VBox下CentOS的hadoop伪分布环境的搭建(四)
2012-06-15 22:38
567 查看
一 hadoop安装及配置
上一章在ssh无密码验证,联网,jdk安装以及java环境变量的设置都ok了以后接下来就是安装hadoop了,我的hadoop的版本是hadoop-1.0.1.tar.gz,我把它放在/opt/Hadoop目录下,接着敲入命令tar xzvf Hadoop-1.0.1.tar.gz解压该文件,然后在Hadoop目录下会发现出现了hadoop-1.0.1文件夹。
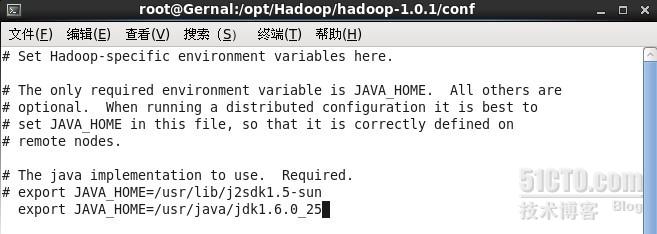
接下来就是hadoop的配置。进入hadoop-1.0.1,然后找到conf文件夹,接下来的要设置的文件都在该文件夹内,首先找到hadoop-env.sh,这是一个bash脚本,记录着运行Hadoop脚本中使用的环境变量,我们需要修改这里的JAVA_HOME,将其指向我们的JDK安装路径,代码如下。
接着设置core-site.xml文件,在该文件里<configuration></configuration>之间添加如下代码
<property>
<name>fs.default.name</name>
<value>hdfs://Gernal.lee:9000/</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/opt/Hadoop/Hadooptmp</value>
</property>
其中“fs.default.name”是HDFS文件系统的URL,指定HDFS的NameNode和默认文件系统,如上所述,本文定为Gernal.lee虚拟机。“Hadoop.tmp.dir”是HDFS的存储目录。
保存退出,接着设置hdfs-site.xml文件,在该文件里<configuration></configuration>之间添加如下代码
<property>
<name>dfs.name.dir</name>
<value>/opt/Hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/Hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
