字节跳动 后台开发 实习 面试准备
本文是网上各位大神字节跳动面试后回忆的面试问题总结,仅用于我自己准备面试!问题较多,建议先收藏后慢慢看!
概念性问题
-
http报文信息
由 请求行/请求头/空白行/请求体 组成。
请求行:请求方法字段、URL、http协议版本。
请求头部:关键字/值 (每一行是一对 、多少数据就多少行)。 -
进程调度都有哪些算法
先来先服务;短作业优先;高优先级先执行;
高响应比优先;时间片轮转;多级反馈队列调度 -
索引应该建立在怎样的列上
不应该建立索引的列:
在查询中比较少使用;只有少量数据值;
定义为text,image,bit的列;
修改的性能远远大于检索的性能时 -
数据库的4种隔离级别
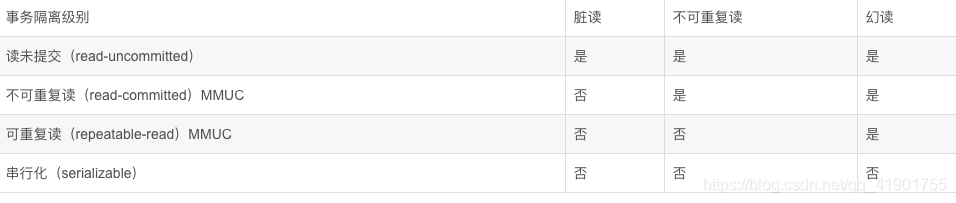
脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
不可重复读:事务 A 多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。(侧重修改)解决不可重复读的问题只需锁住满足条件的行
幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。(侧重新增删除)解决幻读需要锁表
- 信号量
- 路由器的分段与重组
分段是将数据分组分割成小块以便它们能够适合基础网络的帧。
数据报也可以被标记为“不可分段”,如果一个数据报被标记了,那么在任何情况下都不准对它进行分段。
透明分段原则是:当包遇到了通不过的子网的时候,在进入之前由路由器按照子网的MTU(最大传输单元)进行分段,前面的分段对于后面的网络透明,离开子网的时候重组经过分段的包。
不透明分段:在任何中间网关都不进行重组,必要的时候只进行分段,仅仅在目标主机进行重组。
简答题
- .请详细描述三次握手和四次挥手的过程
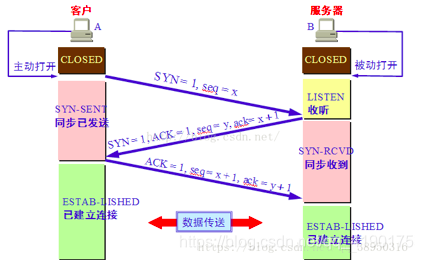
三次握手(Three-way Handshake),是指建立一个 TCP 连接时,需要客户端和服务器总共发送3个包
三次握手的目的是连接服务器指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号,交换 TCP 窗口大小信息。在 socket 编程中,客户端执行 connect() 时。将触发三次握手。
三次握手的原因是为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误
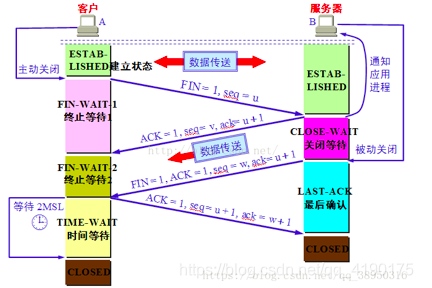
TCP 的连接的拆除需要发送四个包,因此称为四次挥手(Four-way handshake),也叫做改进的三次握手。客户端或服务器均可主动发起挥手动作,在 socket 编程中,任何一方执行 close() 操作即可产生挥手操作。
-四次挥手中TIME_WAIT状态存在的目的是什么?
TIME_WAIT状态就是用来重发可能丢失的ACK报文。
在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。
Client会设置一个计时器,等待2MSL的时间。
如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。
MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。
如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
- TCP是通过什么机制保障可靠性的?
