分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析
分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析
Hierarchical Conditional Relation Networks
for Video Question Answering

论文链接:https://arxiv.org/pdf/2002.10698.pdf
摘要
视频问答(VideoQA)具有挑战性,因为它需要建模能力来提取动态视觉伪影和远距离关系,并将它们与语言概念相关联。本文介绍了一种通用的可重复使用的神经单元,称为条件关系网络(CRN),它作为构建块来构建更复杂的视频表示和推理结构。CRN以一个张量对象数组和一个条件特征作为输入,并计算一个编码输出对象数组。模型构建成为这些可重用单元的复制、重新排列和堆叠的简单练习,用于不同的模式和上下文信息。因此,该设计支持高阶关系和多步推理。VideoQA的最终架构是一个CRN层次结构,其分支表示子视频或剪辑,所有分支都与上下文条件共享相同的问题。本文对知名数据集的评估取得了新的SoTA结果,展示了在复杂领域(如VideoQA)上构建通用推理单元的影响。
Introduction
回答关于视频的自然问题是认知能力的有力证明。该任务涉及在语言线索的合成语义指导下获取和操作时空视觉表征[7,17,20,30,33,36]。由于问题可能不受约束,VideoQA需要深入的建模能力,以分层方式编码和表示关键的视频属性,如对象持久性、运动pro-files、长时间动作和可变长度时间关系。对于VideoQA来说,理想情况下,可视化表示应该是特定的问题并准备好答案。
目前用于QA视频建模的方法是构建神经架构,其中每个子系统要么是为特定的定制目的设计的,要么是为特定的数据模式设计的。由于这种特殊性,这种手工构建的体系结构对于数据形态的变化[17]、不同的视频长度[24]或问题类型(如帧QA[20]与动作计数[6])往往是最佳的。这导致了异构网络的激增。
在这项工作中,本文提出了一个通用的可重复使用的神经单元,称为条件关系网络(CRN),它将对象数组封装并转换成一个新的基于上下文特征的数组。该单元计算输入对象之间的稀疏高阶关系,然后通过特定上下文调制编码(参见图2)。CRN的灵活性及其封装设计使得它可以被复制和分层,以直接的方式形成深层的条件关系网络(HCRN)。
因此,叠层单元提供了视频对象关系知识的语境化重新定义——以阶段性的方式,它将外观特征与剪辑活动流和语言语境相结合,并通过整合整个视频运动和语言特征的语境进行跟踪。由此产生的HCRN是同质的,符合网络的设计理念,如InceptionNet[31]、ResNet[9]和FiLM[27]。
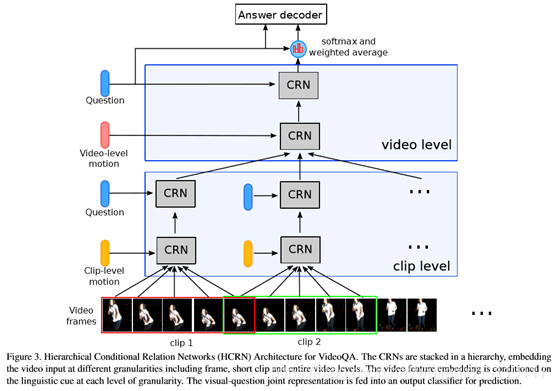
crn的层次结构如下:在最低层次上,crn对剪辑中的帧外观之间的关系进行编码,并将剪辑运动作为上下文进行集成;该输出在下一阶段由crn进行处理,crn现在集成在语言上下文中;在下一阶段,CRN捕获剪辑编码之间的关系,并作为上下文集成在视频运动中;在最后阶段,CRN将视频编码与语言特征作为上下文集成(参见图3)。该模型通过允许crn分层堆叠,自然地支持视频和关系推理中的分层结构建模;通过允许分阶段引入适当的上下文,该模型处理多模式融合和多步骤推理。
对于长视频,可以添加进一步的层次结构级别,以实现远距离帧之间关系的编码。本文展示了HCRN在回答主要视频qa数据集中的问题的能力。四层CRN单元的层次结构在所有的VideoQA任务中都能获得良好的答案准确性。值得注意的是,它在涉及外貌、动作、状态转换、时间关系或动作重复的问题上一直表现良好,证明了模型可以分析和把所有这些渠道的信息结合起来。此外,HCRN可以很好地扩展到较长的视频,只需添加一个额外的层。
图1展示了几个典型的例子,这些例子对于视觉问题交互的基线是困难的,但是可以通过本文的模型来处理。本文的模型和结果证明了建立支持本机多模态交互的通用神经推理单元对提高VideoQA模型的鲁棒性和泛化能力的影响。