这是HDFS后台程序设置的配置文件。其中,“dfs.name.dir”是存储NameNode永久元数据的目录列表,“dfs.data.dir”是DataNode存储块的目录的列表。“dfs.replication”是块的副本数,这里的数字也就意味着备份的个数。
保存退出,接着设置mapred-site.xml文件(MapReduce后台程序设置的设置),在该文件里<configuration></configuration>之间添加如下代码
<property>
<name>mapred.job.tracker</name>
<value>Gernal.lee:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/Hadoop/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/opt/Hadoop/mapred/system</value>
</property>
“mapred.job.tracker”指定用来作为JobTracker的节点,我们设为Gernal.lee虚拟机,冒号后面的“9001”是端口号,“mapred.system.dir”是MapReduce系统目录,“mapred.local.dir”是MapReduce的临时目录。
接着就是主从设置,首先我在/etc目录下修改hosts文件,修改如图

打开/opt/Hadoop/hadoop-1.0.1/conf目录下的masters文件,在文件里写入主机为Gernal.lee,同目录下的slaves文件则相应的改成Soldier.one。万事俱备了,我们接着准备启动hadoop吧,紧张^_^
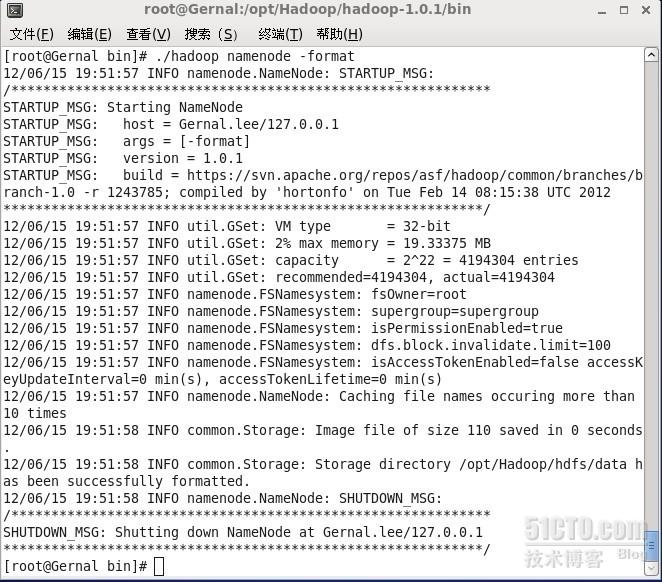
在启动hadoop之前,首先得先格式化namenode,在/opt/Hadoop/hadoop-1.0.1/bin目录下敲入命令./hadoop fs -format,启动格式化。
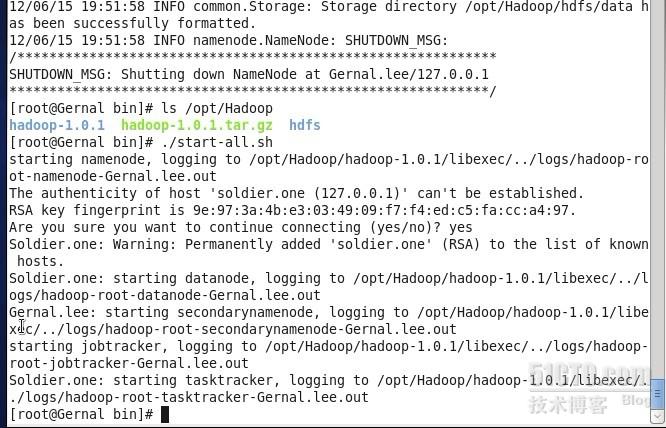
格式化完,我们就可以启动hadoop了,同样在该目录下敲入命令./start-all.sh
NameNode生成“Hadooptmp”文件夹,DataNode生成“hdfs”和“mapred”文件夹。在浏览器上访问“http://father:50070”和“http://father:50030”可以通过Hadoop的webUI查看NameNode和JobTracker的情况,如下就是NameNode情况在网页上的显示
