常。
入侵检测:检测入侵计算机系统的行为
医疗领域:检测人的健康是否异常
所谓样本x服从高斯分布(x~N),就是x出现的概率(或者说发生x事件的概率)满足这样一个公式:
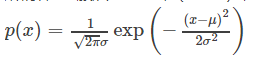
所以这是一个概率公式。他的图像如下:以均值为中心,方差为宽度。

其中均值与方差的计算方法如下:
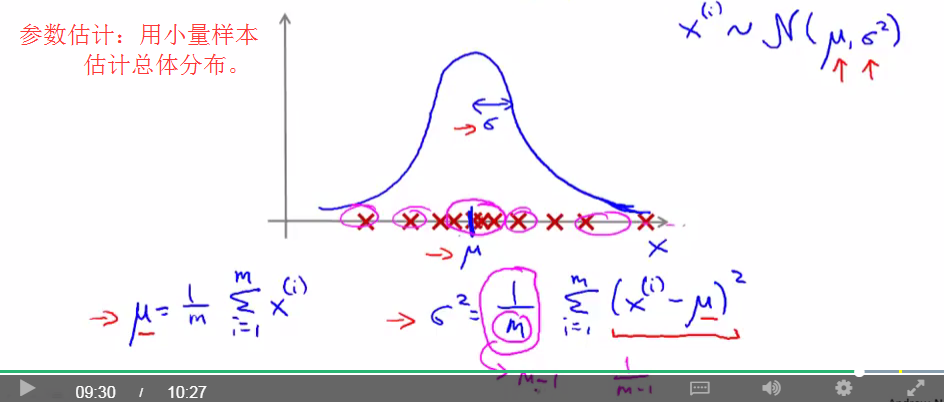
有了均值与方差的计算方法,就有了参数估计这一名词。就是:给你了一些样本值,你可以求出他们的均值与方差,然后用这两个参数估计总体样本的分布。
第二个比较重要的数学知识就是独立分布的概率,等于概率的乘积。


下面通过图像直观感受:
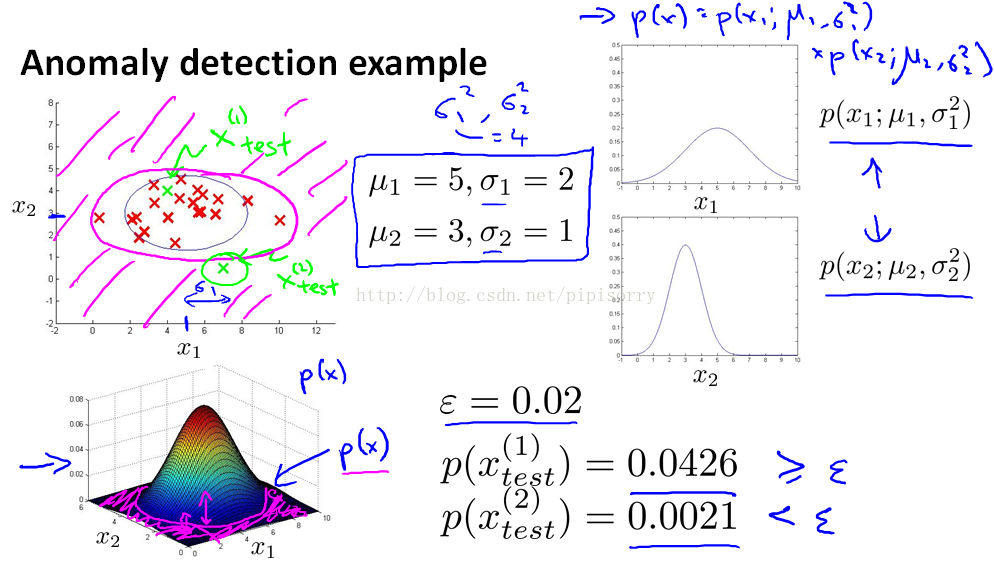
1.左上角为样本点,有X1和X2两个特征。
2.计算分别计算X1和X2的均值和方差。图像如右上角,综合两者的图像为三维左下角,高度为概率。
3.给定2个样本Xtest,计算出现的概率,大于阈值为正常,小于这么小的阈值为异常。
总结:异常检验的数学内涵是数理统的一条法则:小概率事件一般不会发生。
翻译成通俗解释就是:不可能发生的事情却发生了,必有阴谋!所以判断其为异常值,事后专门对其进行检查。

对于异常检测问题,要检测出的是anomalous的,所以anomalous对应y = 1,我们举个例子,对与飞机发动机故障检测,将10000个好数据分为三部分,20个故障数据分成2部分,如图:

其中第二种方式,把CV与test数据弄的一样,吴恩达老师不鼓励这样。
下面总结一下步骤:

对训练数据进行寻找估计模型。P(X)
使用交叉验证和test数据集预测0和1.
使用召回率和置信度计算F1值评价算法。(为啥不用精度?因为:这是个不均衡数据skewed,前面讲过不能使用classification accuracy。)
设置epsilon,在交叉验证集上评估算法,然后当我们选择了特征集时,找到epsilon的值,对测试集上的算法进行最终评估。
这就引出了这样一个问题: 我们有了这些带标签的数据 我们有了一些样本 其中一些我们知道是异常的 另外一些是正常的 那我们为什么我们不 直接用监督学习的方法呢?