- Related Work
本文提出的HCRN模型通过解决两个关键挑战来推进VideoQA的发展:
(1) 有效地将视频表示为各种互补因素的混合体,包括外观、运动和关系,以及
(2) 有效地允许这些视觉特征与语言查询的交互。
Spatio-temporal video representation
本文的HCRN模型是在这些趋势的基础上发展起来的,它允许视频信息的所有三个通道,即外观、运动和关系,在分层多尺度框架的每一步中迭代地相互作用和补充。 HCRN将调节因子从已确定的信息中分离出来,因此它更有效,也更灵活地使操作者适应调节类型。时间层次已经被用于视频分析[22],最近用递归网络[25,1]和图网络[23]。然而,本文相信本文是第一个考虑多模式的层次交互,包括视频问答的语言提示。
Linguistic query–visual feature interaction in VideoQA
HCRN模型支持将语言线索作为语境因素对视频特征进行条件化处理。这使得语言线索比任何可用的方法都能更早、更深入地参与视频呈现结构。
Neural building blocks
在VideoQA领域之外,CRN单元与其他通用的神经构建块共享神经架构一致性的理想,例如InceptionNet中的块[31]、ResNet中的剩余块[9]、RNN中的递归块、影像中的条件线性层[27]和神经矩阵网中的矩阵矩阵块[5]。本文的CRN通过假设一个支持条件关系推理的数组到数组块,并且可以重用来构建视觉和语言处理中的其他用途的网络,从而显著地背离了这些设计。

- Method
VideoQA的目标是根据一个自然问题q,从videoV中推断出答案a。答案a可以在一个答案空间a中找到,该回答空间a是为开放式问题预先定义的一组可能的答案,或者在多选题的情况下,可以在一个候选答案列表中找到。形式上,VideoQA可以表述如下:
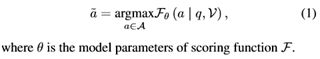
Visual representation