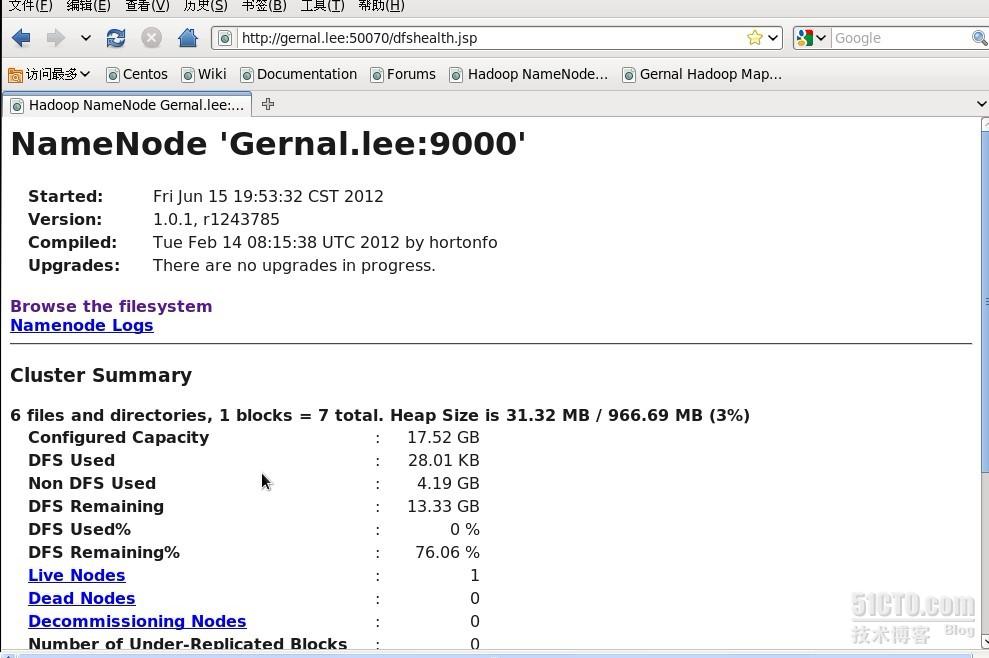
至此,伪分布hadoop的环境搭建好了,接下来就是验证该集群是否可以正常工作。
二 单词计数例子WordCount在hadoop下实现
hadoop官方提供了WordCount的java源程序,主要用于检测hadoop集群是否能正常工作,我下载了WordCount的java源程序,然后把它放在/home/Gernal.lee/WordCount的目录下,接着在终端下敲入命令javac -classpath /opt/Hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jar /home/Gernal.lee/WordCount/WordCount.java -d /home/Gernal.lee/WordCount,然后在/home/Gernal.lee/WordCount目录下将会编译出三个.class文件(分别是WordCount.class、WordCount$MapClass.class 、WordCount$Reduce.class),接着敲入命令jar cvf WordCount.jar *.class将三个.class文件打包成一个.jar文件,于是在该目录下就生成了一个WordCount.jar文件,把该文件复制到/opt/Hadoop/hadoop-1.0.1/lib目录下
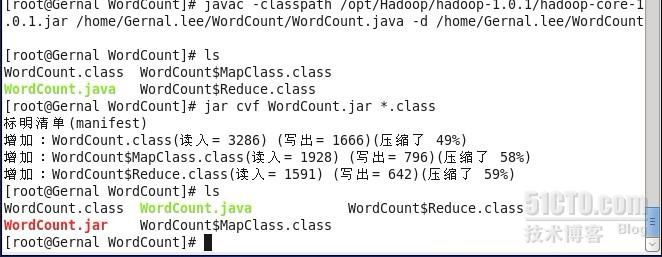
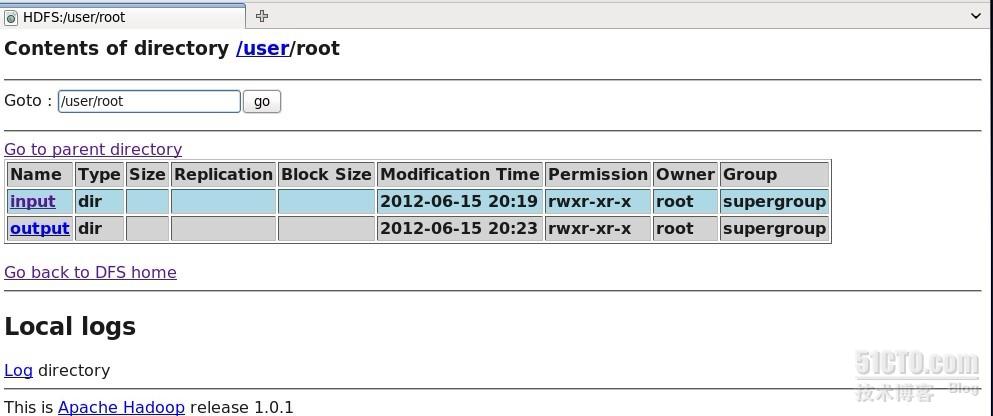
接着在hadoop的hdfs文件系统上新建一个input文件夹

同时在本地bin目录下新建两个txt文件file1.txt和file2txt,并在这两个文件里写入相应内容,接着把这两个本地文件上传到hdfs文件夹input上,如图
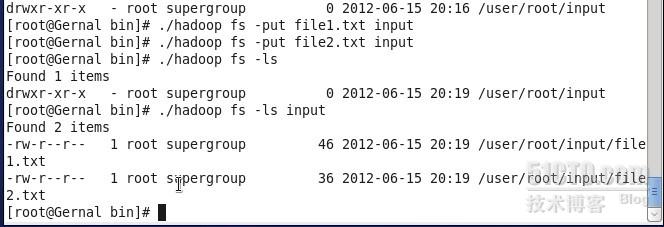
此时在网页上也可以看到input文件夹以及file1.txt和file2.txt的内容,如图
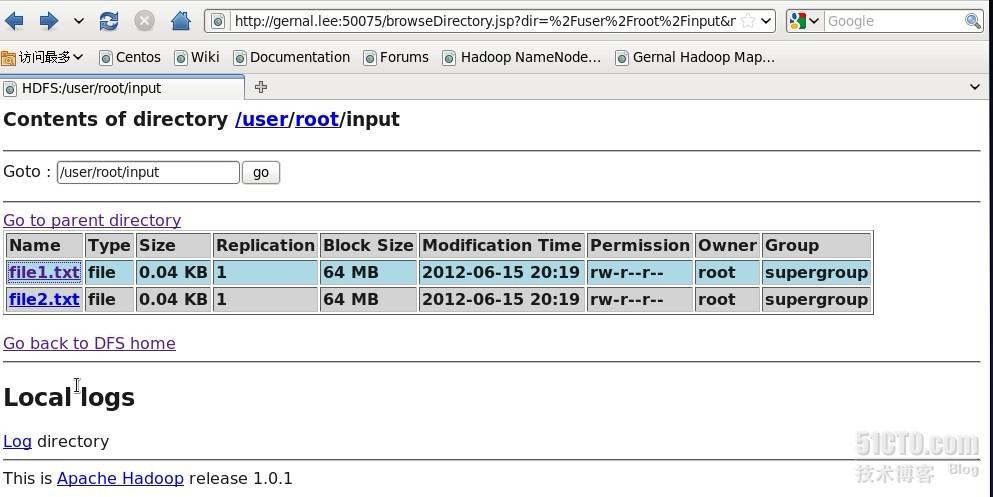
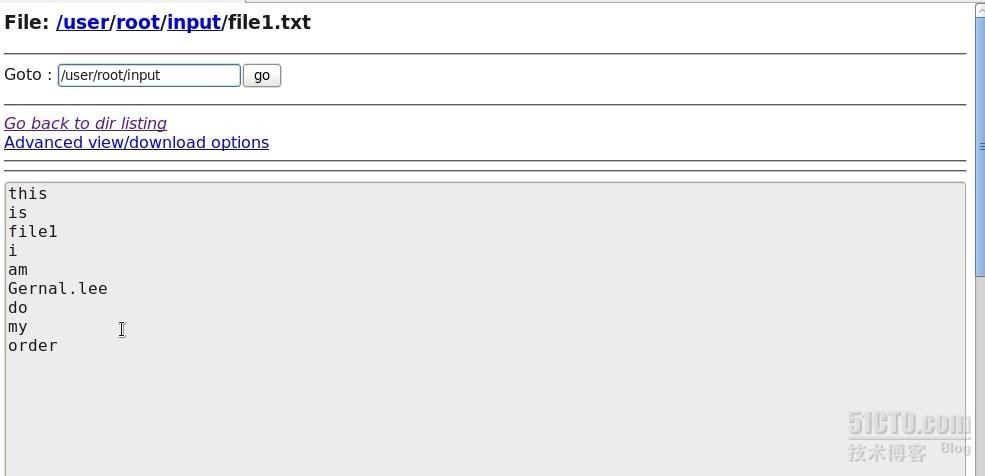
