HashMap的实现原理,以及在JDK1.7和1.8的区别
1.JDK1.7
HashMap是Java中大家最常用的一个map实现类,其为键值对也就是key-value的形式。他的数据结构则是采用的位桶和链表相结合的形式完成了,即拉链法。具体如下图所示:
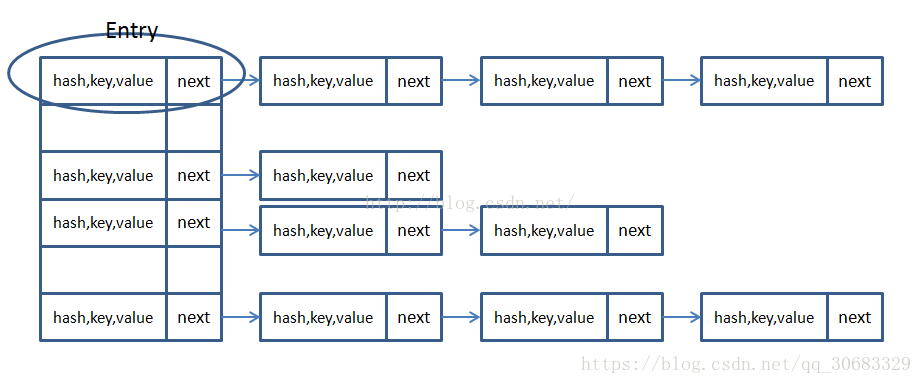
HashMap里面存储的是静态内部类Entry的对象,这个对象其实也是一个key-value的结构。以下是Entry的源码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
/** 指向下一个元素的引用 */
Entry<K,V> next;
int hash;
/**
* 构造方法为Entry赋值
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
...
...
}
1.1、HashMap的存取过程
// 存储时:
int hash = key.hashCode(); // 1个key对应一个固定的hash值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
如果两个key通过int index = hash % Entry[].length得到了相同的index,就会跟在之间那个entry连接在后面,也就是按照顺序存储在后面的链表中,也就是解决hash冲突的拉链法。
1.2、HashMap的get() 方法
由于可能会出现的Hash冲突,所以java采用了链地址法来处理冲突,首先会通过hashcode来查到对应的Entry对象,如果找到了之后发现这个链表上链接了多个Entry对象,则再调用equals方法对value进行逐一比较。但是如果当链表过长后,HashMap就会自动将链表转化为红黑树,以提高查找效率。
当链表数组的容量超过初始长度的0.75之后,再散列就会将该链表再扩大2倍,创建一个新的2倍长的链表,然后再讲数据逐个搬迁复制到新链表中去。
1.3、扩容时调用resize()
其默认的大小是16,一旦>0.75*16之后,就会调用resize()进行扩容,扩容非常耗时,所以如果需要保存较多的话,最好在创建一开始就制定好HashMap的初始容量。
2.JDK1.8
采用的是位桶数组,其底层采用红黑树。
transient Node<k,v>[] table;//存储(位桶)的数组</k,v>
默认的加载因子是0.75,如果不扩容,链表就会越来越长,查找起来因为要逐一equals进行比对,所以会慢很多。当然现在因为又采用了红黑树,相对来说比jdk1.7要好一些。扩容之后,会将原本的链表数组中的每个链表分为奇偶两个,分别挂在新链表的数组下的对应的散列位置。减少查找时间,提高效率。
2.1 jdk1.8的最大区别就在于底层的红黑树策略。
相对于JDK1.7,HashMap处理hash冲突时,会首先存放在链表中去,但是一旦链表中的数据较多(即>8个)之后,就会转用红黑树来进行存储,优化存储速度。O(lgn)。如果是链表。一定是O(n)。
---------------------
作者:逐风的小黄
来源:CSDN
原文:https://blog.csdn.net/qq_30683329/article/details/80454518
版权声明:本文为博主原创文章,转载请附上博文链接!

- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
- Jdk1.8中的HashMap实现原理
- Java中HashMap底层实现原理(JDK1.8)源码分析
- HashMap和ArrayMap实现原理的区别以及各自优势
- HashMap 在JDK1.8中的实现(与JDK1.7对比)
- Java中HashMap底层实现原理(JDK1.8)源码分析
- Java中HashMap底层实现原理(JDK1.8)源码分析
- 【图解JDK源码】HashMap的容量大小增长原理(JDK1.6/1.7/1.8)
- Java中HashMap底层实现原理(JDK1.8)源码分析
- hashMap的内部实现原理(JDK1.8 hashmap改动)
- jdk1.7 HashMap的实现原理
- 一文读懂JDK1.7,JDK1.8,JDK1.9的hashmap,hashtable,concurrenthashmap及他们的区别
- Java中HashMap底层实现原理(JDK1.8)源码分析
- HashMap学习笔记,比较JDK1.7/1.8的区别
- HashMap实现原理以及与其他Map实现类的区别
- Jdk1.8中的HashMap实现原理
- (转载)Java中HashMap底层实现原理(JDK1.8)源码分析
- Java中HashMap底层实现原理(JDK1.8)源码分析
- HashMap的容量大小增长原理(JDK1.6/1.7/1.8)
- Java中HashMap底层实现原理(JDK1.8)源码分析