Linguistic representation
通过这些表示,本文现在描述本文的新的VideoQA层次结构(见图3)。在第3.1节中,本文首先介绍了作为架构构建块的核心组成计算单元。在下面的小节中,本文建议将F设计为一个逐层网络架构,可以通过简单地以特定方式堆叠核心单元来构建。
3.1. Conditional Relation Network Unit
本文引入了一个可重用的计算单元,称为条件关系网络(CRN),它将n个对象的数组
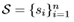 和一个条件特征c-都放在同一向量空间Rd或张量空间
和一个条件特征c-都放在同一向量空间Rd或张量空间
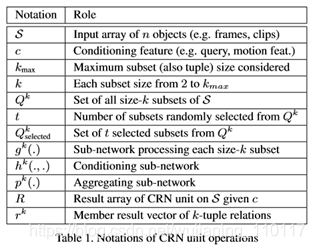
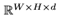 中作为输入。CRN生成一个相同维度的对象的输出数组,其中包含给定全局上下文的输入特征的高阶对象关系。在Alg算法中给出了CRN单元的运算1和图2中的视觉效果。表1总结了这些演示文稿中使用的符号。
中作为输入。CRN生成一个相同维度的对象的输出数组,其中包含给定全局上下文的输入特征的高阶对象关系。在Alg算法中给出了CRN单元的运算1和图2中的视觉效果。表1总结了这些演示文稿中使用的符号。
3.2. Hierarchical Conditional Relation Networks
本文使用CRN块构建一个深度网络架构,利用视频序列的内在特征,即时间关系、运动和视频结构层次,并支持由语言问题引导的推理。本文将提出的网络架构称为层次条件关系网络(HCRN)(见图3)。通过堆叠可重复使用的核心单元来设计HCRN的部分灵感来自于现代CNN网络架构,其中InceptionNet[31]和ResNet[9]是最著名的例子。
3.3. Answer Decoders and Loss Functions
在[10,30,6]之后,本文根据任务采用不同的应答解码器。开放式问题被视为多标签分类问题。为此,本文采用一个分类法,将检索到的信息组合作为输入。 对于多选题类型(如TGIF-QA中的重复动作和状态转换),每个候选答案的处理方式与问题相同。具体来说,本文使用共享参数HCRNs作为语言提示,无论是问题还是每个候选答案。
3.4. Complexity Analysis
本文在这里提供一个简要的分析,留下详细的衍生补充。对于固定采样分辨率t,CRN的一次前向通过将花费kmax中的二次时间。对于长度n、特征尺寸F的输入阵列,该单元产生具有相同特征尺寸的大小kmax-1的输出阵列。HCRN的总体复杂性取决于每个CRN单元的设计选择和CRN单元的具体布置。为了清楚起见,让t=2和kmax=n-1,这在以后的实验中被发现是有效的。假设有N个长度为T的剪辑,制作长度为L=NT的视频。图3的2级架构需要2t LF时间计算最低层的crn,2NLF时间计算第二层,共2(T+N)LF时间。
- Experiments Results
4.1. Datasets
TGIF-QA datasets,MSVD-QA datasets,MSRVTT-QA datasets。
本文使用准确度作为所有实验的评估指标,除了TGIF-QA数据集上应用均方误差(MSE)的重复计数。
4.2. Implementation Details
视频被分割成8个片段,每个片段默认包含16个帧。MSRVTT-QA中的长视频还被分割成24个片段,以评估处理非常长的序列的能力。除非另有说明,否则默认设置为图3所示的2级HCRN,d=512,t=1。本文最初以的学习率训练模型,每10个阶段衰减一半。所有实验在25个阶段后终止,报告的结果在给出最佳验证精度的阶段。该模型的Pytorch实现可以在线获得。

4.3. Results
TGIF-QA的结果汇总在表2中,MSVD-QA和MSRVTT-QA的结果汇总在图4中。报告的竞争对手数量取自原始文件和[6]。很明显,本文的模型在所有数据集的所有任务上都始终优于或优于SoTA模型。当需要强大的时间推理时,即TGIF-QA中涉及动作和转换的问题时,这些改进尤其明显。这些结果证实了同时考虑短期和长期时间关系对找到正确答案的重要性。
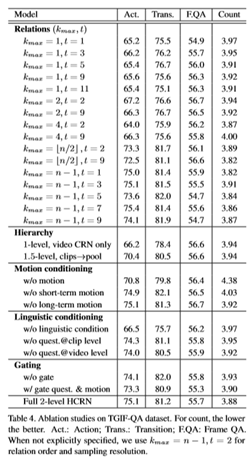
为了更深入地了解本文的模型,本文对TGIF-QA进行了广泛的消融研究,并进行了广泛的配置。结果见表4。全2级HCRN表示图3的全模型,kmax=n−1,t=2。总的来说,本文发现烧蚀任何设计组件或CRN单元都会降低时间推理任务(动作、转换和动作计数)的性能。具体效果如下。