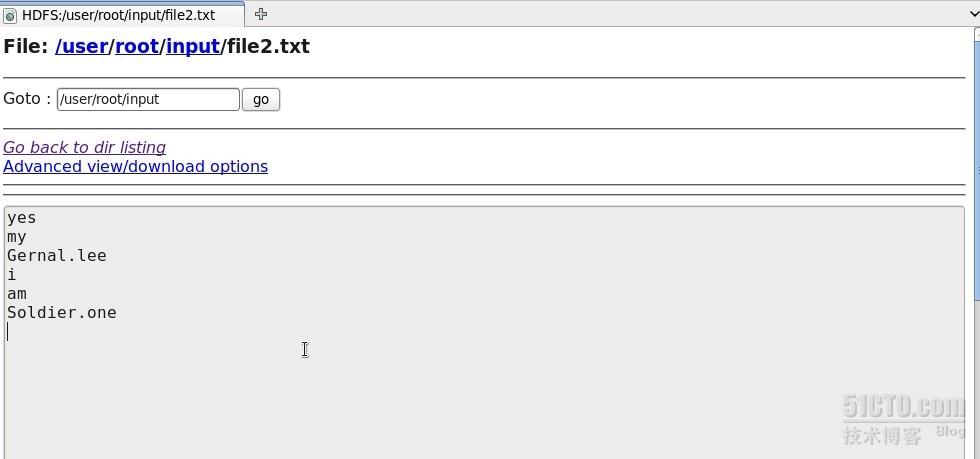
最后在/opt/Hadoop/hadoop-1.0.1/bin目录下敲入命令./hadoop jar ../lib/Count.jar WordCount input output,即hadoop集群开始工作,结果输出到output文件上,该文件可以从网页上查看结果。
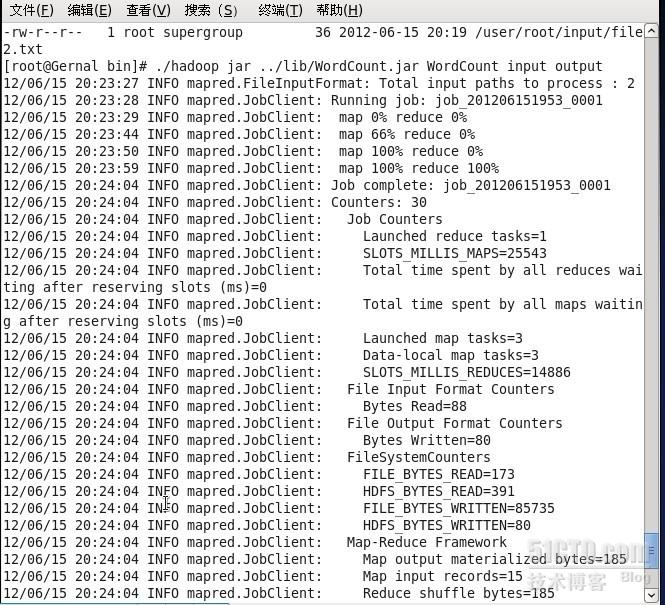
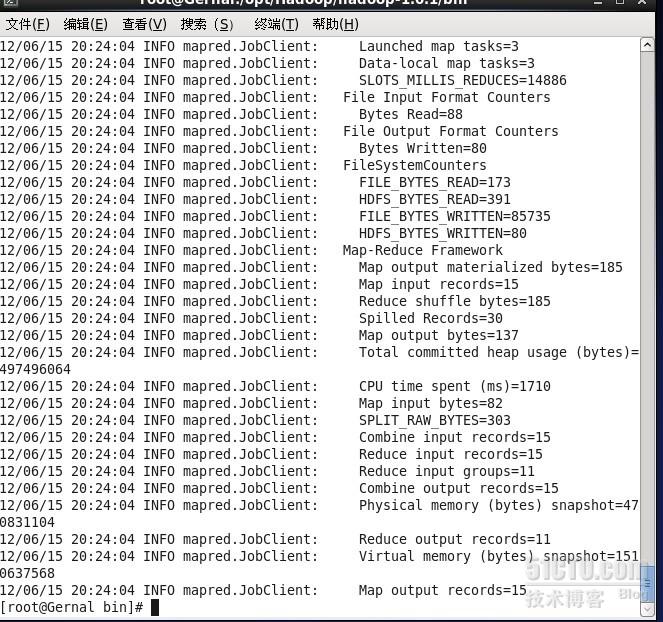
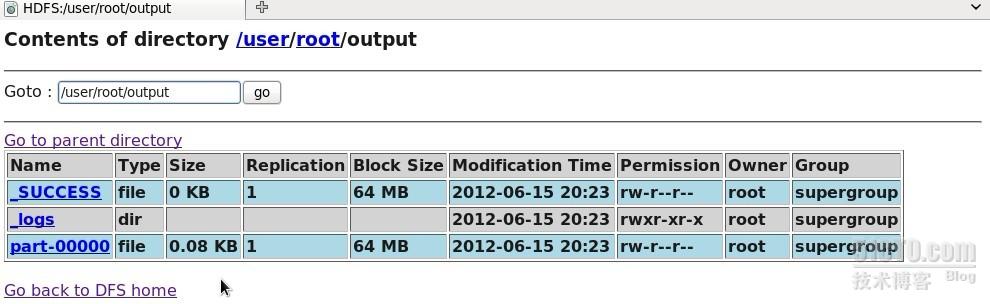
结果在part-000000里保存,在网页上打开该文件,显示如下
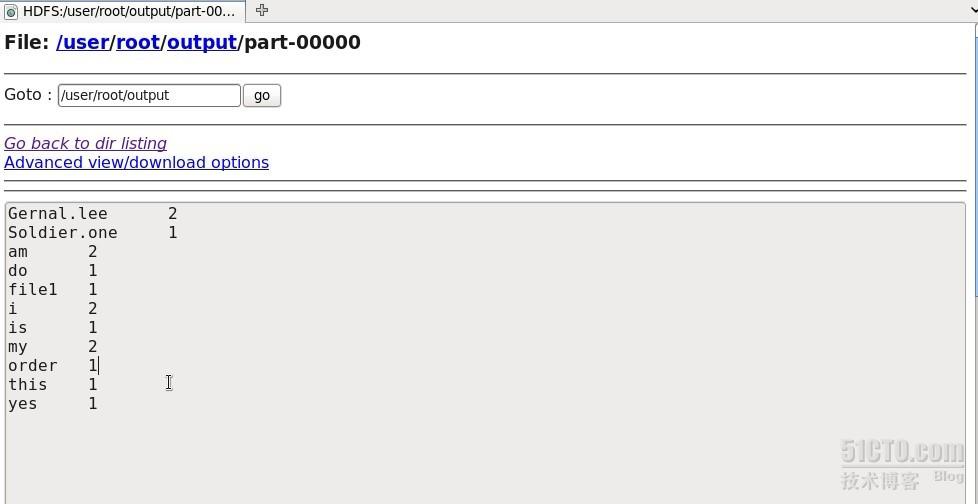
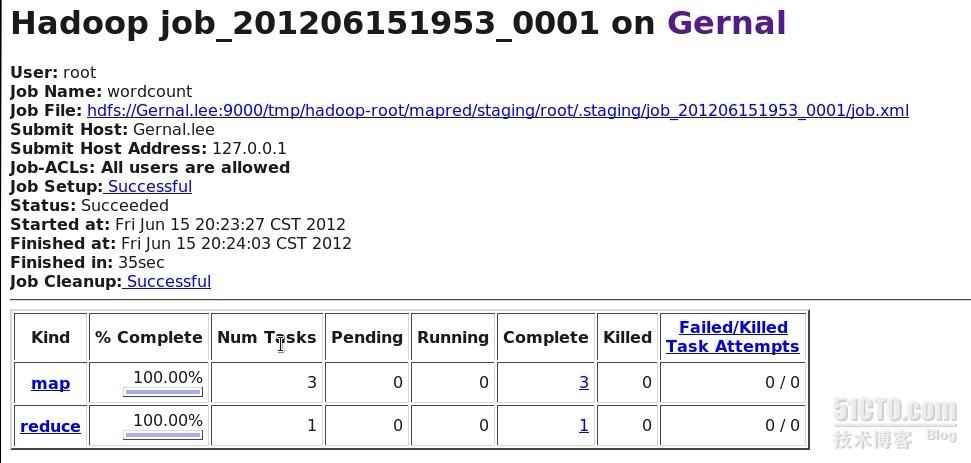
结果显示,该伪分布式hadoop集群工作正常,从网页上也可以看出来^_^
本文出自 “在路上” 博客,请务必保留此出处http://imiron.blog.51cto.com/5118978/899854
上一章在ssh无密码验证,联网,jdk安装以及java环境变量的设置都ok了以后接下来就是安装hadoop了,我的hadoop的版本是hadoop-1.0.1.tar.gz,我把它放在/opt/Hadoop目录下,接着敲入命令tar xzvf Hadoop-1.0.1.tar.gz解压该文件,然后在Hadoop目录下会发现出现了hadoop-1.0.1文件夹。
接下来就是hadoop的配置。进入hadoop-1.0.1,然后找到conf文件夹,接下来的要设置的文件都在该文件夹内,首先找到hadoop-env.sh,这是一个bash脚本,记录着运行Hadoop脚本中使用的环境变量,我们需要修改这里的JAVA_HOME,将其指向我们的JDK安装路径,代码如下。
export JAVA_HOME=/usr/java/jdk1.6.0_25
接着设置core-site.xml文件,在该文件里<configuration></configuration>之间添加如下代码
<property>
<name>fs.default.name</name>
<value>hdfs://Gernal.lee:9000/</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/opt/Hadoop/Hadooptmp</value>
