模糊视频帧插值:CVPR2020论文点评
模糊视频帧插值:CVPR2020论文点评
Blurry Video Frame Interpolation

论文链接:https://arxiv.org/pdf/2002.12259.pdf
摘要
现有的工作主要通过帧去模糊和帧内插两种方法来降低运动模糊和上变频帧率。然而,很少有研究涉及到联合视频增强问题,即从低帧速率的模糊输入中合成高帧速率的清晰结果。本文提出了一种模糊视频帧内插方法,可以同时降低运动模糊和上变频帧速率。具体地说,本文开发了一个金字塔模块来周期性地合成清晰的中间帧。金字塔模块具有可调的空间接收场和时间范围,从而有助于可控的计算复杂性和恢复能力。此外,本文还提出了一个金字塔间的递归模块来连接序列模型以利用时间关系。金字塔模块集成了一个递归模块,因此可以迭代合成时间平滑的结果,而不会显著增加模型的大小。大量的实验结果表明,本文的方法优于最新的方法。源代码和预先培训的模型可以在https://github.com/laomao0/BIN上找到。
- Introduction
帧内插的目的是从捕获的帧中恢复未看到的中间帧[1,9,2,3]。它可以提高帧率,提高视觉平滑度。大多数最先进的帧插值方法[1,9,2]首先估计对象的运动,然后使用参考帧执行帧扭曲以合成像素。然而,如果原始参考帧被运动模糊降级,则运动估计可能不准确。因此,利用现有的帧插值方法恢复清晰的中间帧是一个挑战。考虑到运动模糊带来的上述问题,现有的一些方法通常采用一种预模糊过程[32,35,30]。一种简单的方法是进行帧去模糊,然后进行帧插值,本文称之为级联方案。然而,这种方法在插值质量方面是次优的。首先,插值性能高度依赖于去模糊图像的质量。在去模糊阶段引入的像素误差将传播到插值阶段,从而降低整体性能。其次,大多数帧内插方法都以两个连续的帧作为参考,即这些方法具有两个时间范围。然而,在级联方案中,由于不完全去模糊的帧,短时间范围内的插值模型很难保持相邻帧之间的长期运动一致性。另一种策略是先进行帧内插,然后进行帧去模糊。但是,整体质量会下降,因为插入的帧会受到输入的模糊纹理的影响,如图1所示。

在本文中,本文用一个单一的退化模型来描述联合视频增强问题。然后提出了一种模糊视频帧内插(BIN)方法,包括金字塔模块和金字塔间递归模块。金字塔模块的结构类似于由多个骨干网络组成的金字塔。金字塔模块灵活。随着尺度的增大,模型产生了更大的空间接收场和更宽的时间范围。flexible结构还可以在计算复杂性和恢复质量之间进行权衡。此外,本文采用循环损耗[17,27,38,6,34,26]来增强金字塔模块的输入帧和重新生成的帧之间的空间一致性。在金字塔结构的基础上,提出了一种有效利用时间信息的跨金字塔递归模块。具体地说,递归模块采用convlsm单元来跨时间传播帧信息。传播的帧信息有助于模型恢复细节并合成时间一致的图像。除了传统的恢复评估标准外,本文还提出了一种基于光流的方法来评估合成视频序列的运动平滑度。本文既使用现有的数据库,也使用从YouTube抓取的新合成数据集进行性能评估。在Adobe240数据集[30]和YouTube240数据集上进行的大量实验表明,与最新方法相比,所提出的BIN性能良好。
本文的主要贡献总结如下:
•本文通过探索摄像机与运动模糊和帧速率相关的内在特性,提出了联合帧去模糊和插值问题。
•本文提出了一种模糊vide-of-rame插值方法来联合降低模糊和上转换帧速率,并提出了一种金字塔间递归模块来增强生成帧之间的时间一致性。
•本文证明,所提出的方法能够充分利用时空信息,并且相对于最先进的方法具有良好的性能。
- Related Work
Video Frame Interpolation
