Python进行vivo手机评论数据信息情感分析、LDA主题分析
一、摘要
用Python对爬取得到的京东vivo手机评论信息数据进行情感分析,通过LDA模型进一步分析,进而总结出vivo手机的优势与劣势。
二、分析步骤
1)重复值处理
2)过滤短句
3)情感分析
4)去除无用符号
5)分词
6)词频统计
7)LDA主题分析
8)结论
三、具体分析过程
1.导入数据
import pandas as pd
data = pd.read_csv('vivo_comments.csv')
print(type(data))
2.重复值处理
将读取数据中所有列相同的值删除
data_null = data.drop_duplicates()
print(data_null)
data_null.to_csv('comments_null.csv')
data_null_comments = data_null['contents']
data_null_comments.to_csv('contents.txt',index=False,encoding='utf-8')
print(len(data_null_comments))
3.过滤短句
将数据中长度小于4的过滤掉,保留长度大于4的数据。
data_len = data_null_comments[data_null_comments.str.len()>4]
print(data_len)
data_len.to_csv('contents.txt',index=False,encoding='utf-8')
4.情感分析
利用SnowNlP库将评论数据分为正面评论和负面评论
from snownlp import SnowNLP
data = pd.read_csv('contents.txt',encoding='utf-8',header=None)
print(data)
# print(type(data))
coms = []
coms = data[0].apply(lambda x:SnowNLP(x).sentiments)
data_post = data[coms>=0.5]
data_neg = data[coms<0.5]
print(data_post)
print(data_neg)
data_post.to_csv('comments_正面情感结果.txt',encoding='utf-8',header=None)
data_neg.to_csv('comments_负面情感结果.txt',encoding='utf-8-sig',header=None)
5.去除无用符号
将数据中影响数据分析的符号去除掉
with open('comments_正面情感结果.txt',encoding='utf-8') as fn1:
string_data1 = fn1.read() # 使用read方法读取整段文本
pattern = re.compile(u'\t|\n|\.|-|——|:|!|、|,|,|。|;|\)|\(|\?|"') # 建立正则表达式匹配模式
string_data1 = re.sub(pattern, '', string_data1) # 将符合模式的字符串替换掉
print(string_data1)
fp = open('comments_post.txt','a',encoding='utf8')
fp.write(string_data1 + '\n')
fp.close()
with open('comments_负面情感结果.txt',encoding='utf-8') as fn2:
string_data2 = fn2.read()
pattern = re.compile(u'\t|\n|\.|-|——|:|!|、|,|,|。|;|\)|\(|\?|"') # 建立正则表达式匹配模式
string_data2 = re.sub(pattern, '', string_data2) # 将符合模式的字符串替换掉
print(string_data2)
fp = open('comments_neg.txt','a',encoding='utf8')
fp.write(string_data2 + '\n')
fp.close()
6.分词
对正面评价和负面评价信息分别进行分词
import jieba
data1 = pd.read_csv('comments_post.txt',encoding='utf-8',header=None)
data2 = pd.read_csv('comments_neg.txt',encoding='utf-8',header=None)
mycut = lambda s: ' '.join(jieba.cut(s)) # 自定义简单分词函数
data1 = data1[0].apply(mycut)
data2 = data2[0].apply(mycut)
data1.to_csv('comments_post_cut.txt',index=False,header=False,encoding='utf-8')
data2.to_csv('comments_neg_cut.txt',index=False,header=False,encoding='utf-8')
print(data2)
7.词频统计
此处进队正面评价信息进行词频统计,负面评价信息和正面评价信息方法同理。
import collections
with open("comments_neg_cut.txt",encoding="utf-8") as fn:
string_data = fn.read()
word_counts = collections.Counter(string_data)
word_counts_top10 = word_counts.most_common(10) # 提取前10个频率最高的词
for w, c in word_counts_top5:
print(w, c)
用词云展示图如下

8.LDA主题分析
post = pd.read_csv('comments_post_cut.txt',encoding='utf-8',header=None,error_bad_lines=False)
neg = pd.read_csv('comments_neg_cut.txt',encoding='utf-8',header=None,error_bad_lines=False)
stop = pd.read_csv('stoplist.txt',encoding='utf-8',header=None,sep='tipdm',engine='python')
stop = [' ',''] + list(stop[0]) # 添加空格
post[1] = post[0].apply(lambda s: s.split(' '))
post[2] = post[1].apply(lambda x: [i for i in x if i not in stop])
neg[1] = neg[0].apply(lambda s: s.split(' '))
neg[2] = neg[1].apply(lambda x: [i for i in x if i not in stop])
'''正面主题分析'''
post_dict = corpora.Dictionary(post[2]) # 建立词典
post_corpus = [post_dict.doc2bow(i) for i in post[2]]
post_lda = models.LdaModel(post_corpus, num_topics=4, id2word=post_dict) # LDA模型训练
for i in range(3):
print(post_lda.print_topic(i)) # 输出每个主题
print('第一个主题分析')
'''负面主题分析'''
neg_dict = corpora.Dictionary(neg[2]) # 建立词典
neg_corpus = [neg_dict.doc2bow(i) for i in neg[2]]
neg_lda = models.LdaModel(neg_corpus, num_topics=4, id2word=neg_dict) # LDA模型训练
for i in range(3):
print(neg_lda.print_topic(i)) # 输出每个主题
9.结论
上面基本上已经完成了对于vivo手机评论信息的情感分析以及还进行了LDA主题分析,接下来基于LDA主题分析作简要评述。
表1 vivo正面评价潜在主题

