Softmax与分类模型学习笔记
softmax和分类模型内容:
softmax回归的基本概念
获取Fashion-MNIST数据集和读取数据
softmax回归模型的从零开始实现,实现一个对Fashion-MNIST训练集中的图像数据进行分类的模型
使用pytorch实现softmax回归模型
softmax回归的基本概念
分类问题
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。
图像中的4像素分别记为 x1, x2, x3, x4。
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为 y1,y2,y3 。
我们通常使用离散的数值来表示类别,例如 y1=1,y2=2,y3=3 。
权重矢量
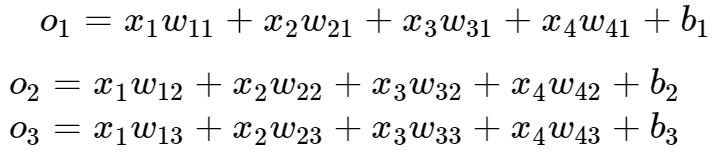
神经网络图
下图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出 o1,o2,o3 的计算都要依赖于所有的输入 x1,x2,x3,x4 ,softmax回归的输出层也是一个全连接层。
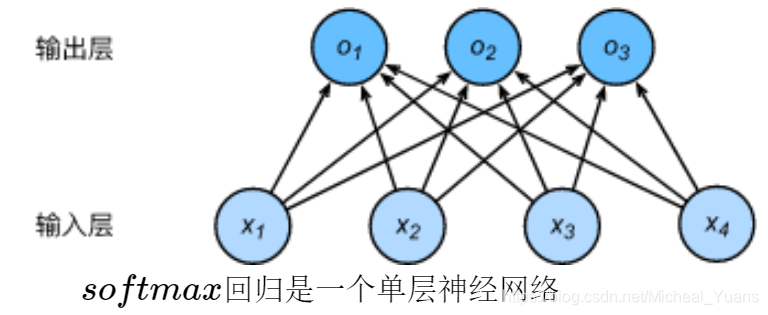
既然分类问题需要得到离散的预测输出,一个简单的办法是将输出值 oi 当作预测类别是 i 的置信度,并将值最大的输出所对应的类作为预测输出,即输出 argmaxioi 。例如,如果 o1,o2,o3 分别为 0.1, 10, 0.1 ,由于 o2 最大,那么预测类别为2,其代表猫。
输出问题
直接使用输出层的输出有两个问题:
一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果 o1=o3=10^3 ,那么输出值10却又表示图像类别为猫的概率很低。
另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
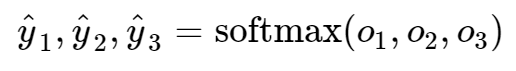 其中:
其中:
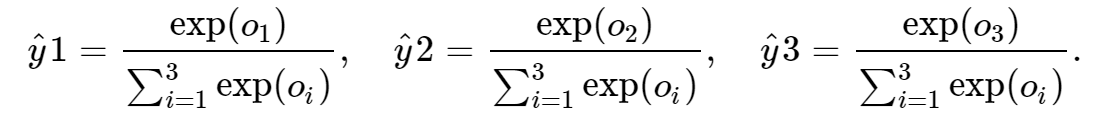
可知以上三项均属于(0, 1),且三项之和为1,这就构成了一个概率分布。并且,softmax不改变各项的相对大小,进而不改变原有输出。
交叉熵损失函数
相比于之前严格的均方误差损失函数,我们更需要一种衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:

交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。当然,遇到一个样本有多个标签时,例如图像里含有不止一个物体时,我们并不能做这一步简化。但即便对于这种情况,交叉熵同样只关心对图像中出现的物体类别的预测概率。
假设训练数据集的样本数为 n ,交叉熵损失函数定义为:

其中函数变量代表模型参数的集合。
模型训练和预测
在训练好softmax回归模型后,给定任一样本特征,就可以预测每个输出类别的概率。通常,我们把预测概率最大的类别作为输出类别。如果它与真实类别(标签)一致,说明这次预测是正确的。我们将使用准确率(accuracy)来评价模型的表现,它等于正确预测数量与总预测数量之比。
获取Fashion-MNIST数据集和读取数据
在介绍softmax回归的实现前先引入一个多类图像分类数据集,它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST[1]。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST[2]。
这里我们使用torchvision包,它是服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision主要由以下几部分构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
softmax回归模型的从零开始实现
import torch
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
print(torchvision.__version__)
# 获取训练集数据和测试集数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 模型参数初始化
num_inputs = 784
print(28*28)
num_outputs = 10
W = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_outputs)), dtype=torch.float)
b = torch.zeros(num_outputs, dtype=torch.float)
W.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
# 对多维Tensor按维度操作
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(X.sum(dim=0, keepdim=True)) # dim为0,按照相同的列求和,并在结果中保留列特征
print(X.sum(dim=1, keepdim=True)) # dim为1,按照相同的行求和,并在结果中保留行特征
print(X.sum(dim=0, keepdim=False)) # dim为0,按照相同的列求和,不在结果中保留列特征
print(X.sum(dim=1, keepdim=False)) # dim为1,按照相同的行求和,不在结果中保留行特征
# 定义softmax
def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(dim=1, keepdim=True)
# print("X size is ", X_exp.size())
# print("partition size is ", partition, partition.size())
return X_exp / partition # 这里应用了广播机制
X = torch.rand((2, 5))
X_prob = softmax(X)
print(X_prob, '\n', X_prob.sum(dim=1))
# softmax回归模型
def net(X):
return softmax(torch.mm(X.view((-1, num_inputs)), W) + b)
# 定义损失函数
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = torch.LongTensor([0, 2])
y_hat.gather(1, y.view(-1, 1))
def cross_entropy(y_hat, y):
return - torch.log(y_hat.gather(1, y.view(-1, 1)))
# 定义准确率
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
print(accuracy(y_hat, y))
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
print(evaluate_accuracy(test_iter, net))
# 训练模型
num_epochs, lr = 5, 0.1
# 本函数保存在d2lzh_pytorch包中方便以后使用
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
模型预测
X, y = iter(test_iter).next() true_labels = d2l.get_fashion_mnist_labels(y.numpy()) pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy()) titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)] d2l.show_fashion_mnist(X[0:9], titles[0:9])
使用pytorch实现softmax回归模型
# 加载各种包或者模块
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
# 初始化参数和获取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 定义网络模型
num_inputs = 784
num_outputs = 10
class LinearNet(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(LinearNet, self).__init__()
self.linear = nn.Linear(num_inputs, num_outputs)
def forward(self, x): # x 的形状: (batch, 1, 28, 28)
y = self.linear(x.view(x.shape[0], -1))
return y
# net = LinearNet(num_inputs, num_outputs)
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x 的形状: (batch, *, *, ...)
return x.view(x.shape[0], -1)
from collections import OrderedDict
net = nn.Sequential(
# FlattenLayer(),
# LinearNet(num_inputs, num_outputs)
OrderedDict([
('flatten', FlattenLayer()),
('linear', nn.Linear(num_inputs, num_outputs))]) # 写成自定义的 LinearNet(num_inputs, num_outputs) 也可以
)
# 初始化模型参数
init.normal_(net.linear.weight, mean=0, std=0.01)
init.constant_(net.linear.bias, val=0)
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 函数原型
# class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
# 优化函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
# 函数原型
# class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)
# 训练
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
- 点赞
- 收藏
- 分享
- 文章举报
 Ray Mond
发布了2 篇原创文章 · 获赞 0 · 访问量 80
私信
关注
Ray Mond
发布了2 篇原创文章 · 获赞 0 · 访问量 80
私信
关注

- Task1.0 学习笔记线性回归;Softmax与分类模型、多层感知机
- ElitesAI·动手学深度学习PyTorch版学习笔记-线性回归;Softmax与分类模型、多层感知机
- DL学习笔记【15】使用训练好的模型得到分类结果
- 《动手学深度学习》笔记 Task01:线性回归;Softmax与分类模型、多层感知机
- TensorFlow学习Day3读取csv文件,动手写个logistic,softmax分类模型
- 深度学习笔记三:单神经元二分类模型图的构建
- TensorFlow学习笔记:构建多分类任务模型(未完)
- 《动手学深度学习》笔记 Task01 线性回归;Softmax与分类模型、多层感知机
- PowerDesigner 15学习笔记:十大模型及五大分类
- tensorflow 学习笔记(十二)- 用别人训练好的模型来进行图像分类
- 机器学习笔记(IX)线性模型(V)多分类学习
- 动手学深度学习-线性回归;Softmax与分类模型;多层感知机
- 【theano-windows】学习笔记九——softmax手写数字分类
- Spark学习笔记——构建分类模型
- 动手学深度学习 线性回归-Softmax与分类模型-多层感知机
- pytorch学习——Softmax与分类模型
- 【机器学习】python实践笔记 -- 经典监督学习模型之分类学习模型
- 《动手学深度学习》组队学习打卡Task1——softmax和分类模型
- tensorflow学习-示例1(MNIST数据集合上的softmax分类模型)
- Spark.MLlib之线性分类模型学习笔记