HashMap的数据结构,哈希冲突,JDK1.7和JDK1.8 HashMap的区别
1.JDK1.7
HashMap是Java中大家最常用的一个map实现类,其为键值对也就是key-value的形式。他的数据结构则是采用的位桶和链表相结合的形式完成了,即拉链法。具体如下图所示:
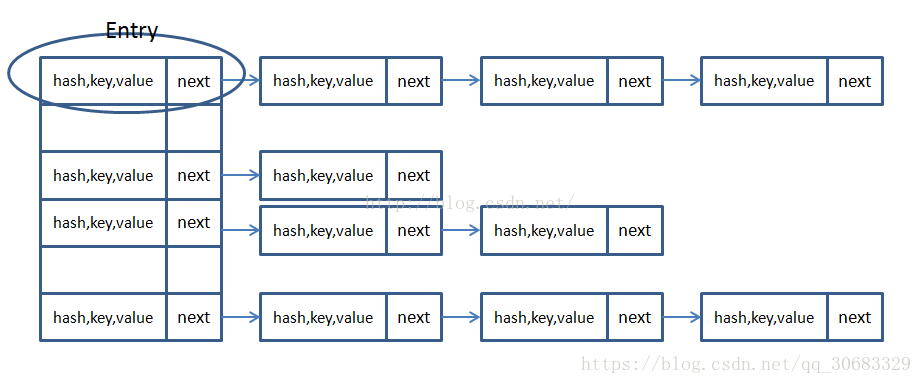
如果两个key通过int index = hash % Entry[].length得到了相同的index(hash冲突),就会跟在之间那个entry连接在后面,也就是按照顺序存储在后面的链表中,也就是解决hash冲突的拉链法。
由于可能会出现的Hash冲突,所以java采用了链地址法来处理冲突,首先会通过hashcode来查到对应的Entry对象,如果找到了之后发现这个链表上链接了多个Entry对象,则再调用equals方法对value进行逐一比较。但是如果当链表过长后,HashMap就会自动将链表转化为红黑树,以提高查找效率。
当链表数组的容量超过初始长度的0.75之后,再散列就会将该链表再扩大2倍,创建一个新的2倍长的链表,然后再讲数据逐个搬迁复制到新链表中去。
扩容时:
其默认的大小是16,一旦>0.75*16之后,就会调用resize()进行扩容,扩容非常耗时,所以如果需要保存较多的话,最好在创建一开始就制定好HashMap的初始容量。
.JDK1.8
采用的是位桶数组,其底层采用红黑树。
默认的加载因子是0.75,如果不扩容,链表就会越来越长,查找起来因为要逐一equals进行比对,所以会慢很多,链表到7次以后使用红黑树。当然现在因为又采用了红黑树,相对来说比jdk1.7要好一些。扩容之后,会将原本的链表数组中的每个链表分为奇偶两个,分别挂在新链表的数组下的对应的散列位置。减少查找时间,提高效率。
jdk1.8的最大区别就在于底层的红黑树策略。
相对于JDK1.7,HashMap处理hash冲突时,会首先存放在链表中去,但是一旦链表中的数据较多(即到达7个)之后,就会转用红黑树来进行存储,优化存储速度。O(logn)。如果是链表。一定是O(n)。

- 一文读懂JDK1.7,JDK1.8,JDK1.9的hashmap,hashtable,concurrenthashmap及他们的区别
- HashMap在JDK1.7和1.8版本的区别
- jdk1.7和jdk1.8中hashmap区别
- HashMap学习笔记,比较JDK1.7/1.8的区别
- HashMap的实现原理,以及在JDK1.7和1.8的区别
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
- jdk源码剖析四:JDK1.7升级1.8 HashMap原理的变化
- HashMap实现与哈希冲突,与HashTable的区别
- HashMap在Java1.7与1.8中的区别
- JDK1.8 --- HashTable和HashMap的区别
- jdk源码剖析四:JDK1.7升级1.8 HashMap原理的变化
- 【JAVA秒会技术之ConcurrentHashMap】JDK1.7与JDK1.8源码区别
- 数据结构--jdk1.8 HashMap
- JDK1.8 使用平衡树处理HashMap的高频hash冲突问题
- jdk1.7 vs jdk 1.8 之HashMap
- HashMap在Java1.7与1.8中的区别
- 面试中被问到HashMap的结构,1.7和1.8有哪些区别?这篇做深入分析!
- jdk1.7和jdk1.8中hashmap区别
- HashMap底层原理剖析及JDK1.7和1.8的对比
- hashmap的jdk1.7和jdk1.8总结