CVPR 2019之语义分割解读(二): Adaptive Pyramid Context Network for Semantic Segmentation
Adaptive Pyramid Context Network for Semantic Segmentation
简述:
当前,基于语境的分词方法在如何构建语境结构以及在实践中不同的表现上存在着一定的差异,特别的是,发现全局导向的局部亲和力(GLA)在构建有效的语境特征中至关重要。本文介绍了一种基于自适应金字塔上下文网络(Adaptive Pyramid Context Network)的语义分割,简称APCNet,APCNet采用多个设计良好的自适应上下文模块(ACMs)自适应地构造多尺度上下文表示,具体来说,每个ACM利用全局图像表示作为指导来估计每个子区域的局部亲和系数(affinities),然后使用这些局部亲和系数计算上下文向量。
问题or相关工作:
目前,语义分割的挑战来自于同一对象/材料的内部内容、形状和尺度的变化,以及不同对象/材料之间容易混淆和精细的边界。本文提出了三点建议:
1.多尺度(Multi-scale):由于对象通常具有不同的大小和位置,因此需要构造多尺度表示来捕获不同尺度的图像内容。
2.自适应(Adaptive):一个图片中并不是所有区域的权重都是一样的,所以,自适应地识别这些重要区域是构建最优上下文向量的重要方法。
3.全局导引的局部亲和力(Global-guided Local Affinity (GLA)):意思就是从相关像素或区域聚合特征,以往的研究主要是利用像素和重区域的局部表示来估计这些自适应权值,忽略了全局上下文,本文对上下文导引的作用有明确的阐释并加以运用。
下图为当前众多方法对以上三点特性的运用:

本文的贡献主要在于:
1.总结了上下文向量在语义分割中的三个理想性质,并从这些性质的角度对基于深层上下文的语义分割方法进行了比较。
2.提出了利用GLA特性的自适应上下文模块,利用局部和全局表示来估计局部区域的亲和权值。这些相似性进一步使我们能够为分段任务构建自适应的、多尺度的上下文表示
3.在三个广泛使用的基准上,包括PASCAL VOC 2012、PASCAL - context和ADE20K数据集,实现了最先进的性能,并且在没有MS COCO预培训和任何后处理的情况下,在PASCAL VOC 2012测试集上获得了84.2%的新记录。
模型:
APCNet模型框架

当图片输入时,首先对图片经过CNN(本文多为RESNet)提取图像特征(Feature Map)X,将X分解为多尺度的金字塔(multi-scale pyramid)表示,每个尺度的表示被输入到自适应上下文模块(ACM)中,以估计每个局部位置的自适应上下文向量。本文提出的APCNet由多个并行的ACMs组成。每个ACM由两个分支组成,其中一个分支用于估计GLA亲和系数αs,另一个分支用于获得子区域自适应表示ys。将这两个分支的输出相乘得到自适应上下文向量zs,公式如下,APCNet将来自不同尺度的上下文向量和原始特征立方体X级联起来,用于预测输入像素的语义标签。

特别的是,在ACM模块中,上层分支,先经过1×1卷积对Feature Map进行降维,输出后的矩阵进行全局平均池化(GAP)输出1维向量,与降维后的矩阵进行求和,在经过卷积后输出αs,用以表征全局信息(Global Information);下层分支,先经过自适应池化(Adaptive pooling)后进行1×1降维输出ys,以表征子区域自适应信息。随后将两个权值相乘,得出自适应上下文向量zs以表征在全局下的每个区域的自适应程度,以体现每个特征块不同的重要性。
知识点:
1.GAP:
平均池化:在feature map上以窗口的形式进行滑动(类似卷积的窗口滑动),操作为取窗口内的平均值作为结果,规定窗口大小size,经过操作后,feature map降采样,减少了过拟合现象。
全局平均池化GAP:不以窗口的形式取均值,而是以feature map为单位进行均值化。即一个feature map输出一个值。
《NIN》:使用全局平均池化代替CNN中传统的全连接层。在使用卷积层的识别任务中,全局平均池化能够为每一个特定的类别生成一个feature map(有多少个类就产生多少个feature map)。
GAP的优势在于:各个类别于feature map之间的联系更加直观(相比于全连接层的黑箱来说),feature map被转化为分类概率更加容易;因为在GAP中没有参数需要调,所以避免了过拟合问题;GAP汇总了空间信息,因此对输入的空间转换更为鲁棒。原因如图:

2.Adaptive pooling
自适应池化Adaptive Pooling是PyTorch的一种池化层,根据1D,2D,3D以及Max与Avg可分为六种形式。
自适应池化Adaptive Pooling与标准的Max/AvgPooling区别在于,自适应池化Adaptive Pooling会根据输入的参数来控制输出output_size,而标准的Max/AvgPooling是通过kernel_size,stride与padding来计算output_size:
output_size = ceil ( (input_size+2∗padding−kernel_size)/stride)+1
当我们使用Adaptive Pooling时,这个问题就变成了由已知量input_size,output_size求解kernel_size与stride。
stride = floor ( (input_size / (output_size) )
kernel_size = input_size − (output_size−1) * stride
padding = 0
3.Reshape
调整矩阵的维度和形状,本文中reshape为将3维转换为2维。
4.Concat
级联:用于数组合并,并且不改变原数组,返回一个新数组
成果:
APCNet效果:

在ResNet中研究将ACM分成不同s大小的mIoU:

GLA对整体mIoU的影响:

DS:深度监督、Filp:水平翻转输入图像求值、MS:多尺度评估、FT:finetune操作
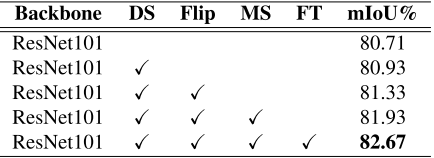
多尺度操作(Multi-Scale)对比

全局导引的局部亲和力(GLA)对比:

MS COCO数据集下不同语义分割方法准确率比较:


- 语义分割经典论文:Dual Attention Network for Scene Segmentation (CVPR2019)
- 语义分割经典论文:Context Encoding for Semantic Segmentation (CVPR2018)
- 实时语义分割BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation论文解读
- 语义分割--DeconvNet--Learning Deconvolution Network for Semantic Segmentation
- 语义分割经典论文:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation (ECCV2018)
- 语义分割经典论文:ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation (ECCV20
- 语义分割--Label Refinement Network for Coarse-to-Fine Semantic Segmentation
- 语义分割--Global Deconvolutional Networks for Semantic Segmentation
- CNN for Semantic Segmentation(语义分割,论文,代码,数据集,标注工具,blog)
- 语义分割 DeepLabv3--Rethinking Atrous Convolution for Semantic Image Segmentation
- 语义分割--Learning Object Interactions and Descriptions for Semantic Image Segmentation
- 深度对抗网络用于分割(语义分割)——Adversarial Learning for Semi-Supervised Semantic Segmentation
- 语义分割--Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes
- 语义分割--Large Kernel Matters--Improve Semantic Segmentation by Global Convolutional Network
- 语义分割--Understand Convolution for Semantic Segmentation
- CNN for Semantic Segmentation(语义分割,论文,代码,数据集,标注工具,blog)
- CNN for Semantic Segmentation(语义分割,论文,代码,数据集,标注工具,blog)
- 语义分割--Mix-and-Match Tuning for Self-Supervised Semantic Segmentation
- CVPR 2019之迁移学习解读(三)Contrastive Adaptation Network for Unsupervised Domain Adaptation
- CV | Feature Space Optimization for Semantic Video Segmentation - 基于特征空间优化的视频语义分割