爬虫!教你用python里的json分分钟爬取腾讯招聘动态网站求职信息!(结构化数据)

首先解释一下为什么要导入json跟time模块,打开腾讯招聘网
右键检查点击elements里面的网页元素
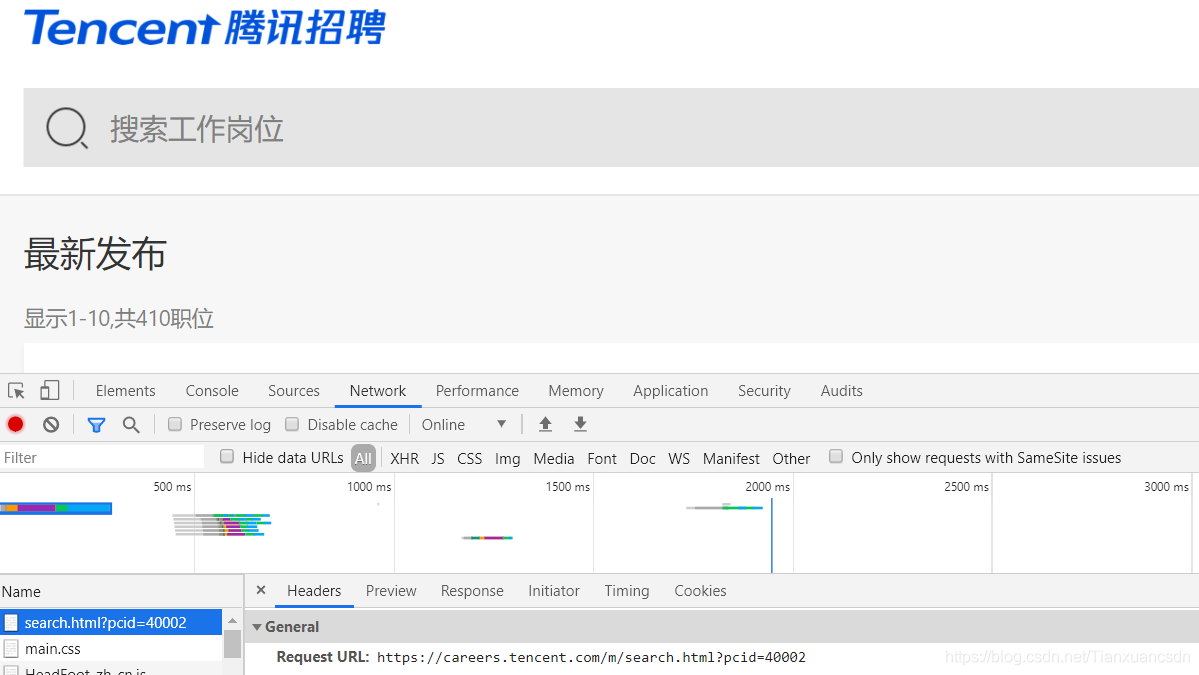
来到network里面你会发现当前链接response里面并没有我们想要的数据信息

那么我们开始思考,这会不会是一个动态网页链接
接下来我们点击"XHR"
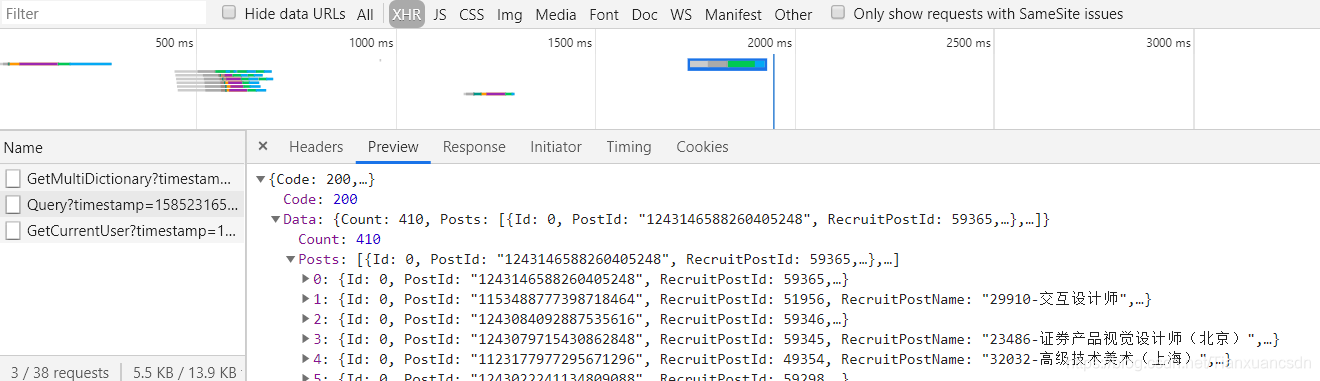
接下来我们就观察这个可以拿到有效信息的url!
有效的url
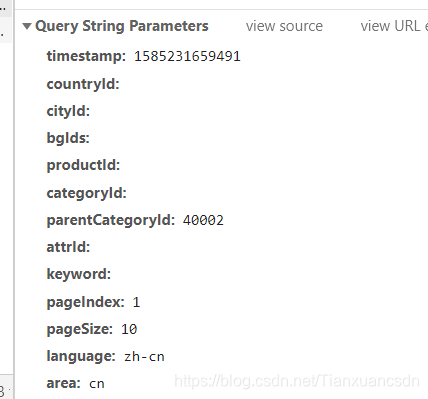
我们经过观察发现,该url里面的有效参数有一个timestamp
再一看,我们就发现它是十三位置也就到了毫秒
博主也特意去查了资料
(所谓的时间戳也就是从1970-01-01 00:00:00到现在的时间,如果是十位就是到秒,如果是十三位也就是毫秒)
经过博主的测试,这个十三位数的timestemp就是我们所说的时间戳
以下就是检测是否为时间戳的代码:
**#把时间戳转化为当前时间
# timestemp = 1585231659491#(这里博主给的时间戳可换为你自己电脑该url显示的)
# timearry = time.localtime(float(timestemp)/1000)
# time = time.strftime('%Y-%m-%d %H:%M:%S',timearry)
# print(time)**
我们也可以进一步测试将当前时间进行一个测试
#把当前时间转化为时间戳(time.time()就可以拿到时间戳)
# timestemp = int(time.time())*1000
#重复上面的将时间戳转化为标准化操作
# timearry = time.localtime(float(timestemp)/1000)
# time = time.strftime('%Y-%m-%d %H:%M:%S',timearry)
# print(time)
说了这么多,其实就是一句话
time.time()可以拿到当前时间戳,帮助我们构建url,发送请求
所以要导入时间模块,动态结构化爬虫,所以导入json模块
分析完成,接下来,我们就可以写代码了!
**base_url = "https://careers.tencent.com/tencentcareer/api/post/Query?timestamp={}&parentCategoryId=40002&pageIndex={}&pageSize=10&language=zh-cn&area=cn"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"
}**
#构造分页链接,以及完成url的拼接
**def get_page():
url_list = []
for i in range(10):
url = base_url.format(int(time.time())*1000,i+1)
url_list.append(url)
# print(url_list)
return url_list**