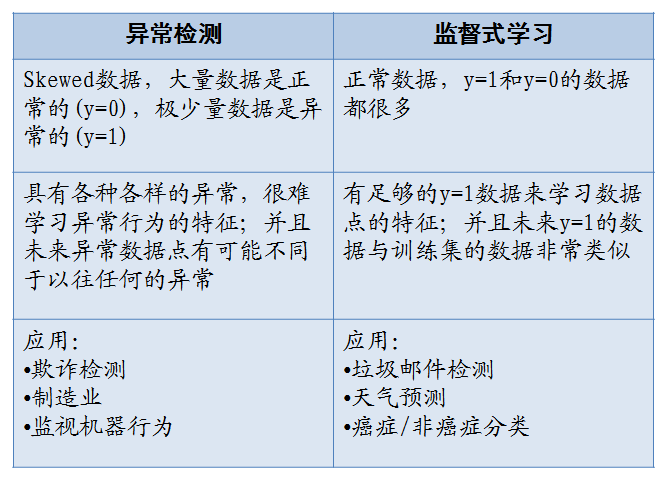
ppt已经写得很清楚了,在总结一下:关键的区别就是 :在异常检测算法中 我们只有一小撮 正样本 因此学习算法不可能 从这些正样本中学出太多东西 。

下一页ppt给出了两种算法的一般使用场景:
参数修改
在我们的异常检测算法中我们做的事情之一就是使用这种正态(高斯)分布来对特征向量建模,但是有些数据并不太符合高斯分布,虽然算法也常常可以正常运行,但效果不好,可以用这种数学方法:
进行数据的不同转换,以使其看起来更加高斯。比如:用 x1 的对数 log(x1) 来替换掉 x1,或者平方根来取代 x3。

2.误差分析
像之前讲监督学习的误差分析一样, 我们先完整地训练出 一个学习算法, 然后在一组交叉验证集上运行算法 ;然后找出那些预测出错的样本, 然后再看看 我们能否找到一些其他的特征变量 来帮助学习算法, 让它在那些交叉验证时 判断出错的样本中表现更好 。
比如下图:绿色x代表anomaly example, 只有一个feature x1时会区分错误,加一个feature x2时就可以正确区分。


那么普通的高斯分布建模就是粉红色的圆圈,多元高斯分布建模就是蓝色的“斜”椭圆。(其知识为多元正态分布的相关性,其实普通正态分布就是多元正态分布的特例——特征独立不相关。)

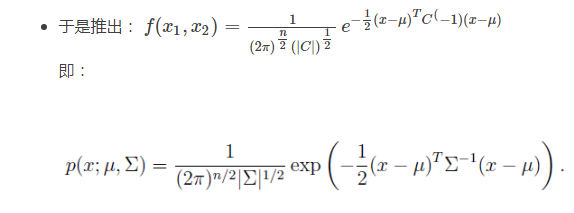
其中:
- μ 相当于每个正态分布的对称轴,是一个一维向量
- Σ是协方差矩阵
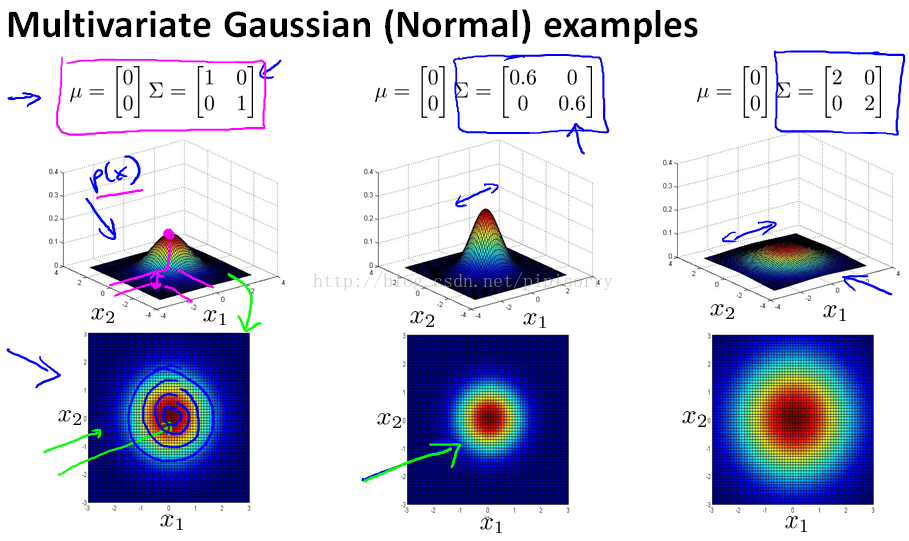
协方差改变,特征相关,变成椭圆

