图像分类:CVPR2020论文解读
图像分类:CVPR2020论文解读
Towards Robust Image Classification Using Sequential
Attention Models

论文链接:https://arxiv.org/pdf/1912.02184.pdf
摘要
在这篇文章中,我们提出用一个受人类感知启发的注意力模型来扩充一个现代的神经网络结构。具体地说,我们对一个神经模型进行了逆向训练和分析,该模型包含了一个受人启发的视觉注意成分,由一个自上而下的循环顺序过程引导。我们的实验评估揭示了关于这个新模型的稳健性和行为的几个显著发现。首先,对该模型的关注显著地提高了对抗的稳健性,从而在广泛的随机目标攻击强度下获得最先进的ImageNet精度。其次,我们表明,通过改变模型展开的注意步骤(浏览/调整)的数量,我们能够使其防御能力更强,即使是在更强大的攻击下——导致攻击者和防御者之间的“计算竞赛”。最后,我们证明了攻击我们的模型所产生的一些对抗性例子与传统的对抗性例子有很大的不同——它们包含来自目标类的全局的、显著的和空间上连贯的结构,即使是人类也可以识别出来,把模型的注意力从原始图像中的主要对象转移开。
- Introduction
在这项工作中,我们建议使用asoft,顺序,空间,自上而下的注意机制(我们简称为S3TA)[39],从灵长类视觉系统中汲取灵感。虽然我们不认为这是一个生物学上合理的模型,但我们确实认为这个模型捕捉到了视觉皮层的一些功能,即注意力瓶颈和顺序的自上而下的控制。我们在ImageNet图像上对该模型进行了对抗性训练,表明该模型对对抗性攻击具有最先进的鲁棒性(重点是投影梯度下降或PGD[32,36]攻击)。我们表明,通过增加展开模型的步骤数,可以更好地抵御更强的攻击,从而在攻击者和防御者之间产生“计算竞赛”。最后,但重要的是,我们表明,由此产生的对抗性例子通常(尽管并不总是)包括全局的、显著的结构,这些结构将被人类感知和解释(图1)。此外,我们还发现,攻击往往试图将模型的注意力吸引到图像的不同部分,而不是直接扰动源图像中的主要对象。

- Related Work
对抗性训练:对抗性训练旨在建立对抗性攻击的模型。
反复注意模型:注意机制被广泛应用于许多序列建模问题,如问答[24]、机器翻译[6,52]、视频分类和字幕[46,33]、图像分类和字幕[37,11,17,1,55,60,53,5,57]、文本分类[58,47]、生成模型[42,59,30],目标跟踪[29]和强化学习[10]。
注意对抗性稳健性:已经有一些工作研究注意的使用,以加强分类对抗对抗性攻击。
Model
我们强调了模型的重要组成部分,如图2所示。关于全部细节,我们请读者参阅[39]和补充材料。该模型首先将输入图像通过一个“视觉”网络-一个卷积神经网络(这里我们使用一个修改过的ResNet152,见下文)。我们对所有时间步使用相同的输入图像,因此ResNet的输出只需要计算一次。然后,生成的输出张量沿着通道维度分割,以生成键张量和值张量。对于这两个张量,我们连接一个固定的空间基张量,该张量使用傅立叶表示对空间位置进行编码。这个空间基础是重要的,因为我们的注意力瓶颈和空间导致这些张量的空间结构消失,这个基础允许传递空间位置信息。

