Hadoop2.7.6 完全分布搭建
centos7.5 hadoop2.7.6 完全分布搭建
一、 准备3台客户机(master,slave1,slave2)
关闭防火墙 三台机器都要
systemctl stop firewalld.service 关闭防火墙 systemctl disable firewalld.service 永久关闭防火墙
如果不关,Hadoop搭建好上传文件,上传不了 ,可能会报这样的错:
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/a.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s) are excluded in this operation.
详情见博客:https://blog.csdn.net/weixin_43719703/article/details/102525972
1、修改主机名gedit /etc/hostname (主机名)
gedit 可以换成 vim
2、设置静态IP(每台主机都要配置)
系统默认使用的是DHCP动态获取IP地址,为了方便集群机器之间相互通信,要设置静态ip地址。并修改主机名称
(1)修改/etc/sysconfig/network-scripts/ifcfg-eth0,如果不确定自己的网卡信息,可以使用ifconfig命令查看

(2) 编辑 gedit /etc/hosts
加入三台主机的 IP + 主机名
设置完三台机子的IP之后,在任意一台机子ping ip地址 看看是否能够ping通
二、SSH免密钥登录配置(重点)
大数据集群中的Linux主机之间需要频繁的通信,但是Linux在互相通信中需要进行用户身份认证们也就是输入密码。在集群不大的情况下,每次登录少量计算机进行输入密码认证,所需要的操作时间尚且不多。但是,如果集群是几十台、上百台,频繁的认证就会大大降低工作效率,因此,实际生产中的集群都需要进行面密钥登录配置。默认状态下,SSH连接是需要密码认证的,但是可以通过修改系统认证,使系统通信免除密码输入和SSH认证。
1、进入到home目录(如果没有.ssh目录,则使用ssh命令连接一次其他主机就会生成)
cd ~/.ssh
生成公钥和私钥对:
在命令行输入: ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、 id_rsa.pub(公钥)
代码参数含义:
-t 指定密钥类型,默认是 rsa ,可以省略。
-C 设置注释文字。
-f 指定密钥文件存储文件名。

2、复制公钥 cp id_rsa.pub authorized_keys
**3、 将公钥拷贝到要免密登录的目标机器和自己机器
**ssh-copy-id作用: 将本机的公钥复制到远程机器的authorized_keys文件中,ssh-copy-id也能让你有到远程机器的home, ~./ssh , 和~/.ssh/authorized_keys的权利。
ssh-copy-id -i .ssh/id_rsa.pub root@IP地址(或者主机名)
注:ssh-copy-id -i 是最简单的办法,如果不用这个,就得分二个步骤:
ssh-copy-id作用: 将本机的公钥复制到远程机器的authorized_keys文件中,ssh-copy-id也能让你有到远程机器的home, ~./ssh , 和~/.ssh/authorized_keys的权利
a) 先scp将本机的id_rsa.pub复制到对方机器的.ssh目录下
b) 在对方机器上执行 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 导入公钥
4、给权限(每台机子都要)
chmod -R 700 ~/.ssh
cd ~/.ssh
chmod 600 authorized_keys
5、验证
ssh localhost(或者某个 主机名、IP地址)
ssh配置成功 如图:

没有提示输入密码则表示本机无密钥登录成功,如果此步不成功,后续启动hdfs脚本会要求输入密码
6、将authorized_keys文件传给其他机器

**ssh文件夹下的文件功能解释** (1)~/.ssh/known_hosts :记录ssh访问过计算机的公钥(public key) (2)id_rsa :生成的私钥 (3)id_rsa.pub :生成的公钥 (4)authorized_keys :存放授权过得无秘登录服务器公钥
三、 配置jdk
jdk 下载网址 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下好了,复制到虚拟机某个目录底下,然后解压 tar -zxvf 你放的目录/压缩包
配置环境
编辑 /etc/profile 加入
JAVA_HOEM=你解压的目录
PATH=$JAVA_HOEM/bin
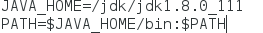
source /etc/profile
输入命令 jps 成功出现说明成功(或者Java -version)

注:centos自带jdk,Java -version 出来的的版本跟你自己装的可能不一样,只要指定你装的jdk路径就可以了,如果想要卸载,可以自己百度一下。
四、配置Hadoop,然后将master的hadoop文件传送给slave节点
1、下载hadoop 2.7.6 http://archive.apache.org/dist/hadoop/core/hadoop-2.7.6/
2、解压 tar -zxvf 压缩包名字
3、在/etc/profile 中配置路径HADOOP_HOME