</property>
其中“fs.default.name”是HDFS文件系统的URL,指定HDFS的NameNode和默认文件系统,如上所述,本文定为Gernal.lee虚拟机。“Hadoop.tmp.dir”是HDFS的存储目录。
保存退出,接着设置hdfs-site.xml文件,在该文件里<configuration></configuration>之间添加如下代码
<property>
<name>dfs.name.dir</name>
<value>/opt/Hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/Hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
这是HDFS后台程序设置的配置文件。其中,“dfs.name.dir”是存储NameNode永久元数据的目录列表,“dfs.data.dir”是DataNode存储块的目录的列表。“dfs.replication”是块的副本数,这里的数字也就意味着备份的个数。
保存退出,接着设置mapred-site.xml文件(MapReduce后台程序设置的设置),在该文件里<configuration></configuration>之间添加如下代码
<property>
<name>mapred.job.tracker</name>
<value>Gernal.lee:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/Hadoop/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/opt/Hadoop/mapred/system</value>
</property>
“mapred.job.tracker”指定用来作为JobTracker的节点,我们设为Gernal.lee虚拟机,冒号后面的“9001”是端口号,“mapred.system.dir”是MapReduce系统目录,“mapred.local.dir”是MapReduce的临时目录。
接着就是主从设置,首先我在/etc目录下修改hosts文件,修改如图
