基金大数据分析及基金投资建议(Python与Excel实现)
如果需要转载本文或者需要相关的数据资料,请与我联系。邮箱:18588809730@163.com
一、目标确定
本次主要通过对基金进行大数据分析,了解目前开放型基金的现状,同时对基金的评级及回报率等相关数据进行分析,以确定最佳基金投资标的。
二、数据获取
数据获取方面,采用数据采集器,对天天基金网及晨星网的数据进行搜集。搜索数据包括基金的基本信息及分红数据,基金的历年收益率数据,基金的评级数据(包括晨星网和证券公司等评级机构的评级数据,数据量总计大约在一万五千条左右。并将数据存放在四个excel文件中,分别存放于divF.xlsx,OpenF.xlsx,RankOpenF.xlsx,tiantianRank.xlsx四个文件,作为数据源。
数据已经过清洗,其简要情况如下:
divF.xlsx:

OpenF.xlsx

RankOpenF.xlsx:
tiantianRank.xlsx:

三、数据清洗
数据清洗会消耗掉大量的时间,主要采用excel和python的相关功能进行,如excel的查找替换,python的dropna()等等。这里不过多描述。
四、数据整理及分析
这部分是核心,重点围绕数据整理及描述分析进行,呈现相应的实现代码和相关图表。后续依次生成数据分析报告。算是手把手教你如何用python进行基金的大数据分析了。
处理前提,导入相应的库:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from pyecharts import Bar import matplotlib matplotlib.matplotlib_fname() #会显示matplotlibrc文件的地址 from pyecharts import online online() # needed for online viewing plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容'
第一步,我们对整体的基金收益率进行简单分析,大部分分析思路已经通过注释的形式给出。这里文字点到为止。
#读入前期通过爬虫采集器采集天天基金网的数据
openF=pd.read_excel('D:/PythonData/OpenF.xlsx')
openF.head(3) #查看一下数据是否有异常。
显示如下:

#重命名索引为English name,方便数据处理,上面看到基金代码前面的0没识别,读的时候,把它转为str格式。
openF=pd.read_excel('D:/PythonData/OpenF.xlsx',converters = {u'基金代码':str}) #
openF.rename(columns={'序号':'NO.','基金代码':'code','基金简称':'name', '日期':'date','单位净值':'unitnet','累计净值':'sumnet','日增长率':'Dailygrowth','近1周':'Rweek','近1月':'R1month','近3月':'R3months','近6月':'R6months','近1年':'R1year','近2年':'R2years','近3年':'R3years','今年来':'thisyear','成立来':'SinceFounded','手续费':'charges'},inplace=True)
openF.head(3)
其显示如下:
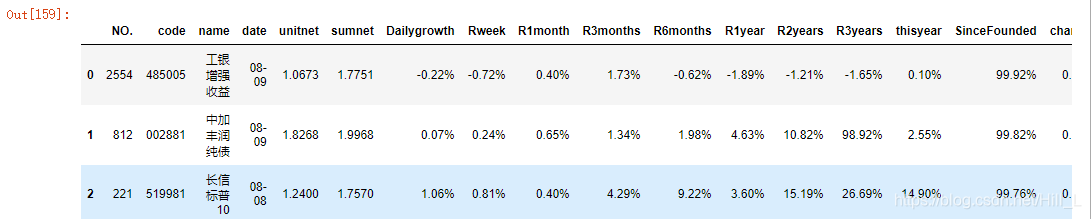
#删除重复采集的数据序列 openF.drop_duplicates(inplace=True) openF.describe()
#我们希望稳健一点,今年至今的8个月,上证指数差不多回到原点,我们希望基金今年的收益率为正。
type(openF.Dailygrowth[0]) #查看其均为str类型,需要转换成整数型
#open_F=openF[{'Dailygrowth','Rweek'}].str.strip('%').astype(float)/100 不可哈希,有毛病,得一个个来
temp=openF.replace('---',np.nan)
openF=temp.replace('--',np.nan)
openF.tail(100)
openF.dropna(inplace=True) #寻找那些成立3年以上的基金,删除近三年收益率为Nan的基金
#openF.count()
由于百分数导入为字符串格式,我们需要将其转换为float模式。
Dailygrowth=openF['Dailygrowth'].str.strip('%').astype(float)/100
Rweek=openF['Rweek'].str.strip('%').astype(float)/100
R1month=openF['R1month'].str.strip('%').astype(float)/100
R3months=openF['R3months'].str.strip('%').astype(float)/100
R6months=openF['R6months'].str.strip('%').astype(float)/100
R1year=openF['R1year'].str.strip('%').astype(float)/100
R2syears=openF['R2years'].str.strip('%').astype(float)/100
R3years=openF['R3years'].str.strip('%').astype(float)/100
thisyear=openF['thisyear'].str.strip('%').astype(float)/100
SinceFounded=openF['SinceFounded'].str.strip('%').astype(float)/100
charges=openF['charges'].str.strip('%').astype(float)/100
openF['Dailygrowth']=Dailygrowth
openF['Rweek']=Rweek
openF['R1month']=R1month
openF['R3months']=R3months
openF['R6months']=R6months
openF['R1year']=R1year
openF['R2years']=R2syears
openF['R3years']=R3years
openF['thisyear']=thisyear
openF['SinceFounded']=SinceFounded
openF['charges']=charges
借助数据化的手段,让我们对基金的整体情况有一个更为直观的把握。可视化有助于我们对数据进行更直观的认识与把握,发现数据规律,洞察一些可能的趋势。
我们采用了bar来展示。
#openF.head(5)
#数据可视化,对数据有一个直观的认识
openF_charges=openF.groupby('charges').count()
openF_charges=openF_charges.reset_index()
openF_charges.head(2)
attr = ["{}".format(i*100)+str('%') for i in openF_charges['charges']]
#attr = [i for i in openF_charges['charges']]
v1 = [i for i in openF_charges['code']]
bar = Bar("开放基金手续费分布图:")
bar.add("基金数目", attr, v1, xaxis_interval=0, xaxis_rotate=80, yaxis_rotate=50)
bar
结果如
3ff7
下:

大部分基金的手续费都在0.15%,达到1300只。这也是目前比较正常的手续费,支付宝大部分基金的手续费也在这个区间。
下面,再利用直方图,对基金的收益率进行分析,有一个直观的认知:我们看到,-20%-40%的三年收益率,是大部分基金的最终归宿。
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 from matplotlib.pyplot import MultipleLocator #坐标间隔改变模块 #ax=plt.gca() #重新设X坐标间隔 x_major_locator=MultipleLocator(0.5) #间隔设置为0.5 ax.xaxis.set_major_locator(x_major_locator) plt.xlabel(u'基金三年回报收益率区间',fontsize=24) plt.ylabel(u'基金个数',fontsize=24) plt.hist(openF.R3years,bins=40,range=(-2,3.5),color='orange')
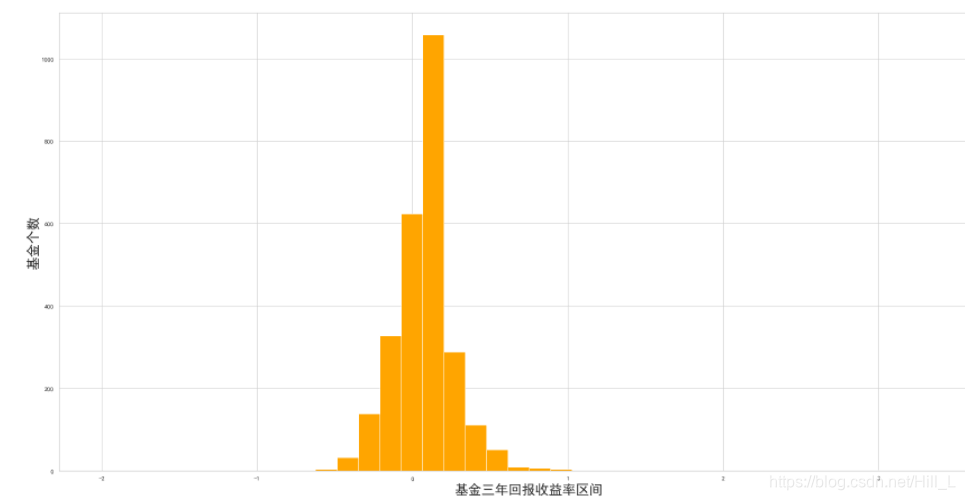
同样,对今年的基金收益率进行分析,其实现类似:
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容' ax=plt.gca() #重新设X坐标间隔 x_major_locator=MultipleLocator(0.1) #间隔设置为0.5 ax.xaxis.set_major_locator(x_major_locator) plt.xlabel(u'今年回报率',fontsize=24) plt.ylabel(u'基金个数',fontsize=24) plt.hist(openF.thisyear,bins=40,range=(-0.2,1),color='red') openF.thisyear.describe()