当插值模型遇到模糊输入时,精确估计光流是非常困难的。本文使用剩余密集网络的变体[41]作为骨干网络。它可以在不使用光流的情况下生成中间帧。此外,本文使用多个骨干网络来构建金字塔模块,可以同时降低模糊和上转换帧速率。
Video Deblurring
本文将骨干网与所提出的金字塔间递归模块整合起来进行迭代运算。该递归模块采用convlsm单元[36]在相邻骨干网之间传播帧信息。由于模型的递归性,该模型可以迭代合成时间平滑的结果,而不必显著增加模型的大小。
Joint Video Deblurring and Interpolation
本文的方法与Jinetal[10]的算法在两个方面有所不同。首先,本文的模型是联合优化的,本文没有明确区分帧去模糊阶段和帧插值阶段。本文使用所提出的骨干网将帧去模糊和插值统一地关联起来。其次,本文没有构造一个近似的递归机制,而是显式地使用所提出的跨锥递归模块,该模块采用convlsm单元跨时间传播帧信息。
- Joint Frame Deblurring and Interpolation
3.1. Degradation Model
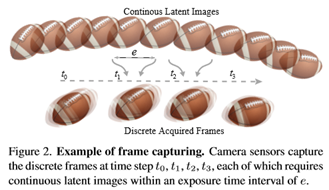
通常,相机通过周期性地打开和关闭快门来捕捉视频[33]。当快门打开时,也被称为曝光,传感器集成物体反射的发光强度,以获取物体像素的亮度。因此,曝光时间占像素亮度,快门开-关频率决定视频帧速率。形式上,本文假设在每个时刻τ存在一个潜影L(τ),如图2所示。本文在一个时间间隔(曝光间隔e)上整合时间t1的潜在图像以获得一个捕获的帧。本文将单个帧的获取表述为:

然后在下一快门时间t2,相机生成由Bt2表示的另一帧。捕获视频的帧速率由以下定义:

特别是,在曝光时间内快速的物体移动或相机抖动会降低像素亮度。这种恶化通常表现为视觉模糊。
3.2. Problem Formulation
在低帧速率模糊输入下,本文的目标是产生高帧速率的清晰输出。本文的目标是增强输入视频,以提供触感和流畅的视觉体验。本文将联合模糊减少和帧速率上转换问题表述为在模糊输入条件下使输出帧的后验最大化:

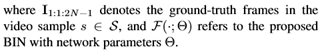
- Blurry Video Frame Interpolation
该模型由金字塔模块和金字塔间递归模块两部分组成。本文使用金字塔模块同时降低模糊和上转换帧速率。金字塔间递归模块可以进一步增强相邻帧之间的时间一致性。本文在图3中展示了整个网络架构。下面本文将描述每个子网的设计和实现细节。
4.1. PyramidModule
本文构建多个骨干网来构建金字塔模块,如图3(a)所示。
金字塔模块通过改变模型结构的尺度,具有可调的空间接收场和时间范围。本文在图3(a)中显示了三种不同比例的网络,用比例2、比例3和比例4表示。尺度的增加使整个网络更深,从而形成更大的空间接收场。同时,尺度的增加也扩大了输入的数量,即时间范围,有利于上下文时间信息的利用。例如,量表2的模块具有三个时间范围,而量表4的模块可以利用来自五个帧的信息,并且与量表2的模块相比,它具有更深的接收场。
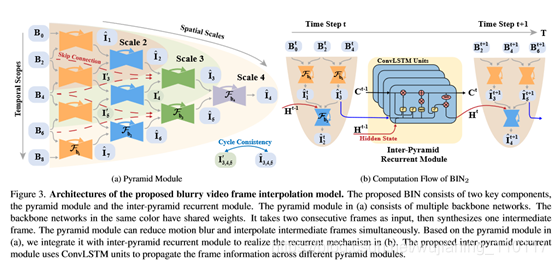
4.2. Inter-Pyramid Recurrent Module
时间运动平滑度是影响人类视觉体验的关键因素。在金字塔结构的基础上,本文提出了一个金字塔间递归模块来构造多尺度模糊帧插值模型,用BINl表示,其中l是金字塔结构的尺度。递归模块可以进一步增强相邻帧之间的时间运动一致性。椎体间循环模块由多个convlsm单元组成。每个convlsm单元使用隐藏状态将以前的帧信息传播到当前的金字塔模块。为了简洁起见,本文举例说明BIN2的计算流程,它采用一个convlsm单元和一个比例为2的金字塔模块。如图3(b)所示,时间t∈[1,t]。
