【利用Python进行数据分析——经验篇2】计算微博转发/评论/点赞h指数的Python代码
2017-06-28 20:05
846 查看
本文中记录了如何得出h指数的计算值
微博转发/评论/点赞h指数:(定义),某博主如果他/她发表的N篇博文中有h篇每篇至少被h次转发/评论/点赞,而剩下的(N-h)篇博文中每篇被转发/评论/点赞次数均少于h次,则数值h则表示的是这个微博的转发/评论/点赞h指数。
备注:本文中使用的是ipython交互式编辑器
本文中案例以【利用python进行数据分析——基础篇】利用Python处理和分析Excel表中数据实战的实战数据为例
#根据h指数的定义,分别计算转发/评论/点赞h指数
# 再记录下每个“用户名的最大互动度max(转发+评论+点赞)”
#根据h指数的定义,分别计算转发/评论/点赞h指数
# 再记录下每个“用户名的最大互动度max(转发+评论+点赞)”
# 将All表分组,获取表格的index值
gb = All.groupby(u'用户名')
gb1 = gb.size()
gbindex = gb1.index
sortAllf = All.sort_values(by=[u'用户名',u'转发数'],ascending=[True,False])
sortAllc = All.sort_values(by=[u'用户名',u'评论数'],ascending=[True,False])
sortAlll = All.sort_values(by=[u'用户名',u'点赞数'],ascending=[True,False])
mm = (sortAllf,sortAllc,sortAlll)
# 将计算得到的结果重新存储到一个新的DataFrame中
All_h = pd.DataFrame(np.arange(136).reshape(34,4),columns=['fh','ch','lh','max_hdd'],index=gbindex)
fh=[]
ch=[]
lh=[]
max_hdd = []
for j in range(len(mm)):
for i in gbindex:
tempdf = mm[j][mm[j][u'用户名']==i]
tempdf['hdd'] = tempdf[u'转发数']+tempdf[u'评论数']+tempdf[u'点赞数']
max_hdd.append(tempdf['hdd'].max())
tempdf['numf'] = range(len(tempdf))
if j==0:
a = len(tempdf[tempdf[u'转发数']>=tempdf['numf']+1])
fh.append(a)
elif j==1:
b = len(tempdf[tempdf[u'评论数']>=tempdf['numf']+1])
ch.append(b)
else:
c = len(tempdf[tempdf[u'点赞数']>=tempdf['numf']+1])
lh.append(c)
All_h['fh']=fh
All_h['ch']=ch
All_h['lh']=lh
# 因为,前面的循环一共循环了三遍,使得All_h重复了3遍,因此只要获取前34位即可
All_h['max_hdd']=max_hdd[:34]
# 插入一个综合h指数,该指数是转发/评论/点赞h指数三个的均值
All_h.insert(3,'HS',All_h.iloc[:,:3].mean(1))
#更改列名称
All_h.rename(columns={'fh':u'转发h指数','ch':u'评论h指数',\
'lh':u'点赞h指数','HS':u'综合h指数','max_hdd':u'单篇最大互动度'},inplace=True)
#输出该表格的前5行
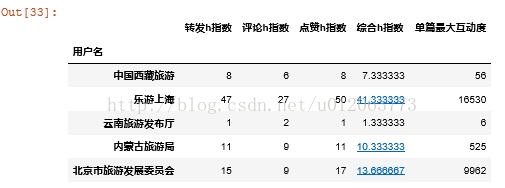
All_h.head()
微博转发/评论/点赞h指数:(定义),某博主如果他/她发表的N篇博文中有h篇每篇至少被h次转发/评论/点赞,而剩下的(N-h)篇博文中每篇被转发/评论/点赞次数均少于h次,则数值h则表示的是这个微博的转发/评论/点赞h指数。
备注:本文中使用的是ipython交互式编辑器
本文中案例以【利用python进行数据分析——基础篇】利用Python处理和分析Excel表中数据实战的实战数据为例
#根据h指数的定义,分别计算转发/评论/点赞h指数
# 再记录下每个“用户名的最大互动度max(转发+评论+点赞)”
#根据h指数的定义,分别计算转发/评论/点赞h指数