0%-25%的收益率,是今年大部分基金截止到8月取得的成果,整体情况,比去年2018年要好很多。
#分析两年期回报率 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 ax=plt.gca() #重新设X坐标间隔 x_major_locator=MultipleLocator(0.5) #间隔设置为0.5 ax.xaxis.set_major_locator(x_major_locator) plt.xlabel(u'基金的2年回报率区间',fontsize=14) plt.ylabel(u'基金个数',fontsize=14) plt.hist(openF.R2years,bins=40,range=(-1,3),color='red') openF.R2years.describe()
基金两年期的收益率如下:-40%-20%的基金占了绝大多数,而这2年最多的基金收益率聚集区间在

下面继续对基金成立以来,其收益率在各个区间的个数进行统计:成立以来,能够翻倍的基金极为少数,极个别基金的收益率达到了20多倍,这非常难得。

紧接着,我们对不同期限,在不同区间的收益率的基数做一下分析,这样有助于合理设定我们的投资收益目标。
""""此处意在用映射的方式进行收益率范围分类,失败!Series无法被哈希
R3years_to_Rank={
openF.R3years<0:"Bad",
(0<openF.R3years) & (openF.R3years<0.1): "0-10%",
(0.1<openF.R3years) & (openF.R3years<0.3):"10%-30%",
(0.3<openF.R3years) & (openF.R3years<0.5):"30%-50%",
openF.R3years>0.5:">50%"}
#'Series' objects are mutable, thus they cannot be hashed
openF['Rank']=openF.map(R3years_to_Rank)
openF.head()
"""
#我们更希望看到回报率的更具体的情况,通过bar可实现,连续数据的离散化。
#调用cut函数对数据进行处理。pd.cut用于面元划分或离散化。cats=pd.cut(list,bins) bins为传入的区间,可用right=False对右开区间。返回值cats有.levels和label两个。
#其中,cats.levels返回index类型,如[[1,2],[3,4]],如lcats.labels则返回array,如[0,1]。3.0已更改为cats.codes和cats.categories.
bins=[openF.R3years.min(),0,0.1,0.3,0.5,1,2,openF.R3years.max()]
group_names=['负收益率','0-10%','10%-30%','30%-50%','50%-100%','1-2倍','2倍以上']
cats=pd.cut(openF.R3years,bins,labels=group_names,right=False)
#print(cats.codes) #无法调用,可能新版本又变了
#print(cats.categories)
s1=pd.value_counts(cats)
attr=s1.index
v1=s1.values
bar = Bar("基金3年收益率个数分布图")
bar.add("基金三年收益率该组个数", attr,v1, xaxis_interval=0, xaxis_rotate=36, yaxis_rotate=0)在这里插入代码片
结果如下:

有783个基金是负收益的。可见,投资基金的风险并不小。同时,10%-30%,加上0-10%的基金个数,也占据了大部分。可见,如果要实现超额收益,选取30%以上的基金,这个难度是相当不小的。
这两年基金行情,我们再接着分析一下:
#对2年收益率作出同样处理
bins=[openF.R2years.min(),0,0.1,0.3,0.5,1,2,openF.R2years.max()]
group_names=['负收益率','0-10%','10%-30%','30%-50%','50%-100%','1-2倍','2倍以上']
cats=pd.cut(openF.R2years,bins,labels=group_names,right=False)
#print(cats.codes) #无法调用,可能新版本又变了
#print(cats.categories)
s1=pd.value_counts(cats)
attr=s1.index
v1=s1.values
bar = Bar("基金2年收益率区间分布图")
bar.add("基金2年收益率区间该区间个数", attr,v1, xaxis_interval=0, xaxis_rotate=36, yaxis_rotate=0)