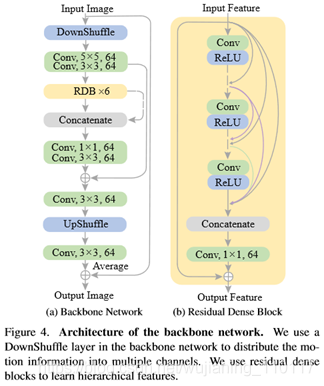
Backbone Network
本文使用剩余密集网络的变体[41]作为骨干网络。如图4所示,主干模块由一个下卧层和一个上卧层[29]、六个卷积层和六个剩余密集块[41]组成。剩余致密块由4个3×3卷积层、1个1×1卷积层和4个ReLU活化层组成。剩余密集块中的所有层次特征被串联起来用于连续的网络模块。
4.3. Implementation Details
Loss Function
本文的损失函数由两个项组成,包括像素重建和循环一致性损失:

Training Dataset
本文使用Adobe240数据集[30]来训练提议的网络。它由120个视频组成,每秒240帧,分辨率为1280×720。本文使用112个视频来构建训练集。以下离散退化模型用于生成训练数据:
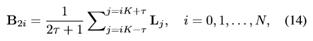
其中Li是第i个高帧速率潜像,B2i是第i个获得的低帧速率模糊帧,参数K确定获得帧的帧速率,2τ+1对应于限制模糊程度的等效长曝光时间[4]。本文对高帧速率序列进行下采样以生成地面真帧。地面真值序列的帧速率是模糊序列的两倍。本文使用参数K=8和τ=5的方程(14)来生成训练数据。训练图像的分辨率为640×352。考虑到计算的复杂性,本文选择T=2的时间长度。本文通过水平和垂直移动、随机裁剪以及颠倒训练样本的时间顺序来增加训练数据。
Training Strategy
本文使用参数β1=0.9和β2=0.999的AdaMax[13]优化器。本文使用的批量大小为2,初始学习率为1e-3。本文为40个阶段训练模型,然后将学习率降低0.2倍,并为另外5个阶段调整整个模型。本文在RTX-2080 Ti-GPU卡上训练网络。大约需要两天的时间。
- Experimental Results
本文在两个视频数据集上评估所提出的模型,并测量合成视频序列的运动平滑度,以便更全面地理解。
5.1. Evaluation Datasets and Metrics
Adobe240
本文使用Adobe240数据集[30]的8个视频进行评估。每段视频的分辨率为1280×720,每秒240帧。YouTube240。本文从YouTube网站下载了59个慢动作视频来构建 YouTube240评估数据集
视频的分辨率和帧速率与Adobe240相同。对于Adobe240和YouTube240 数据集,本文使用参数K=8和τ=5的方程(14)生成评估数据。所有帧的大小都调整为640×352。
Motion Smoothness运动平滑度
本文的运动平滑度指标基于光流估计[10,31]。本文首先使用三个输入I0:1:2和三个参考帧R0:1:2计算微分光流,方程如下:
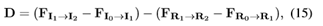
其中Fx→y是从x帧到y帧的估计光流。本文使用最先进的普华永道网络[31]算法来估计光流。
5.2. Model Analysis
为了分析所提出的金字塔模块、金字塔间递归模块、convlsm单元和循环一致性损失的贡献,本文进行了以下广泛的实验:架构可伸缩性。本文首先通过评估具有三种不同尺度(BIN2、BIN3、BIN4)的网络来研究金字塔模块的可伸缩性。