4、
(1)配置文件:hadoop-env.sh(文件都在(自己解压的Hadoop目录/etc/hadoop中)
修改JAVA_HOME值(export JAVA_HOME=与profile文件中的jave_home一致)
(2)配置文件:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=与profile文件中的jave_home一致)
(3)配置文件:slaves
slaves文件是Hadoop集群的Slave节点列表,集群启动的时候根据该列表启动集群中的节点。该文件中可以配置主机名也可以配置ip地址
这里就是:
slave1
slave2
(4)配置配置核心组件文件:core-site.xml
<configuration> /*这里的值指的是默认的HDFS路径*/ <property> <name>fs.defaultFS</name> <value>hdfs://IP(或者主机名):9000</value> </property> /*临时文件夹路径*/ <property> <name>hadoop.tmp.dir</name> <value>file:/hadoop-2.7.6/tmp</value> <description>Abase for other temporary directories. </description> </property> /*缓冲区大小:io.file.buffer.size默认是4KB*/ /* <property> <name>io.file.buffer.size</name> <value>131072</value> </property> */ </configuration>
(5)配置文件系统: hdfs-site.xml
<configuration> /*配置主节点名和端口号*/ <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> /*配置从节点名和端口号*/ <property> <name>dfs.namenode.name.dir</name> <value>/hadoop/hadopp-2.7.6/hdfs/namenode</value>(目录都是自己想放的地方,最好放在Hadoop目下) </property> /*配置datanode的数据存储目录*/ <property> <name>dfs.datanode.data.dir</name> <value>/hadoop/hadopp-2.7.6/hdfs/datanode</value> </property> /*配置副本数*/ <property> <name>dfs.replication</name> <value>3</value> </property>
这里的dfs.replication是HDFS数据块的副本数,系统默认值是3,超过3的数是没有意义的,因为HDFS的最大副本数就是3
(6) 配置MapReduce计算框架文件
在hadoop-2.7.6/etc/hadoop子目录下,系统已经有了一个mapred-site.xml.template文件,我们需要将其复制并改名,命令是“cp ~/hadoop-2.7.6/etc/hadoop/mapred-site.xml.template ~/hadoop-2.7.6/etc/hadoop/mapred-site.xml <configuration> /*hadoop对map-reduce运行框架一共提供了3种实现,在mapred-site.xml中通过"mapreduce.framework.name"这个属性来设置为"classic"、"yarn"或者"local"*/ <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> /*<property> <name>mapred.job.tracker</name> <value>ip或者主机名:9002</value> <!-- Default Port: 9001. --> </property> */
(7) 配置yarn-site.xml文件

注意:IP或者主机名要统一
至此,master节点配置完毕,其余slave节点可以用scp命令将hadoop安装文件,profile文件复制到各个主机,最好各个slave节点的profile文件手动进行配置,配置信息参照master节点的profile文件。
scp -r /hadoop root@slave1:/hadoop
scp -r /hadoop root@slave2:/hadoop
**
slave 节点的Hadoop、jdk目录与 master 一致
**
五、 Hadoop集群的启动
1、 格式化文件系统(只需在master节点执行一次)
在master节点上使用如下命令格式化:
source /etc/profile
hdfs namenode -format
如果没有出现错误信息,则说明格式化成功。如果格式化失败,需要重新格式化

2、启动和关闭Hadoop
完成格式化后即可启动Hadoop了,可以使用sbin子目录下的start-all.sh命令启动Hadoop集群;

Hadoop系统建议放弃使用start-all.sh和stop-all.sh一类的命令,而改用start-dfs.sh和start-yarn.sh命令。
3、验证Hadoop集群是否启动成功
主节点:
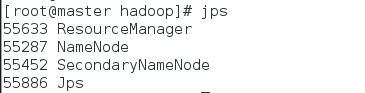
slave节点:

Hadoop 命令验证
hdfs dfs -put ' /root/aa.txt' / 注意: aa.txt是自己在/root目录下创建的文件 如果上传成功则Hadoop配置成功
用自己的IP+50070,可以查看

最后可以使用 hdfs dfs -mkdir /user 看看是否能创建目录
- 点赞
- 收藏
- 分享
- 文章举报
 szjmsww
发布了5 篇原创文章 · 获赞 0 · 访问量 134
私信
关注
szjmsww
发布了5 篇原创文章 · 获赞 0 · 访问量 134
私信
关注

- [Script] Hadoop使用docker搭建完全分布模式环境的脚本
- hadoop +hbase +zookeeper 完全分布搭建
- Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
- hadoop +hbase +zookeeper 完全分布搭建 (版本一)
- hadoop +hbase +zookeeper 完全分布搭建 (版本二
- Hadoop-2.5.0-cdh5.3.2/5.2.0 搭建完全分布(离线 tar 包安装)
- Hadoop生态圈(二) -- 完全分布搭建
- Hadoop手把手逐级搭建,从单机伪分布到高可用+联邦(2)Hadoop完全分布式(full)
- Hadoop手把手逐级搭建,从单机伪分布到高可用+联邦(2)Hadoop完全分布式(full)
- hadoop +hbase +zookeeper 完全分布搭建 (版本一)
- Centos6.5 Hadoop完全分布集群搭建详解
- unbunt搭建hadoop2.7.6完全分布式集群
- Hadoop完全分布集群搭建
- hadoop2.4.1完全分布集群搭建
- [虚拟机VM][Ubuntu12.04]搭建Hadoop完全分布式环境(三)(终篇)
- Ubuntu系统下Hadoop伪分布模式及eclipse环境搭建
- hadoop 2.5.2 完全分布式集群环境搭建 (3)
- hadoop3.0 伪分布环境搭建(学习使用)
- VBox下CentOS的hadoop伪分布环境的搭建(四)
- hadoop完全分布式集群搭建