打开/opt/Hadoop/hadoop-1.0.1/conf目录下的masters文件,在文件里写入主机为Gernal.lee,同目录下的slaves文件则相应的改成Soldier.one。万事俱备了,我们接着准备启动hadoop吧,紧张^_^
在启动hadoop之前,首先得先格式化namenode,在/opt/Hadoop/hadoop-1.0.1/bin目录下敲入命令./hadoop fs -format,启动格式化。
格式化完,我们就可以启动hadoop了,同样在该目录下敲入命令./start-all.sh
NameNode生成“Hadooptmp”文件夹,DataNode生成“hdfs”和“mapred”文件夹。在浏览器上访问“http://father:50070”和“http://father:50030”可以通过Hadoop的webUI查看NameNode和JobTracker的情况,如下就是NameNode情况在网页上的显示
至此,伪分布hadoop的环境搭建好了,接下来就是验证该集群是否可以正常工作。
二 单词计数例子WordCount在hadoop下实现
hadoop官方提供了WordCount的java源程序,主要用于检测hadoop集群是否能正常工作,我下载了WordCount的java源程序,然后把它放在/home/Gernal.lee/WordCount的目录下,接着在终端下敲入命令javac -classpath /opt/Hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jar /home/Gernal.lee/WordCount/WordCount.java -d /home/Gernal.lee/WordCount,然后在/home/Gernal.lee/WordCount目录下将会编译出三个.class文件(分别是WordCount.class、WordCount$MapClass.class 、WordCount$Reduce.class),接着敲入命令jar cvf WordCount.jar *.class将三个.class文件打包成一个.jar文件,于是在该目录下就生成了一个WordCount.jar文件,把该文件复制到/opt/Hadoop/hadoop-1.0.1/lib目录下
接着在hadoop的hdfs文件系统上新建一个input文件夹