本文在表1中显示了定量结果,并在图5中提供了可视化比较。本文发现使用更大比例的模块在图5中产生了更清晰的细节。本文观察到,随着BIN参数从2.29、3.49增加到468万,网络在Adobe240上的峰值信噪比从31.87dB、32.39dB稳定地提高到32.59dB数据集。但是,运行时成本也从0.02秒、0.10秒增加到0.28秒。比较结果表明,金字塔模块具有可扩展性,其规模平衡了计算复杂度(执行时间和模型参数)和恢复质量。金字塔间递归模块。然后,本文通过使用递归模块和不使用递归模块(即BINl与BINl-w/o rec,l=2,3,4)评估模型来研究所提出的递归模块的贡献。
在表1中,本文发现在Adobe240set中,BIN4获得的SSIM为0.9258,优于BIN4-w/orec获得的SSIM为0.9212。使用递归模块的模型提高了恢复性能,在Adobe240集合中达到约0.5dB增益,在YouTube240集合中达到约0.3dB增益。convlsm模块。为了分析convlsm单元的贡献,本文使用LSTM(BIN2-LSTM)、convlsm(BIN2-convlsm)和不使用任何递归单元(BIN2-None)来评估模型。BIN2-None直接连接以前的帧以重复地传播信息。
表2中的结果表明,在不使用递归单元的情况下,convlsm单元的性能优于LSTM单元和模型。convlsm单元在Adobe240集中提供约0.49dB PSNR增益,在YouTube240集中提供约0.34dB增益。循环一致性损失。最后,本文比较了有循环损耗(BIN4-w/循环损耗)和无循环损耗(BIN4-w/循环损耗)的模型。在Adobe240数据集上,w/和w/o循环损耗模型的峰值信噪比分别为32.59dB和32.42dB。即,周期损耗提供0.17dB增益。结果表明,周期损失保证了帧的一致性,有助于模型生成运动物体的详细信息。

5.3. Compare with the State-of-the-arts
本文用Jinetal[10]提出的算法对所提出的方法进行了评估。他们的模型使用两个模糊输入合成了九个中间帧。本文提取中心内插帧与本文的结果进行比较。此外,本文通过连接去模糊和插值模型,构造了几种级联方法,包括EDVR[35]、SRN[32]去模糊和superslomo[9]、MEMC[2]、DAIN[1]插值。本文从以下几个方面将本文的模型与最先进的算法进行了比较:
插值计算。
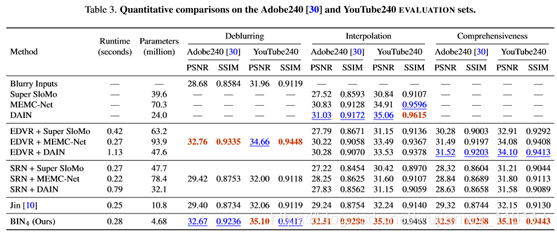
如表3和图6所示,本文的模型对所有比较的方法都有良好的性能。此外,本文发现本文的模型比使用锐化帧(如DAIN)的帧插值方法执行得更好。例如,本文的模型的PSNR为32.51dB,而在Adobe240数据集上DAIN的PSNR为31.03dB。主要原因是一个模糊帧包含了多个锐化帧的信息,本文的方法利用多个模糊帧合成中间帧,而插值方法只使用两个锐化帧。因此,本文的模型可以从多个模糊帧中挖掘更多的时空信息,从而得到更令人满意的中间帧。
去模糊评估。
然后,本文将去模糊方面与最先进的方法进行比较。如表3所示,本文的模型的性能略低于目前最先进的EDVR算法。本文的模型比EDVRintermsofPSNR低0.09dB,但是本文的模型(468万)比EDVR(2360万)小得多,并且本文的模型需要的执行时间更少。综合评价。比较了去模糊和插值的综合性能。级联方法中的高性能预去模糊模型有助于后续插值网络恢复更好的效果。
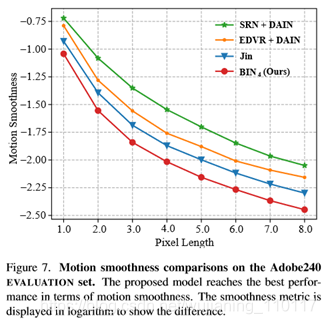