# 再记录下每个“用户名的最大互动度max(转发+评论+点赞)”
# 将All表分组,获取表格的index值
gb = All.groupby(u'用户名')
gb1 = gb.size()
gbindex = gb1.index
sortAllf = All.sort_values(by=[u'用户名',u'转发数'],ascending=[True,False])
sortAllc = All.sort_values(by=[u'用户名',u'评论数'],ascending=[True,False])
sortAlll = All.sort_values(by=[u'用户名',u'点赞数'],ascending=[True,False])
mm = (sortAllf,sortAllc,sortAlll)
# 将计算得到的结果重新存储到一个新的DataFrame中
All_h = pd.DataFrame(np.arange(136).reshape(34,4),columns=['fh','ch','lh','max_hdd'],index=gbindex)
fh=[]
ch=[]
lh=[]
max_hdd = []
for j in range(len(mm)):
for i in gbindex:
tempdf = mm[j][mm[j][u'用户名']==i]
tempdf['hdd'] = tempdf[u'转发数']+tempdf[u'评论数']+tempdf[u'点赞数']
max_hdd.append(tempdf['hdd'].max())
tempdf['numf'] = range(len(tempdf))
if j==0:
a = len(tempdf[tempdf[u'转发数']>=tempdf['numf']+1])
fh.append(a)
elif j==1:
b = len(tempdf[tempdf[u'评论数']>=tempdf['numf']+1])
ch.append(b)
else:
c = len(tempdf[tempdf[u'点赞数']>=tempdf['numf']+1])
lh.append(c)
All_h['fh']=fh
All_h['ch']=ch
All_h['lh']=lh
# 因为,前面的循环一共循环了三遍,使得All_h重复了3遍,因此只要获取前34位即可
All_h['max_hdd']=max_hdd[:34]
# 插入一个综合h指数,该指数是转发/评论/点赞h指数三个的均值
All_h.insert(3,'HS',All_h.iloc[:,:3].mean(1))
#更改列名称
All_h.rename(columns={'fh':u'转发h指数','ch':u'评论h指数',\
'lh':u'点赞h指数','HS':u'综合h指数','max_hdd':u'单篇最大互动度'},inplace=True)
#输出该表格的前5行
All_h.head()

相关文章推荐
- 利用Python进行数据分析(6) NumPy基础: 矢量计算
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
- 【利用Python进行数据分析——经验篇4】将多张DataFrame表写入到同一个Excel的不同sheet中
- 利用 Python 进行数据分析(九)pandas 汇总统计和计算
- 【利用Python进行数据分析——经验篇3】如何操作DataFrame中的列的数据格式(转为百分数、保留4位小数)
- 【利用python进行数据分析】第八章的海地地震数据代码
- 利用Python进行数据分析 2017 第二版 项目代码
- 利用Python进行数据分析--数据聚合与分组运算
- 利用Python进行数据分析——准备工作篇
- 利用Python进行数据分析——第一章:重要Python库安装配置
- 利用Python进行数据分析---ch02《MovieLens 1M数据集(下)》读书笔记
- 利用Python进行数据分析---ch02《MovieLens 1M数据集(上)》读书笔记
- 利用python进行数据分析之绘图和可视化
- linux下利用python进行数据分析(1)Anaconda 安装
- 《利用Python进行数据分析: Python for Data Analysis 》学习随笔
- 《利用python 进行数据分析》要点记录
- 在ENVI进行的土地利用分类数据,需要做景观指数分析,如何将其转换成GRID格式呀
- 利用Python进行数据分析笔记(一
- [python和大数据-1]利用爬虫登录知乎进行BFS搜索抓取用户信息本地mysql分析【PART1】
- 利用python进行数据分析-关于包的坑