在这种情况下,关于我们的模型版本的几个要点:
•注意力瓶颈使得模型的决策可能很大程度上依赖于图像。这可能是由于注意图在每个时间步的形状,以及这些图在时间步之间可以有很大的变化。这会导致局部对抗性干扰[38]的效果降低。我们在第6节中对此进行了讨论,并表明实际上,我们经常观察到攻击者需要全局扰动才能成功进行攻击。
•在最后一点之后,注意图有一个单独的通道将所有的价值通道调制在一起,这一事实限制了这些通道的内容在空间上是一致的。在常规ResNet体系结构中,读取最后一个块输出,并在每个通道上独立完成平均池,这允许网络在信息到达最后一层时丢失空间结构。
•为了使空间元素,因此注意力瓶颈的影响更加明显,我们修改ResNet架构,使最终输出具有更大的空间维度。这是通过在除了第二个剩余块以外的所有块中将跨步更改为1来完成的。对于ImageNet输入(224×224像素),得到的地图是28×28像素大(而在常规ResNet中是7×7)。
•注意机制的自上而下性质是,查询来自LSTM的状态,而不是来自输入。因此,模型可以根据其内部状态而不仅仅是输入来主动选择相关信息。这允许模型在查询图像和生成输出时考虑自身的不确定性。
模型的这些顺序性质允许在不改变参数数量的情况下增加计算能力。我们在第5节中证明了这有助于增强健壮性。
- Adversarial Risk
在本文中,我们考虑图像预测在图像x的
 球内保持不变的具体情况,其中相对于在0和1之间缩放的像素强度,允许的最大扰动为
球内保持不变的具体情况,其中相对于在0和1之间缩放的像素强度,允许的最大扰动为
 =16/255。 具体来说,我们关注ImageNet数据集[12],我们主要将目标PGD攻击视为威胁模型,其中目标类是根据[2、28、56]一致随机选择的,前提是未目标攻击可能导致ImageNet上不太有意义的比较(例如,非常相似犬种的错误分类)。
=16/255。 具体来说,我们关注ImageNet数据集[12],我们主要将目标PGD攻击视为威胁模型,其中目标类是根据[2、28、56]一致随机选择的,前提是未目标攻击可能导致ImageNet上不太有意义的比较(例如,非常相似犬种的错误分类)。
4.1. AdversarialTraining
为了训练对抗性攻击的模型,我们遵循了[36]和最近的[56]提出的对抗性训练方法。根据等式(1)中的对抗风险,我们希望最小化以下鞍点问题:

其中,内部最大化问题是找出能使损失最大化的x的对抗扰动;外部最小化问题旨在更新模型参数,从而使对抗风险p(θ)最小化。
4.2. AdversarialEvaluation
在本文中,我们使用PGD攻击来评估该模型,该模型在社区中被视为一个强攻击1,并且有几篇已发表的论文将其作为基准。在我们不能采用解析梯度的情况下,或者在它们不有用的情况下,我们可以使用无梯度优化来近似梯度。使用无梯度方法,我们可以验证鲁棒性是否源于模型体系结构的梯度模糊。在这项工作中,我们使用SPSA算法[48],它非常适合于高维优化问题,即使在不确定目标的情况下。我们使用[51]中的SPSA公式来产生对抗性攻击。在SPSA算法中,首先从Rademacher分布(即Bernoulli±1)中抽取一批n个样本,即
 ,然后用随机方向上的有限差分估计逼近梯度。具体来说,对于第i个样本,估计的梯度gi计算如下:
,然后用随机方向上的有限差分估计逼近梯度。具体来说,对于第i个样本,估计的梯度gi计算如下:

式中,δ是扰动大小,xt是第t次迭代时的扰动图像,f是要评估的模型。最后,SPSA对估计的梯度进行聚合,并在输入文本上执行投影梯度下降。整个过程按预先确定的迭代次数进行迭代。
- Experiments Results
第一组模型采用10步PGD对抗性训练。这些模型通常比使用30个PGD步骤(见下文)训练的模型更弱,但训练所需的时间和资源更少。图3显示了这些模型对于ImageNet测试数据集在广泛的随机靶向PGD攻击强度下的top1准确性,与ResNet-152基线相比(在对抗性训练期间也训练了10个PGD步骤)。最薄弱的模型S3TA-2只有两个注意步骤,只能发送两个查询,一个在它看到图像之前,另一个在第一步处理答案之后。这就强调了注意力瓶颈本身,而不是模型的顺序性。可以看到,瓶颈本身已经允许模型在ResNet-152基线上显著改进。通过增加注意步骤的数量,我们可以进一步提高对抗精度:展开16个步骤(S3TA-16)显著提高了稳健性-S3TA16模型比ResNet-152模型更能抵抗1000个PGD攻击步骤。事实上,在对抗性训练中使用10个PGD步骤训练的S3TA-16模型比使用30个PGD步骤训练的ResNet-152更加健壮(见图4)。这表明在攻击强度和我们允许模型具有的计算步骤之间存在一种“计算竞赛”。模型的计算步骤越多,对强攻击的防御能力就越强。超过1000个攻击步骤并不会改变图片,因为大多数模型的饱和性能接近1000个步骤。完整的结果,包括攻击成功率和名义精度,可以在表1和补充材料中找到。