正相关(右上-左下)

负相关(左上-右下)
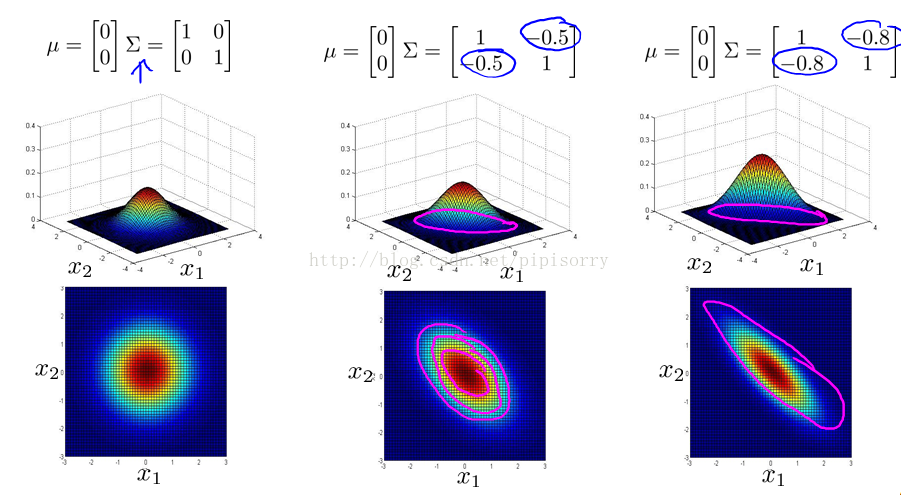
步骤如下:

传统高斯分布与多元高斯分布的关系:当多元高斯分布的协方差为对角矩阵的时候就是传统高斯分布。
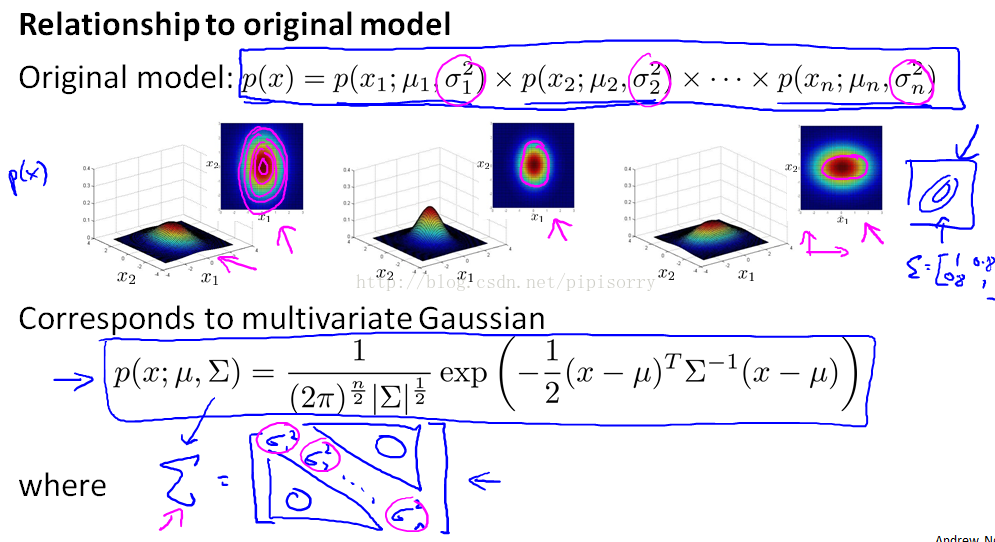
具体区别对比:


对于机器学习来说 特征量是重要的, 你选择的特征 对你学习算法的表现有很大影响。 在机器学习领域 有这么一个宏大的想法, 就是对于一些问题 存在一些算法, 能试图自动地替你学习到一组优良的特征量。
而推荐系统 就是这种情形的一个例子。还有其他很多例子 但通过学习推荐系统 ,我们将能够 对这种学习特征量的想法 有一点理解。
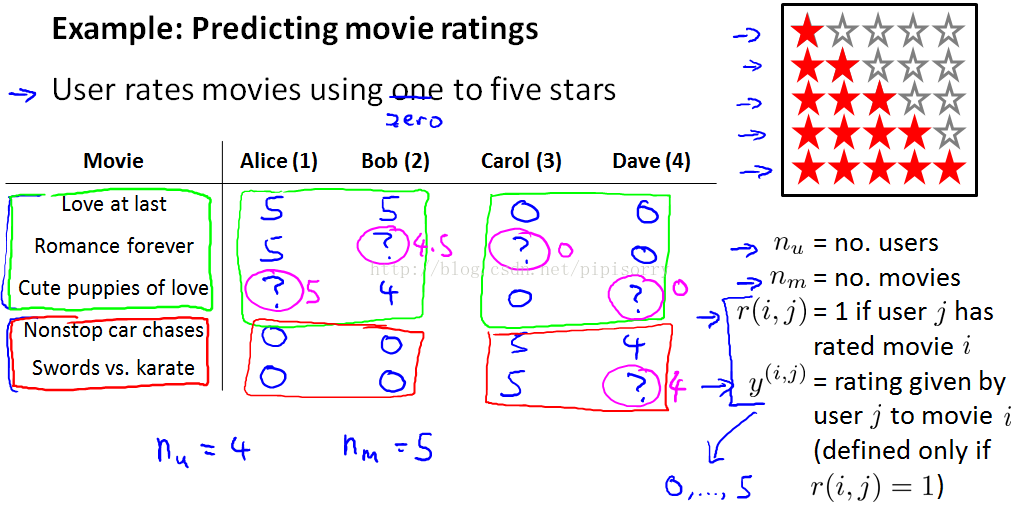
我这里有5部电影 《爱到最后》 《浪漫永远》 《小爱犬》 《无尽狂飙》 还有 《剑与空手道》。 我们有4位用户 名叫 Alice Bob Carol 和 Dave 。首字母为A B C和D 我们称他们用户1 2 3和4 。比方说 ,Alice 她非常喜欢 《爱到最后》 把它评为5颗星。 她还喜欢 《浪漫永远》 也把它评为5颗星。 她没看过 《小爱犬》 也就没评分, 这样我们没有这个评分数据。
我们查看数据并查看所有缺失的电影评级,并试图预测这些问号的值应该是多少。

使用梯度下降优化:

如果你觉得这个 梯度下降的更新 看起来跟之前 线性回归差不多的话, 那是因为这其实就是线性回归, 唯一的一点区别 是在线性回归中 我们有1/m项 。
通过这节课 你应该知道了 怎样应用一种 事实上是线性回归的一个变体, 来预测不同用户对不同电影的评分值 ,这种具体的算法叫 ”基于内容的推荐“ 或者”基于内容的方法“。 因为我们假设 我们有不同电影的特征 ,我们有了电影 内容的特征 比如电影的爱情成分有多少?动作成分有多少? 我们就是用电影的这些特征 来进行预测 。
但事实上 对很多电影 我们并没有这些特征 或者说 很难得到 所有电影的特征 很难知道 我们要卖的产品 有什么样的特征 。所以在下一段视频中 我们将谈到一种不基于内容的推荐系统:协同过滤。
算法 有一个值得一提的 特点 ,那就是它能实现 对特征的学习。 我的意思是 这种算法能够 自行学习所要使用的特征 。
我们建一个数据集 ,假定是为每一部电影准备的 ,对每一部电影 我们找一些人来 告诉我们这部电影 浪漫指数是多少 动作指数是多少。
但想一下就知道 这样做难度很大, 也很花费时间 。你想想 要让每个人 看完每一部电影 告诉你你每一部电影有多浪漫 多动作 这是一件不容易的事情。
现在我们稍稍改变一下这个假设 ,假设我们采访了每一位用户 而且每一位用户都告诉我们 他们是否喜欢 爱情电影。
总结一下, 这一阶段要做的 就是为所有 为电影评分的 用户 j 选择特征 x(i)。 这一算法同样也预测出一个值 ,表示该用户将会如何评价某部电影。 而这个预测值 在平方误差的形式中 与用户对该电影评分的实际值尽量接近 。
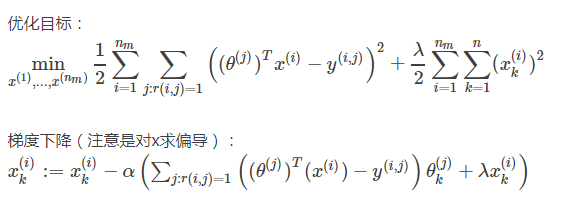
我们之前 这个视频中讲的是 ,如果用户愿意 为你提供参数 ,那么你就可以为不同的电影估计特征 。
这有点像鸡和蛋的问题 到底先有鸡还是先有蛋?就是说 如果我们能知道 θ 就能学习到 x ,如果我们知道 x 也会学出 θ 来 。
我们可以一开始随机 猜测出的 θ 的值, 你可以继续下去 运用我们刚刚讲到的 步骤 我们可以学习出 不同电影的特征 。
同样的给出已有的一些电影的 原始特征, 你可以运用 我们在上一个视频中讨论过的 第一种方法 ,可以得到 对参数 θ 的更好估计 ,这样就会为用户提供更好的参数 θ 集。
我们可以继续 迭代 不停重复 优化θ x θ x θ 这非常有效
本节视频中 我们将会使用这些概念 并且将它们合并成 协同过滤算法 (Collaborative Filtering Algorithm) 。
总结一下我们之前做过的事情 :其中之一是, 假如你有了电影的特征 ,你就可以解出 这个最小化问题 ,为你的用户找到参数 θ 。然后我们也 知道了, 如果你拥有参数 θ, 你也可以用该参数 通过解一个最小化问题 去计算出特征 x 。
所以你可以做的事 是不停地重复这些计算 ,首先随机地初始化这些参数 ,然后解出 θ 解出 x 解出 θ 解出 x ….但我将它们给合在一起