下面我们着重讲解以上代码
涉及到的唯一一个复杂方法就是json,我们完全可以认为
通过json.loads()这样一个方法就将以上结构化是代码转换成了我们非常熟悉的python的对象{}、以及[ ]
(仔细想想是不是跟我们用正则表达式以及pyquery、BeaytifulSoup、XPath等方法爬取非结构化数据很像呢)
**def run(url_list):
url__list = []
for url in url_list:
# print(url)
#发送请求
response = requests.get(url=url,headers=headers)
response = response.content.decode('utf-8')
# print(response)
# # print(result['Data']['Posts'][3]['RecruitPostName'])
#通过json.loads()这样一个方法就将以上结构化是代码转换成了python里的字典、列表
result = json.loads(response)
# print(result['Data']['Posts'])
#通过对“字典”的两次操作,我们拿到了一个个含有有效信息的列表
lists = result['Data']['Posts']**
接下来就是通过for循环在该列表里进行拿取我们想要的信息
***for value in lists: # print(value) #拿地址标签 get_location = value['LocationName'] # print(get_location) #拿职位标签 get_name = value['RecruitPostName'] # print(get_name) #最后更新的时间 get_time = value['LastUpdateTime'] # print(get_time) #需具备的能力 get_responsibility = value['Responsibility'] # print(get_responsibility)***
最后,拼接我们想要的信息,并通过for循环写入文件,为了方便
博主直接存储在了当前文件夹下,存储格式为.doc/txt
(当然,我们也可以存储为csv格式,或者数据库)
简单来说,存储为csv文件只需要导入一个csv模块并且在with后面括号加上newline="",以及encoding=utf-8后面加上-sig,然后创建一个write=csv.writerow()
write(“str”)
而存储到数据库也较为简单,只简述步骤,后面有机会会写到:
1.通过pymysq里的connect方法来连接数据库
2.写sql语句
3.创建游标:cursor
4.通过cursor.execute(sql)操作数据库
5.提交事务:coon.commit()
6.关闭游标
7.关闭数据库
str = get_time+"\n"+get_name+"\n"+get_responsibility+"\n"
url__list.append(str)
for i in url__list:
with open(".\腾讯招聘_设计类.doc","a",encoding="utf-8") as f:
f.write(i+"\n")
方法封装完成,最后进行调用
(当然,你完全可以用类进行封装与写入,思路会更加清晰)

大功告成

爬虫!教你用python里的json分分钟爬取腾讯招聘动态网站求职信息!(结构化数据)
**@author:天玄 @time:2020.03.26** (注:版权所有,转发请注明作者)

- python爬虫小项目--抓取腾讯招聘岗位信息
- Python爬虫(爬取招聘网站信息)
- python爬虫使用selenium爬取动态网页信息——以智联招聘网站为例
- Python爬虫——4.4爬虫案例——requests和xpath爬取招聘网站信息
- python爬虫实战-爬取岗位招聘信息并保存至本地(方法、jsonpath)
- python爬虫3——爬取腾讯招聘全部招聘信息
- python-腾讯,优酷,爱奇艺,土豆,等网站视频信息查询api接口爬虫
- python爬虫2——beautifusoap4的使用讲解与腾讯招聘网站爬虫
- python爬虫--scrapy爬取腾讯招聘网站
- python爬虫(8)——Xpath的应用实例:爬取腾讯招聘信息
- python爬虫---多线程爬取腾讯招聘信息【简单版】
- python爬虫----单线程爬取腾讯招聘内容【简单版】
- Python爬虫之实习僧招聘信息及数据分析
- Python爬虫之51job招聘数据信息爬取实战
- Python爬虫之实习僧招聘信息及数据分析
- python 爬虫动态加载网站
- Python爬虫scrapy框架爬取动态网站——scrapy与selenium结合爬取数据
- python爬虫难点解析——动态json数据处理
- python爬虫(爬取豆瓣电影)_动态网页,json解释,中文编码
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息