本文在MSRVTT-QA数据集中的长视频上测试HCRN的可伸缩性,该数据集被组织成24个片段(比其他两个数据集长3倍)。本文考虑两种设置:I 2级层次,24个剪辑→1vid:模型如图3所示,其中24个剪辑级CRN后面跟着一个视频级CRN。I三级分层,24个剪辑→4个子视频→1个子视频:从24个剪辑开始,如在二级分层中,本文将24个剪辑分成4个子视频,每个子视频由6个连续的剪辑组成,形成3级分层。这两个模型的设计参数数量相似,约为50米。结果见表5。与现有的处理长视频的方法不同,本文的方法通过提供更深层的层次结构来扩展,如第3.4节中理论分析的那样。使用更深层的层次结构有望显著减少HCRN的训练时间和推理时间,特别是在视频较长的情况下。在本文的实验中,本文通过从2级HCRN到3级HCRN的训练和推理时间减少了4倍,同时保持了相同的性能。
Conclusions
介绍了一种通用的神经网络单元条件关系网络(CRNs)和一种以CRNs为构建块的视频质量保证分层网络的构造方法。CRN是一个关系变换器,它根据上下文特征将一个张量对象数组封装并映射成一个同类的新数组。在此过程中,输入对象之间的高阶关系被条件特征编码和调制。该设计允许灵活构建复杂的结构,如堆栈和层次结构,并支持迭代推理,使其适用于视频等多模态和结构化领域的质量保证。在多个视频质量保证数据集(TGIF-QA、MSVD-QA、MSRVTT-QA)上对HCRN进行评估,证明其具有竞争性推理能力。与基于时间注意的视频对象选择方法不同,HCRN侧重于视频中关系和层次的建模。这种方法和设计选择上的差异带来了显著的好处。CRN单元可以通过注意机制进一步增强,以覆盖更好的对象选择能力,从而可以进一步改进诸如帧QA之类的相关任务。在VideoQA中对CRN的检查突出了构建支持本机多模态交互的通用神经推理单元在提高视觉推理稳健性方面的重要性。本文要强调的是,该单元是通用的,因此适用于其他推理任务,本文将对此进行探讨。这包括考虑对TVQA[17]和MovieQA[33]任务至关重要的附带语言频道的扩展。
- 点赞
- 收藏
- 分享
- 文章举报
 wujianming_110117
发布了96 篇原创文章 · 获赞 5 · 访问量 5408
私信
关注
wujianming_110117
发布了96 篇原创文章 · 获赞 5 · 访问量 5408
私信
关注

- 人体姿态和形状估计的视频推理:CVPR2020论文解析
- 视频教学动作修饰语:CVPR2020论文解析
- 视频动作定位的分层自关注网络:ICCV2019论文解析
- 微软亚洲研究院论文解读:GAN在网络特征学习中的应用(PPT+视频)
- 1、GAN-生成对抗网络原理 2、WGAN (原理解析) 3、Lipschitz连续 4、从Wasserstein距离、对偶理论到WGAN 5、DCGAN的原理及应用 6、论文笔记:IRGAN
- CVPR2018论文解析之《Fully Convolutional Adaptation Networks for Semantic Segmentation》(全卷积适配网络)
- CVPR14与图像视频检索相关的论文
- Fielding的博士论文学习笔记(二)——概念和术语与现实网络模型的对应关系
- CVPR14与图像视频检索相关的论文
- 安卓应用播放视频卡顿的原因解析及解决办法
- 自定义VideoView播放网络视频
- 区块链全栈工程师指南第8课——分层确定性钱包深度解析-CSDN讲师-专题视频课程...
- android 随手记 videoview循环播放网络视频 和mediaplayer+sufaceview播放网络视频
- Android VideoView播放网络视频
- 腾创网络语音视频应用软件诚招全国代理
- 小应用 请求网络和解析数据
- 视频参数介绍以及之间的关系(转自网络)
- 野外火灾烟雾视频检测技术研究及应用(数据集,代码及论文)
- 在Android应用中使用Pull解析XML文件(传智播客视频笔记)
- 使用JiaoZiVideoPlayer播放网络视频,暂停继续