ACK确认机制、超时重传、滑动窗口以及流量控制。滑动窗口协议(Sliding Window Protocol),属于TCP协议的一种应用,用于网络数据传输时的流量控制,以避免拥塞的发生。
-描述线程、进程以及协程的区别? 描述线程、进程以及协程的定义和区别,顺便描述Python语言中三者的使用
1、进程
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间。开销比较大,但相对比较稳定安全。用户运行自己的程序,系统就创建一个进程,并为它分配资源
2、线程
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。多线程就像是火车上的每节车厢,而进程就是火车
3、协程
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
二、区别:
1、进程多与线程比较
线程是指进程内的一个执行单元,也是进程内的可调度实体。线程与进程的区别:
- 地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间
- 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
- 线程是处理器调度的基本单位,但进程不是
- 二者均可并发执行
- 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
协程多与线程进行比较
- 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程则是异步
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
进程和线程、协程在python中的使用
1、多进程一般 来利用多核CPU,主要是用在CPU密集型的程序上,多进程的优势就是一个子进程崩溃并不会影响其他子进程和主进程的运行,但缺点就是不能一次性启动太多进程,会严重影响系统的资源调度,特别是CPU使用率和负载。
2、多线程一般是使用threading库,完成一些IO密集型并发操作。多线程的优势是切换快,资源消耗低,但一个线程挂掉则会影响到所有线程,所以不够稳定。
3、协程一般是使用gevent库,当然这个库用起来比较麻烦,所以使用的并不是很多。相反,协程在tornado的运用就多得多了,使用协程让tornado做到单线程异步,所以协程使用的地方最多的是在web应用上。
总结一下就是IO密集型一般使用多线程或者多进程,CPU密集型一般使用多进程,强调非阻塞异步并发的一般都是使用协程.
- 网络IO模型有哪些?*
5种网络I/O模型,阻塞、非阻塞、I/O多路复用、信号驱动IO、异步I/O。从数据从I/O设备到内核态,内核态到进程用户态分别描述这5种的区别,只有异步io才是全程非阻塞,其它4种都是同步IO。
- I/O多路复用中select/poll/epoll的区别?
从select的机制,以及select的三个缺点,讲解epoll机制,以及epoll是如何解决select的三个缺点的。还会讲到epoll中水平触发和边沿触发的区别。
- HTTP相关基础
问题1: 客户端访问url到服务器,整个过程会经历哪些?
DNS 解析:将域名解析成 IP 地址
TCP 连接:TCP 三次握手
发送 HTTP 请求
服务器处理请求并返回 HTTP 报文
浏览器解析渲染页面
断开连接:TCP 四次挥手
(网络七层模型分别是物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。)
问题2: 描述HTTPS和HTTP的区别
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
问题3: HTTP协议的请求报文和响应报文格式
请求报文:
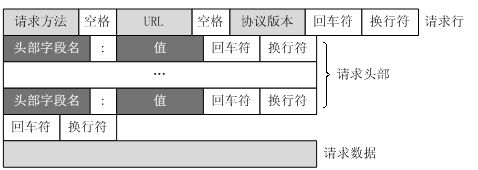
HTTP响应也由三个部分组成,分别是:状态行、消息报头、响应正文。
问题4: HTTP的状态码有哪些?
