hadoop hdfs HA 高可用简易集群搭建
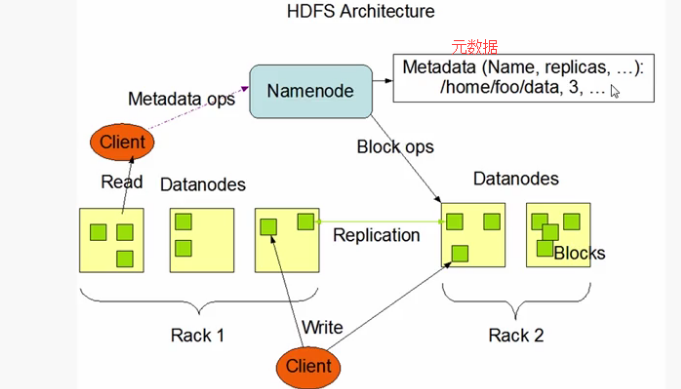
hdfs 原有架构
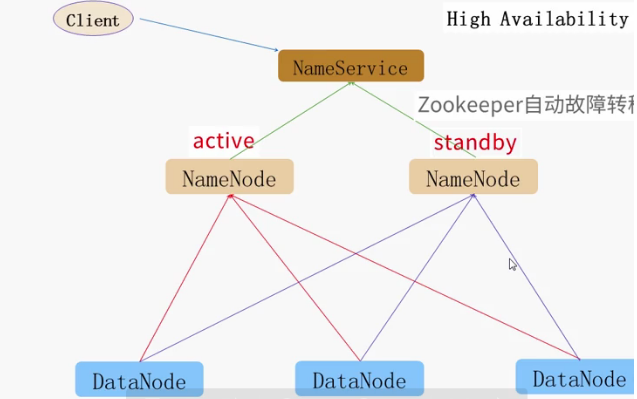
hdfs ha 通常由两个NameNode 组成,一个是active状态,一个是standby(备份)状态,active状态的nameNode 对外提供服,比如处理来自客户端的rpc请求,standby则不提供服务,只同步数据状态.
clent ->访问 nameservice(存储nameNode状态) --》通过zookeeper(自动故障转移)--> 活动的(actice)nameNode 调用dataNode
架构图如下:

JournalNodde 机器运行JournalNodes 机器,Journalnode 相当轻量,可以和hadoop的其它进程部署在一起,比如NameNode,DataNode,ResourceManager等,至少需要3个且为奇数,它允许(N-1)/2个JNS进程失效并且不影响工作。
hdfs-site.xml 重要配置


根据上述文档地址,进行安装配置:
1.修改hdfs-site.xml
<!-- 指定hdfs的namerservice 名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--- 制定上述nameservice 对应的两个namenode名称 nn1 ,nn2-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2对应的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
<!-- 配置nn1,nn2 访问的web端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
<!---- namenode 元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>
<!-- 配置失败,自动切换的方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<value>shell(true)</value>
</property>
<!-- 配置密钥位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
<!-- 数据备份个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!---- 开启失败故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置zookeeper 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value>
</property>
隔离机制,除了ssh 还有shell等配置,一般采用ssh
<!-- 端口 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<--- shell -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh arg1 arg2 ...)</value>
</property>
2.修改core-site.xml
<!-- 配置nameservice 名称 必须与hdfs-site.xml中的一致 -- >
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 编辑日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 配置hadoo 缓存文件目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/sw/hadoop/data/tmp</value>
</property>
中间启动测试journalnode:
这两项配置去掉
<!---- 开启失败故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置zookeeper 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value>
</property>
1.在每一台机器上启动journalnode:hadoop-daemon.sh start journalnode
2.在namenode节点机器启动namenode :hadoop-daemon.sh start namenode ,并执行格式化: hdfs namenode -format
3.在其它机器进行同步:hdfs namenode -bootstrapStandby (--help ) 出现以下则成功:
About to bootstrap Standby ID nn2 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://sw1:50070
Other NN's IPC address: sw1/192.168.56.103:8020
Namespace ID: 1397706359
Block pool ID: BP-199940621-192.168.56.103-1525943430914
Cluster ID: CID-c3a672de-5fb9-43b8-910f-0a42de357215
Layout version: -63
isUpgradeFinalized: true
4.启动datanode ,三台机器全部启动
页面访问namenode所在机器 ip:port ,两个节点都是standby
测试:手动启动一个为active ,,,,hdfs 有个haadmin命令:
Usage: haadmin
[-transitionToActive [--forceactive] <serviceId>] 转为actice 状态
[-transitionToStandby <serviceId>] 转为standby 状态 下面的不常用
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>] 查看集群状态
[-checkHealth <serviceId>]
[-help <command>]
启动命令:
1.启动zookeeper ./zkServer.sh start (有多少台机器就启动多少,也可以写安全脚本,一次启动)
2.启动nameNode sbin/hadoop-daemon.sh start namenode (启动次数同上)
3.格式化ZKFC bin/hdfs zkfc -formatZK(zk目录下会多出hadoop的信息)
4.停止hdfs集群 sbin/stop-dfs.sh
5.启动hadoop集群 sbin/start-dfs.sh
测试,kill掉actiive节点 发现standby 节点没有自动转为active
解决问题:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<!-- 新增该value 但是却不清楚为什么,因为上面配置了ssh的-->
<value>shell(true)</value>
</property>
转载于:https://my.oschina.net/undermoonlightperson/blog/1812926
- 点赞
- 收藏
- 分享
- 文章举报
 chewei3873
发布了0 篇原创文章 · 获赞 0 · 访问量 147
私信
关注
chewei3873
发布了0 篇原创文章 · 获赞 0 · 访问量 147
私信
关注

- 搭建高可用的分布式hadoop2.5.2集群 HDFS HA
- hadoop学习之HDFS(2.2):centOS7安装高可用(HA)完全分布式集群hadoop2.7.2
- hadoop集群搭建HDFS、HA、 YARN
- centos7 搭建ha(高可用)hadoop2.7.3集群
- HDFS集群搭建,高可用双机热备模式(HA)自动切换,hdfs+zookeeper+journalnode,步骤分步原理详解(适合初学者)
- Hadoop HDFS通过QJM实现高可用HA环境搭建
- Hadoop2.5的HDFS集群HA搭建(高可用集群)
- Hadoop高可用HDFS集群搭建详解
- Hadoop2.6集群环境搭建(HDFS HA+YARN)原来4G内存也能任性一次.
- Hadoop HA (高可用)集群搭建
- Hadoop集群HA高可用搭建
- hadoop-HA集群搭建,启动DataNode,检测启动状态,执行HDFS命令,启动YARN,HDFS权限配置,C++客户端编程,常见错误
- hadoop2.5.1集群搭建:(二)搭建自动切换HA的HDFS集群
- hadoop yarn HA 高可用架构简易集群配置
- Hadoop2.2.0 HA高可用分布式集群搭建(hbase,hive,sqoop,spark)
- hadoop2.5.1集群搭建:(一)搭建手工切换ha的hdfs集群
- 搭建高可用的hadoop分布式集群HA
- Hadoop2.6集群环境搭建(HDFS HA+YARN)
- hadoop 集群HA高可用搭建以及问题解决方案
- 2014-01-14---Hadoop的基础学习(八)---HDFS的HA机制及Hadoop集群搭建