然后同时计算两个的梯度:


现在既然你已经 对特征参数向量进行了学习 ,那么我们就会有一个很方便的方法 来度量两部电影之间的相似性。 例如说 ,电影i有一个特征向量x(i), 你是否能找到一部 不同的电影 j,保证两部电影的特征向量之间的距离x(i)和x(j)很小 ,那就能 很有力地表明 电影 i 和电影 j在某种程度上有相似。
就是计算 small ||x(i)−x(j)||
所有item减去其(所有用户给它的)打分均值(没有评分的user_item不计入均值的计算),参数推断完成后再加回来。

如果电影没有评分,就将列和均值设置为0;如果用户没有评分,就将行均值设置为0。
否则新用户评分为0,则为负样例。
课程网址:https://www.coursera.org/learn/machine-learning
Week 9 ——Anomaly Detection & Recommender Systems
目录
Week 9 Anomaly Detection Recommender Systems目录
一异常检测
1-1 问题引入
1-2 高斯分布正态分布
1-3 异常检测算法
二 建立一个异常检测系统
2-1 评价一个异常检测系统
2-2 异常检测 vs 监督学习
2-3 选择使用哪些特征 features
三 多元高斯分布
3-1多元高斯分布数学
3-2 多元正态分布的特点
3-3 应用多元高斯分布进行异常检测
推荐系统
四 预测电影等级
4-1 任务设想
4-2 基于内容的推荐
五 协同滤波
5-1 协同滤波
5-2 协同滤波算法
六 低秩矩阵分解
6-1向量化低秩矩阵分解Low Rank Matrix Factorization
6-2 实现细节
一异常检测
异常检测(Anomaly detection)问题 是机器学习算法 的一个常见应用, 这种算法的一个有趣之处在于 :它虽然主要用于 非监督学习问题 ,但从某些角度看 它又类似于一些监督学习问题 。1-1 问题引入
那么 什么是异常检测呢?为了解释这个概念 ,让我举一个例子吧: 假想你是一个 飞机引擎制造商, 当你生产的飞机引擎 从生产线上流出时 你需要进行 QA (质量控制测试), 而作为这个测试的一部分 你测量了飞机引擎的一些特征变量 ,比如 你可能测量了 引擎运转时产生的热量, 或者引擎的振动等等 。采集这些特征变量 这样一来 你就有了一个数据集 ,从x(1)到x(m), 如果你生产了m个引擎的话 也许你会将这些数据绘制成图表。
后来有一天 ,你有一个新的飞机引擎 从生产线上流出,而你的新飞机引擎 有特征变量x-test 。所谓的异常检测问题就是 我们希望知道, 这个新的飞机引擎是否有某种异常。
感性来理解一下,如图:
这些样本点 有很大的概率值 落在 在中心区域。
而稍微远离中心区域的点概率会小一些 ,
更远的地方的点 它们的概率将更小, 这外面的点 和这外面的点 将成为异常点 。
而这些圈是可以用一个概率模型P(x)来衡量的,我们的异常检测算法就是找到这样一个概率模型画出这个圈。
异常检测算法有很多用途,比如:
欺诈检测:把用户的使用习惯设为特征,若很反常有可能为欺诈。
制造业:产品的质量控制(QA)。
数据中心的计算监控:监控cpu、内存等的使用情况是否又反常。
入侵检测:检测入侵计算机系统的行为
医疗领域:检测人的健康是否异常
1-2 高斯分布(正态分布)
异常检测的数学基础:高斯(正态)分布。是数理统计中的知识,话说线性代数与数理统计这两门课真的是有用啊。所谓样本x服从高斯分布(x~N),就是x出现的概率(或者说发生x事件的概率)满足这样一个公式:
所以这是一个概率公式。他的图像如下:以均值为中心,方差为宽度。
其中均值与方差的计算方法如下:
有了均值与方差的计算方法,就有了参数估计这一名词。就是:给你了一些样本值,你可以求出他们的均值与方差,然后用这两个参数估计总体样本的分布。
第二个比较重要的数学知识就是独立分布的概率,等于概率的乘积。
1-3 异常检测算法
下面通过图像直观感受:
1.左上角为样本点,有X1和X2两个特征。
2.计算分别计算X1和X2的均值和方差。图像如右上角,综合两者的图像为三维左下角,高度为概率。
3.给定2个样本Xtest,计算出现的概率,大于阈值为正常,小于这么小的阈值为异常。
总结:异常检验的数学内涵是数理统的一条法则:小概率事件一般不会发生。
翻译成通俗解释就是:不可能发生的事情却发生了,必有阴谋!所以判断其为异常值,事后专门对其进行检查。
二 建立一个异常检测系统
在上一段视频中 我们推导了异常检测算法, 在这段视频中, 我想介绍一下 如何开发一个 关于异常检测的应用 ,来解决一个实际问题 。2-1 评价一个异常检测系统