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。
常见状态代码、状态描述的说明如下。
200 OK:客户端请求成功。
400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
403 Forbidden:服务器收到请求,但是拒绝提供服务。
404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
500 Internal Server Error:服务器发生不可预期的错误。
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常,举个例子:HTTP/1.1 200 OK(CRLF)。
缓存和数据库的基础知识
问题1: 描述一下redis有哪些数据结构。
基础的数据结构有5种,String/List/Hash/Set/Zset,还答了高级数据结构HyperLogLog/BitMap/BloomFilter/GeoHash。面试官还问了BloomFilter的原理以及Zset的实现原理,主要讲解跳跃表。
问题2: MySQL场景题目
面试官提供场景,要求写出查询SQL,考察联合语句,如何分页以及复杂语句的优化
裸编算法
- 翻转单链表(leetcode 428
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
迭代法
#迭代法 class Solution: def reverseList(self, head: ListNode) -> ListNode: pre=None cur=head while cur: tmp=cur.next #要有一个中间寄存器 保存cur的本来的下一个结点 cur.next=pre #将当前结点cur的下一个结点链接到pre上 pre=cur # 然后pre 要移动 cur=tmp # cur 要移动到 原本的 链表的下一个结点 注意这里不能 cur=cur.next return pre
递归法
class Solution: def reverseList(self, head: ListNode) -> ListNode: if head==None or head.next==None: return head tail=self.reverseList(head.next) head.next.next=head head.next=None return tail
2.树的非递归先序遍历
class Solution: def preorderTraversal(self, root: TreeNode) -> List[int]: WHITE, GRAY = 0, 1 res = [] stack = [(WHITE, root)] while stack: color, node = stack.pop() if node is None: continue if color == WHITE: stack.append((WHITE, node.right)) stack.append((WHITE, node.left)) stack.append((GRAY, node)) else: res.append(node.val) return res
3.回行矩阵遍历
4.二叉树多个节点的最近公共祖先
搜索二叉树:
class Solution: def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': """以下迭代法""" p_val = p.val q_val = q.val node = root while node: parent_val = node.val if p_val > parent_val and q_val > parent_val: node = node.right elif p_val < parent_val and q_val < parent_val: node = node.left else: return node """以下递归法""" x=p.val y=q.val father=root.val if x<father and y<father: return self.lowestCommonAncestor(root.left,p,q) elif x>father and y>father: return self.lowestCommonAncestor(root.right,p,q) else: return root parent_val = root.val
普通二叉树:
class Solution: def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': if(root==None): return None elif (root==p or root == q): return root left=self.lowestCommonAncestor(root.left,p,q) right=self.lowestCommonAncestor(root.right,p,q) if not(left==None or right==None): return root elif left: return left else: return right 作者:bi-feng-ku 链接:https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/di-gui-fa-python-by-bi-feng-ku/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
5.调整一棵二叉树,调整后,要求所有节点的右子树的最大值大于左子树的最大值。
6.用两种积木,2X1型,1X1型,摆满n行m列,有多少种摆法。
7.Longest Increasing Path in a Matrix
6.设计报错机制
a.通过返回值来通知用户是否出错。这种方法会导致无法直接返回返回值。
b.发生错误时设置一个全局变量,则函数可以直接传递返回值;然后设置一个函数去分析这个全局变量。存在的问题就是经常忘记检查全局变量。
c.异常:在发生错误时抛出异常,并且可以根据错误的原因抛出对应的异常
实例化类中资源时,应该写在什么地方
由于在实例化类中资源时为了防止有报错的情况,所以最好放在构造函数中
reference
https://blog.csdn.net/u011010851/article/details/82594420
https://juejin.im/post/5cf7ea91e51d4576bc1a0dc2
其他:API业务的架构问题,负载均衡、CDN、DNS等问题。以及也问到了HTTP相关问题,要求描述HTTP的版本之间的区别,主要是1.0/1.1/2.0三个版本的区别。详细说了1.0与1.1之间是连接模型的区别(短连接、长连接、管线化),1.1与2.0之间的区别是I/O多路复用的单一长连接、服务器推送、二进制分桢、首部压缩等。
考察微服务架构相关知识,服务治理(限流、降级、熔断)。
- 点赞
- 收藏
- 分享
- 文章举报
 比风酷
发布了21 篇原创文章 · 获赞 8 · 访问量 2198
私信
关注
比风酷
发布了21 篇原创文章 · 获赞 8 · 访问量 2198
私信
关注

- 后台开发面试准备 Redis
- 后台开发面试准备2:linux共享内存
- 亿方云面试经验(后台开发工程师实习)
- 准备去实习了,java后端开发和android都学过,去实习面试java后端还是android的好
- 后台开发面试准备1:Linux命令
- 今日头条C++后台开发实习面试总结
- 2018.4.3晚_京东实习_后端开发面试记录
- 【预测】腾讯后台开发明天面试会被虐死
- 2015腾讯校招后台开发类内推电话面试(技术工程事业群TEG内推面试分享)
- Java面经(后台开发)校招准备资料汇总
- [todo]后台开发面试 c c++
- 腾讯后台实习面试
- 【2014腾讯实习招聘-面试-移动客户端开发】
- 开发工程师面试准备及面试技巧
- 互联网公司Java后台开发面试经历
- 前端开发工程师应该如何准备一场技术面试?
- Java后台开发面试
- 实习前的准备工作:Android开发环境的搭建
- 实习面试概念性问题准备
- c++后台开发菜鸡到找到实习总结