同时在本地bin目录下新建两个txt文件file1.txt和file2txt,并在这两个文件里写入相应内容,接着把这两个本地文件上传到hdfs文件夹input上,如图
此时在网页上也可以看到input文件夹以及file1.txt和file2.txt的内容,如图
最后在/opt/Hadoop/hadoop-1.0.1/bin目录下敲入命令./hadoop jar ../lib/Count.jar WordCount input output,即hadoop集群开始工作,结果输出到output文件上,该文件可以从网页上查看结果。
结果在part-000000里保存,在网页上打开该文件,显示如下
结果显示,该伪分布式hadoop集群工作正常,从网页上也可以看出来^_^
本文出自 “在路上” 博客,请务必保留此出处http://imiron.blog.51cto.com/5118978/899854

相关文章推荐
- VBox下CentOS的hadoop伪分布环境的搭建(-)
- VBox下CentOS的hadoop伪分布环境的搭建(三)
- VBox下CentOS的hadoop伪分布环境的搭建(二)
- 【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式
- 搭建Vagrant+VBox+CentOS-7+共享文件夹的开发环境
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Virtualbox安装Ubuntu13.04并搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- 高效5步走,快速搭建Hadoop2伪分布环境
- vmvare上hadoop2.6的伪分布环境搭建
- Hadoop环境在centos中的搭建
- Centos7下搭建Hadoop7单机环境
- Hadoop2.x环境搭建之搭建伪分布模式以及运行wordcount案例【HDFS上的数据】
- hadoop入门:2.Hadoop-1.12伪分布环境搭建
- centos下hadoop2.6伪分布式环境搭建
- hadoop-2.5.2伪分布环境搭建
- Centos7上搭建hadoop2.7.3分布式集群环境实验记录
- 搭建Hadoop环境----CentOs安装和配置(二)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)