评价异常检测系统最常用的方法就是使用 cross validation(与监督学习一样):将训练数据分为三部分:Training set is unlabled, cross validation & test set is labled.如图:对于异常检测问题,要检测出的是anomalous的,所以anomalous对应y = 1,我们举个例子,对与飞机发动机故障检测,将10000个好数据分为三部分,20个故障数据分成2部分,如图:
其中第二种方式,把CV与test数据弄的一样,吴恩达老师不鼓励这样。
下面总结一下步骤:
对训练数据进行寻找估计模型。P(X)
使用交叉验证和test数据集预测0和1.
使用召回率和置信度计算F1值评价算法。(为啥不用精度?因为:这是个不均衡数据skewed,前面讲过不能使用classification accuracy。)
设置epsilon,在交叉验证集上评估算法,然后当我们选择了特征集时,找到epsilon的值,对测试集上的算法进行最终评估。
2-2 异常检测 vs 监督学习
在上一段视频中 ,我们谈到 如何评价一个 异常检测算法 ,我们先是用了一些 带标签的数据 ,以及一些我们知道是异常 或者正常的样本 用 y=1 或 y=0 来表示 。这就引出了这样一个问题: 我们有了这些带标签的数据 我们有了一些样本 其中一些我们知道是异常的 另外一些是正常的 那我们为什么我们不 直接用监督学习的方法呢?
ppt已经写得很清楚了,在总结一下:关键的区别就是 :在异常检测算法中 我们只有一小撮 正样本 因此学习算法不可能 从这些正样本中学出太多东西 。
下一页ppt给出了两种算法的一般使用场景:
2-3 选择使用哪些特征 features
在此之前 我们讨论了如何 评估一个异常检测算法 。事实上 当你应用异常检测时 对它的效率 影响最大的 因素之一是 你使用什么特征变量 。两种方法:参数修改
在我们的异常检测算法中我们做的事情之一就是使用这种正态(高斯)分布来对特征向量建模,但是有些数据并不太符合高斯分布,虽然算法也常常可以正常运行,但效果不好,可以用这种数学方法:
进行数据的不同转换,以使其看起来更加高斯。比如:用 x1 的对数 log(x1) 来替换掉 x1,或者平方根来取代 x3。
2.误差分析
像之前讲监督学习的误差分析一样, 我们先完整地训练出 一个学习算法, 然后在一组交叉验证集上运行算法 ;然后找出那些预测出错的样本, 然后再看看 我们能否找到一些其他的特征变量 来帮助学习算法, 让它在那些交叉验证时 判断出错的样本中表现更好 。
比如下图:绿色x代表anomaly example, 只有一个feature x1时会区分错误,加一个feature x2时就可以正确区分。
三 多元高斯分布
异常检测算法的 一种可能的延伸 —— 多元高斯分布 (multivariate Gaussian distribution) 。它有一些劣势(计算量大),也有一些优势( 它能捕捉到一些之前的算法检测不出来的异常)。3-1多元高斯分布数学
我们先来看看一个例子: 假设我们的没有标签的数据看起来像这张图一样。 ,我要使用数据中心的监控机的例子 ,我的两个特征变量 x1 是 CPU 的负载和 x2 可能是内存使用量 。那么普通的高斯分布建模就是粉红色的圆圈,多元高斯分布建模就是蓝色的“斜”椭圆。(其知识为多元正态分布的相关性,其实普通正态分布就是多元正态分布的特例——特征独立不相关。)
其中:
- μ 相当于每个正态分布的对称轴,是一个一维向量
- Σ是协方差矩阵
3-2 多元正态分布的特点
协方差相同,说明特征独立,与普通高斯分布相同协方差改变,特征相关,变成椭圆
正相关(右上-左下)
负相关(左上-右下)
3-3 应用多元高斯分布进行异常检测
之前看到了一些例子, 通过改变参数 µ 和 Σ 来给不同的概率分布建模。 在这节视频中 ,我们来使用那些想法 ,用它们来开发另一种异常检测算法 。步骤如下:
传统高斯分布与多元高斯分布的关系:当多元高斯分布的协方差为对角矩阵的时候就是传统高斯分布。
具体区别对比:
推荐系统
四 预测电影等级
推荐系统(recommender systems),比如对像 Netflix 这样的公司 ,他们向用户推荐的电影 占了用户观看的电影的 相当大一部分 。对于机器学习来说 特征量是重要的, 你选择的特征 对你学习算法的表现有很大影响。 在机器学习领域 有这么一个宏大的想法, 就是对于一些问题 存在一些算法, 能试图自动地替你学习到一组优良的特征量。
而推荐系统 就是这种情形的一个例子。还有其他很多例子 但通过学习推荐系统 ,我们将能够 对这种学习特征量的想法 有一点理解。
4-1 任务设想
我这里有5部电影 《爱到最后》 《浪漫永远》 《小爱犬》 《无尽狂飙》 还有 《剑与空手道》。 我们有4位用户 名叫 Alice Bob Carol 和 Dave 。首字母为A B C和D 我们称他们用户1 2 3和4 。比方说 ,Alice 她非常喜欢 《爱到最后》 把它评为5颗星。 她还喜欢 《浪漫永远》 也把它评为5颗星。 她没看过 《小爱犬》 也就没评分, 这样我们没有这个评分数据。