如表3所示,SRN模型的性能略低于EDVR。因此,EDVR+DAIN比SRN+DAIN具有更好的性能。然而,从整体性能来看,性能最好的级联方法(EDVR+DAIN)仍然是次优的。EDVR+DAIN的PSNR为31.52dB,而本文的模型在Adobe240数据集上得到的PSNR为32.59dB。与Jin等人[10]相比,本文的方法在Adobe240数据集上获得了高达3.27dB的增益。他们的训练数据集比Adobe240数据集具有更少的快速移动屏幕和相机抖动。因此,Adobe240数据集比Jin的训练数据集有更严重的模糊性。本文注意到Jin等人。提交时不要发布他们的培训代码。本文无法在Adobe240数据集上优化它们的模型以进行公平比较。然而,与他们的方法相比,本文的网络受益于可伸缩的结构和重复的信息传播,因此获得了显著的性能提升。运动平滑度评估。本文比较了基于第5.1节中介绍的度量的运动平滑度性能。度量值越低,表示性能越好。如图7所示,Jin[10]的模型对所有级联方法都有良好的性能(本文展示了SRN+DAIN和EDVR+DAIN的简洁性),并且本文的算法比Jin的模型有更好的平滑度度量。
在图8中,与级联方法相比,本文模型的光流具有更平滑的形状。本文的网络是一个具有广泛时间范围的单一模型,它有助于生成平滑的帧。此外,与Jin[10]的近似递归机制相比,本文提出的金字塔间递归模块采用convlsm细胞跨时间传播帧信息。它可以进一步增强去模糊帧和插值帧之间的时间一致性。因此,本文的方法优于所有的级联方法和金的模型。
Conclusion
在这项工作中,本文提出一种模糊的视频帧插值方法来解决联合视频增强问题。该模型由金字塔模块和金字塔间递归模块组成。金字塔模块是可伸缩的,其规模平衡了计算复杂度和恢复质量。本文使用循环一致性损失来保证金字塔模块中帧间的一致性。此外,金字塔间递归模块利用时空信息生成时间平滑的结果。大量的定量和定性评价表明,该方法优于现有的方法。
- 点赞
- 收藏
- 分享
- 文章举报
 wujianming_110117
发布了96 篇原创文章 · 获赞 5 · 访问量 5410
私信
关注
wujianming_110117
发布了96 篇原创文章 · 获赞 5 · 访问量 5410
私信
关注

- 人体姿态和形状估计的视频推理:CVPR2020论文解析
- 视频教学动作修饰语:CVPR2020论文解析
- 分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析
- 慢镜头变焦:视频超分辨率:CVPR2020论文解析
- CVPR14与图像视频检索相关的论文
- CVPR2020| 最新CVPR2020论文抢先看,附全部下载链接!
- 入选 CVPR 2020的旷视论文,到底写了啥?
- CVPR2020最全整理:论文汇总 Github源码、论文解读等(按方向划分,0303更新中)
- CVPR14与图像视频检索相关的论文
- 深度人脸识别:CVPR2020论文要点
- CVPR 2020 三篇有趣的论文解读
- 视频跟踪论文读后感系列一:Adaptive Color Attributes for Real-Time Visual Tracking(CVPR2014)
- CVPR14与图像视频检索相关的论文
- CVPR14与图像视频检索相关的论文
- 京东云与AI 10 篇论文被AAAI 2020 收录,京东科技实力亮相世界舞台
- 视频动作定位的分层自关注网络:ICCV2019论文解析
- CVPR 2013 录用论文(目标跟踪部分)
- 手抖有救了!DeblurGAN消除运动模糊效果惊人 | 附论文+代码
- 近几年ICCV,CVPR,和ECCV论文列表[转载]
- 【视频变化检测】2017CVPR Spatio-Temporal Self-Organizing Map Deep Network for Dynamic Object Detection from