我们现在来比较30步PGD对抗训练的模型。这些模型一般都要强大得多,在各种攻击强度下都能获得良好的鲁棒性结果,但需要大量的资源和时间进行训练。图4显示了S3TA16-30模型(其中-30表示训练过程中的30个PGD步骤)与ResNet-152模型相比的最高精确度,并对其进行去噪[56],后者是目前对抗稳健性方面的最新技术。可以看出,S3TA-16的性能远远优于这两种机型,为随机目标攻击奠定了新的技术水平。图5显示了到目前为止讨论的所有模型的攻击成功率。在评估防御策略时,当模型的名义精度较高且具有可比性时,测量攻击成功率是有意义的。对于这里展示的所有模型,这是正确的(见表1)。值得注意的是,这个方法的结果是:更多的注意步骤有助于降低攻击成功率,而更多的PGD步骤则有助于训练。对S3TA-16-30的攻击成功率比去噪(越低越好)低25%左右。

文献中大多数健壮性度量都是针对有目标的、基于梯度的攻击。然而,仅对目标攻击具有鲁棒性的模型弱于对非目标攻击具有鲁棒性的模型[15]。在表2中,我们使用200 PGD步骤报告针对S3TA-16-30与ResNet-152、去噪和LLR的非目标攻击的结果[43]。在这种情况下,我们的型号非常有竞争力,无论是
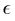 =4/255还是
=4/255还是
 =16/255。我们还探索了无梯度方法,以确保模型不会混淆梯度【51,3】。具体来说,我们使用随机目标SPSA[51],其批大小为4096,在
=16/255。我们还探索了无梯度方法,以确保模型不会混淆梯度【51,3】。具体来说,我们使用随机目标SPSA[51],其批大小为4096,在
 =16/255下迭代100次,用于无梯度攻击。我们使用迭代符号梯度[32,56]和由SPSA估计的梯度。在随机选择的1000个图像子集上的结果见表3。我们可以观察到,与基于梯度的攻击相比,SPSA并不降低准确性。这提供了一个额外的证据,证明模型的强大性能不是由于梯度掩蔽。由于SPSA的对抗精度较低(即所有模型的防御能力都优于基于梯度的方法),因此模型之间的性能差异并不是很明显。
=16/255下迭代100次,用于无梯度攻击。我们使用迭代符号梯度[32,56]和由SPSA估计的梯度。在随机选择的1000个图像子集上的结果见表3。我们可以观察到,与基于梯度的攻击相比,SPSA并不降低准确性。这提供了一个额外的证据,证明模型的强大性能不是由于梯度掩蔽。由于SPSA的对抗精度较低(即所有模型的防御能力都优于基于梯度的方法),因此模型之间的性能差异并不是很明显。

另一种确保梯度不被混淆的方法是通过可视化损失景观[43,50]。图6显示了S3TA-4和S3TA-16的损失景观俯视图。为了可视化损失景观,我们沿着线性空间改变输入,线性空间由PGD发现的更差扰动和随机方向确定。u轴和v轴分别表示在这些方向上添加的扰动的大小,z轴表示损耗。对于两个面板,菱形代表在标称图像周围投影的尺寸为16/255的L∞球。我们可以观察到,两个损失景观都相当平滑,这提供了一个额外的证据,证明强劲的表现不是因为梯度模糊。
最近一个有趣的数据集是“自然对抗性例子”[23]。该数据集由来自ImageNet的200个类的一个子集的自然图像组成。选择这些图像时,即使没有对图像进行实际的修改,也会导致现代图像分类人员以较高的可信度对图像进行错误分类。图像通常包含不寻常位置的物体,从不寻常的角度拍摄,或以各种方式被遮挡或损坏。我们比较了一个S3TA-16模型去噪,ResNet基线和“挤压和激励”[27](ResNet+SE)的变化在原来的报告。图7显示了使用本文中所用测量方法得出的结果:Top-1精度、测量每个模型的可信度与其实际误差率之间差异的校准误差、允许计算精度的AURRA,同时给分类者一个机会,如果他们在预测中不满意的话,可以弃权。