表2 vivo正面评价潜在主题
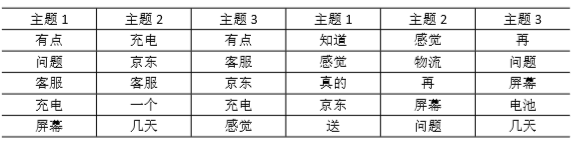
1.根据表 1vivo 好评的 3 个潜在主题的特征词提取,主题 1 中的高频词,即 喜欢、很快、流畅、速度、拍照、满意、挺等,主要反映的是 vivo 手机很流畅, 运行速度快,拍照效果好;主题 2 也主要反映的是 vivo 手机运行流畅,外观感 觉很满意等;主题 3 高频特征词,即主要是性价比高。 2.根据表 2vivo 差评的 3 个潜在主题的特征词可以看出,主题 1 的高频特征 词主要是客服、充电、京东即主题 1 主要反映的是京东平台客服服务问题,以及 vivo 手机充电存在的一些问题;主题 2 的高频词汇是京东、几天、物流主要反映 的是物流问题,主题 3 高频特征词京东、客服、充电、电池、问题,主题 3 可能 反映的是 vivo 手机在京东销售客服上的一些问题,及充电电池发热等问题。 综合以上对主题及其中的高频特征词可以看出,vivo 手机的优势有以下几个 方面:运行流畅,速度快,外观好看,性价比高,拍照效果好。 相对而言,用户对 vivo 手机抱怨的地方在京东客服服务问题,以及手机使用 过程中充电和电池的相关问题。 因此,用户购买 vivo 手机可以总结为以下几个方面:vivo 手机品牌值得信赖, vivo 手机性价比高。 根据对京东平台上 vivo 手机的用户评价进行 LDA 主题模型分析,对 vivo 手 机提出以下几点建议。 1)在保持 vivo 手机运行流畅、速度快等的基础上,对 vivo 手机在充电上和 电池上进行改进,从整体上提升 vivo 手机的质量。 2)加强客服人员的整体素质,提高服务质量,让其在手机行业的凸显优势。
附:
1.数据仅供学习和交流使用
2.数据和完整代码均保存在Github中
https://github.com/Jie-Wang-310/vivo_comments_analysis.git
- 点赞 2
- 收藏
- 分享
- 文章举报
 逍遥之癫
发布了3 篇原创文章 · 获赞 4 · 访问量 399
私信
关注
逍遥之癫
发布了3 篇原创文章 · 获赞 4 · 访问量 399
私信
关注

- 《Python 数据分析与挖掘实战》第十五章 电商产品评论数据LDA主题模型、文本挖掘
- 用Python做数据商品情感分析(商品评论数据情感分析)
- 【python数据挖掘课程】二十六.基于SnowNLP的豆瓣评论情感分析
- 【利用Python进行数据分析——经验篇2】计算微博转发/评论/点赞h指数的Python代码
- 基于python借助百度云API对评论进行情感极性分析
- 如何科学地蹭热点:用python爬虫获取热门微博评论并进行情感分析
- 【python 自然语言处理】对胡歌【猎场】电视剧评论进行情感值分析
- [置顶] 【python 自然语言处理】对胡歌【猎场】电视剧评论进行情感值分析
- python抓取NBA现役球员基本信息数据并进行分析
- 京东手机评论文本挖掘与数据分析(Python)
- [python和大数据-1]利用爬虫登录知乎进行BFS搜索抓取用户信息本地mysql分析【PART1】
- python - 对 '数码大冒险tri 泡泡评论' 进行简单的情感分析
- Python微博评论进行情感分析
- 利用 Python 进行数据分析(四)NumPy 基础:ndarray 简单介绍
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
- 利用python进行数据分析笔记
- 利用python进行数据分析-时间序列1
- 重要的Python库(利用Python进行数据分析笔记)
- 使用python进行数据分析
- 利用Python进行数据分析笔记(一