我们查看数据并查看所有缺失的电影评级,并试图预测这些问号的值应该是多少。
4-2 基于内容的推荐
每个items都有一些features,如果我们知道它们的值是多少,同时每个用户通过θj告诉我们他们有多喜欢romantic或者action movies。这种按照内容的特征来推荐的算法就是——基于内容推荐。使用梯度下降优化:
如果你觉得这个 梯度下降的更新 看起来跟之前 线性回归差不多的话, 那是因为这其实就是线性回归, 唯一的一点区别 是在线性回归中 我们有1/m项 。
通过这节课 你应该知道了 怎样应用一种 事实上是线性回归的一个变体, 来预测不同用户对不同电影的评分值 ,这种具体的算法叫 ”基于内容的推荐“ 或者”基于内容的方法“。 因为我们假设 我们有不同电影的特征 ,我们有了电影 内容的特征 比如电影的爱情成分有多少?动作成分有多少? 我们就是用电影的这些特征 来进行预测 。
但事实上 对很多电影 我们并没有这些特征 或者说 很难得到 所有电影的特征 很难知道 我们要卖的产品 有什么样的特征 。所以在下一段视频中 我们将谈到一种不基于内容的推荐系统:协同过滤。
五 协同滤波
5-1 协同滤波
在这段视频中 我们要讲 一种构建推荐系统的方法 叫做协同过滤(collaborative filtering) 。算法 有一个值得一提的 特点 ,那就是它能实现 对特征的学习。 我的意思是 这种算法能够 自行学习所要使用的特征 。
我们建一个数据集 ,假定是为每一部电影准备的 ,对每一部电影 我们找一些人来 告诉我们这部电影 浪漫指数是多少 动作指数是多少。
但想一下就知道 这样做难度很大, 也很花费时间 。你想想 要让每个人 看完每一部电影 告诉你你每一部电影有多浪漫 多动作 这是一件不容易的事情。
现在我们稍稍改变一下这个假设 ,假设我们采访了每一位用户 而且每一位用户都告诉我们 他们是否喜欢 爱情电影。
总结一下, 这一阶段要做的 就是为所有 为电影评分的 用户 j 选择特征 x(i)。 这一算法同样也预测出一个值 ,表示该用户将会如何评价某部电影。 而这个预测值 在平方误差的形式中 与用户对该电影评分的实际值尽量接近 。
我们之前 这个视频中讲的是 ,如果用户愿意 为你提供参数 ,那么你就可以为不同的电影估计特征 。
这有点像鸡和蛋的问题 到底先有鸡还是先有蛋?就是说 如果我们能知道 θ 就能学习到 x ,如果我们知道 x 也会学出 θ 来 。
我们可以一开始随机 猜测出的 θ 的值, 你可以继续下去 运用我们刚刚讲到的 步骤 我们可以学习出 不同电影的特征 。
同样的给出已有的一些电影的 原始特征, 你可以运用 我们在上一个视频中讨论过的 第一种方法 ,可以得到 对参数 θ 的更好估计 ,这样就会为用户提供更好的参数 θ 集。
我们可以继续 迭代 不停重复 优化θ x θ x θ 这非常有效
5-2 协同滤波算法
在前面几个视频里 我们谈到几个概念 ,首先 ,如果给你几个特征表示电影, 我们可以使用这些资料去获得用户的参数数据。 第二 ,如果给你用户的参数数据, 你可以使用这些资料去获得电影的特征。本节视频中 我们将会使用这些概念 并且将它们合并成 协同过滤算法 (Collaborative Filtering Algorithm) 。
总结一下我们之前做过的事情 :其中之一是, 假如你有了电影的特征 ,你就可以解出 这个最小化问题 ,为你的用户找到参数 θ 。然后我们也 知道了, 如果你拥有参数 θ, 你也可以用该参数 通过解一个最小化问题 去计算出特征 x 。
所以你可以做的事 是不停地重复这些计算 ,首先随机地初始化这些参数 ,然后解出 θ 解出 x 解出 θ 解出 x ….但我将它们给合在一起
然后同时计算两个的梯度:
六 低秩矩阵分解
在上几节视频中 我们谈到了协同过滤算法 ,本节视频中我将会 讲到有关 该算法的向量化实现。6-1向量化:低秩矩阵分解Low Rank Matrix Factorization
如果你有 预测评分矩阵 ,你就会有 以下的这个 有着(i, j)位置数据的矩阵 。现在既然你已经 对特征参数向量进行了学习 ,那么我们就会有一个很方便的方法 来度量两部电影之间的相似性。 例如说 ,电影i有一个特征向量x(i), 你是否能找到一部 不同的电影 j,保证两部电影的特征向量之间的距离x(i)和x(j)很小 ,那就能 很有力地表明 电影 i 和电影 j在某种程度上有相似。
就是计算 small ||x(i)−x(j)||
6-2 实现细节
到目前为止 你已经了解到了 推荐系统算法或者 协同过滤算法的所有要点 。在这节视频中 我想分享最后一点实现过程中的细节 ,这一点就是均值归一化 有时它可以让算法 运行得更好 。所有item减去其(所有用户给它的)打分均值(没有评分的user_item不计入均值的计算),参数推断完成后再加回来。
如果电影没有评分,就将列和均值设置为0;如果用户没有评分,就将行均值设置为0。
否则新用户评分为0,则为负样例。