图8显示了几个生成的敌对的例子对手训练的S3TA模型(带4个展开步骤)和对手训练的ResNet-152的不同攻击强度示例。我们观察到,生成的图像通常(但肯定不总是)包含与目标类相关的显著结构。然而,尽管对于ResNet示例来说,这些扰动的性质充其量是局部的,但是对于S3TA全局的、一致的和人类感兴趣的结构出现了。这为我们模型的内部推理过程提供了一些线索,暗示它以一种连贯的方式在全球、跨空间进行推理。重要的是要注意,在许多情况下,对手的例子似乎不包含任何显著的结构(即使有许多攻击步骤)。它们在训练模型的中途出现的频率要高得多,而模型已经是一个很好的分类,但还没有达到鲁棒性的顶峰。在训练接近尾声时,似乎很难产生这些,可能是模型学习的防御策略的一部分。关于训练中途生成的一些示例以及更多可见和不可见的扰动图像,请参见补充材料。了解这些例子在什么情况下出现,留给以后的研究。 由于注意力是我们模型中不可或缺的一部分,所以我们可以看到当网络受到攻击并对图像进行错误标记时,它是否起到了作用。我们可以可视化每个时间步骤生成的注意力图,并查看在不同攻击场景下如何使用注意力。图9显示了用于攻击S3TA-16模型的图像的这种注意地图。注意力叠加在原始图像上-突出显示的区域比深色区域更受关注。可以看到,攻击可以产生刺激,吸引一些注意力离开图像中的主要对象,在这种情况下,朝向与背景中的目标类稍微相似的对象。

- Conclusions
在本文中,我们证明了一个由灵长类视觉系统启发的递归注意模型能够实现对随机目标对抗攻击的最新鲁棒性。允许更多的注意步骤可以提高在更强攻击下的准确性。我们证明,由此产生的对抗性例子通常(但并不总是)包含了对人类观察者可见和可解释的全局结构。为什么在攻击像这样的模特?
我们假设有两个因素。注意机制从图像的大部分集中数据,这意味着梯度在整个图像中迅速传播,而不仅仅是局部的。此外,由于模型展开了几个步骤,图像的更多部分可能会受到关注,因此梯度可能会在那里传播。
我们看到了这一点的证据,事实上攻击者通常会将注意力从图像中的主要对象吸引开,暗示着注意力在攻击策略中起着至关重要的作用。
在复杂的数据集中,要实现对抗性的健壮性还有很多工作要做。即使是像所提出的模型,当攻击者足够强大时,也常常失败,而且与名义精度相比,性能仍然很低,但是在某一点上,我们可能会问-如果一个图像被足够的干扰,以至于它与原始图像不相似,并且看起来像来自目标类的另一个图像,这仍然是有效的对抗性干扰吗?像这里展示的模型可能会让我们在未来到达这一前沿。
- 点赞
- 收藏
- 分享
- 文章举报
 wujianming_110117
发布了96 篇原创文章 · 获赞 5 · 访问量 5413
私信
关注
wujianming_110117
发布了96 篇原创文章 · 获赞 5 · 访问量 5413
私信
关注

- CVPR 2020 三篇有趣的论文解读
- CVPR 2019 论文解读 | 基于多级神经纹理迁移的图像超分辨方法 (Adobe Research)
- CVPR2020最全整理:论文汇总 Github源码、论文解读等(按方向划分,0303更新中)
- ECAI 2016论文精选 | 图像分类的随机分布特征
- 深度学习之图像分类模型Cifar10数据集解读
- 深度学习之图像分类模型inception v2、inception v3解读
- ICCV2017 论文解读:基于图像检索的行人重识别 | PaperDaily #13
- [caffe]深度学习之图像分类模型googlenet[inception v1]解读
- CVPR 论文阅读与翻译2:图像检索、哈希编码学习、深度哈希:Deep Learning of Binary Hash Codes for Fast Image Retrieval-2015
- CVPR 2017论文:基于网格的运动统计,用于快速、超鲁棒的特征匹配(附大神解读)
- CVPR 2018 Convolutional Sequence to Sequence Model for Human Dynamics 论文解读
- CVPR 2016 Structural-RNN: Deep Learning on Spatio-Temporal Graphs 论文解读
- 深度学习的图像分类、检测领域:2010-2016年被引用次数最多的论文
- KDD 2019论文解读:多分类下的模型可解释性
- CVPR 2019 论文解读 | 小样本域适应的目标检测
- 图像分类模型AlexNet解读
- [caffe]深度学习之图像分类模型Batch Normalization[BN-inception]解读
- [caffe]深度学习之图像分类模型AlexNet解读
- [caffe]深度学习之图像分类模型VGG解读
- CVPR 2019 论文解读 | 具有高标签利用率的图滤波半监督学习方法