相关文章推荐
- Coursera-吴恩达-机器学习-(编程练习8)异常检测和推荐系统(对应第9周课程)
- coursera-斯坦福-机器学习-吴恩达-第9周笔记(上)-异常检测
- coursera-斯坦福-机器学习-吴恩达-第9周笔记(下)-推荐系统
- 斯坦福大学(吴恩达) 机器学习课后习题详解 第九周 编程题 异常检测与推荐系统
- Andrew NG 机器学习 笔记-week9-异常检测和推荐系统(Anomaly Detection and Recommender Systems)
- 机器学习公开课笔记(9):异常检测和推荐系统
- coursera-斯坦福-机器学习-吴恩达-第11周笔记-ORC系统
- Coursera机器学习(Andrew Ng)笔记:异常检测与推荐系统
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 9(二)——推荐系统作业
- Machine Learning第九周笔记:异常检测与推荐系统
- 异常检测与推荐系统 机器学习基础(8)
- Coursera 《Machine Learning》 编程作业8:异常检测与推荐系统
- 课程笔记|吴恩达Coursera机器学习 Week1 笔记-机器学习基础
- 机器学习入门笔记(十)----异常检测
- coursera-斯坦福-机器学习-吴恩达-第7周笔记-支持向量机SVM
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第6周有关机器学习的小建议
- 斯坦福机器学习公开课笔记(十二)--异常检测
- coursera-斯坦福-机器学习-吴恩达-第4周笔记-神经网络
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-2)-- 机器学习策略(2)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-2)-- 机器学习策略(2)(转)