负收益率排第一,第二是0-10%的收益率。如果没有好的投资基础,还真的不如把钱放银行。30%以上收益的基金,是努力的目标,却需要花费不少的力气。
我们再对基金成立以来的收益率进行分析,其实更好的分析维度是年化收益,这里就不介绍了。需要结合基金的成立时间进行二次分析,有兴趣的读者可以尝试一下。

#对于集中程度,可以用箱体图进行查看 sns.set(style="whitegrid") ax=plt.gca() #重新设X坐标间隔 x_major_locator=MultipleLocator(1) #间隔设置为1 ax.xaxis.set_major_locator(x_major_locator) ax = sns.boxenplot(x=openF['SinceFounded'],color='red')

有三个点,大于11倍。做数据分析报告时,对这几个基金可以重点拿出来分析一下。
开始初步地基金进行筛选:
#选了手续费小于0.15%.节约成本,同时回报率近1年,3年,成立以来都为正,这样可以确保基金的稳定性,有成长的能力和抵御风险的能力。 #我们希望稳健一点,今年至今的8个月,上证指数差不多回到原点,我们希望基金今年的收益率为正。 temp=openF[(openF.charges<0.0015)&(openF.R3years>0)&(openF.thisyear>0)&(openF.R1year>0)&(openF.SinceFounded>0)] temp.head() openF_total=temp #openF此时保留那些初步具有投资价值的资金
第一步,就到这里暂时结束,主要围绕收益率进行分析。
下面,进行第二步。第二步主要分析基金的类型分布及晨星评级。晨星评级,我们选取三星以上的基金进行重点分析。
#另外,爬取了晨星评级3年和5年的投资收益评级均在3星以上的开放基金,其中有基金种类,今年回报率%,基金净值等属性。
df_R=pd.read_excel('D:/PythonData/RankOpenF.xlsx',converters = {u'code':str})
df_R['Rthisyear']=df_R.Rthisyear/100
#df_R=df_R.set_index('code')
df_R.tail(5) #看一下数据是否正常
数据OK的。

对基金总体情况,结合评级,类型进行可视化分析:
df_R_category=df_R.category.value_counts()
df_R_category.index
attr = df_R_category.index
v1 = df_R_category.values
bar = Bar("晨星评级均超过3星的基金类型分布")
bar.add("晨星评级3星以上基金数量", attr, v1, xaxis_interval=0, xaxis_rotate=36, yaxis_rotate=0)
bar
结果如下图:激进配置型基金和股票型还有激进债券型基金,其质量相对比较好。也有可能与其基数相对比较大有关,这里应该结合比例分析会好。

结合条件,进行筛选,如下:
#在初步筛选基金数据后,结合晨星评级进行进一步的筛选。可进一步缩小基金的范围。
print(df_R[df_R.code=='110003'])
print(openF[openF.code=='110003'])
df_RF=pd.merge(openF,df_R,on='code') #,suffixes=('_df_R','_openF')
df_RF_copy=df_RF.copy() #做个数据副本备用
df_RF.head(1)
df_RF=df_RF.drop(columns=['date_y','name_y','unitnet_y','Rthisyear']) #删除属性重复列
df_RF_CX=df_RF
df_RF_CX.describe()
成立以来,平均收益率为1.57,扎心。如果今年投资晨星网的三星以上评级基金,其期望收益在18.2%,整体而言还是不错的。最大的是翻了2.2倍,最小的亏损了18%。差距不小。

以上是结合晨星网的数据分析,紧接着我们看看分红。
第三步,考虑分红情况,一般情况下,选择股票考虑分红多一些。基金在这方面的应用不多,尝试做一下验证。但是,整体而言,分红的基金,总比不分红的要好一些。
divF=pd.read_excel('D:/PythonData/divF.xlsx',converters = {'code':str})
print(divF.head(1))
#print(divF.describe())
#导入一份基金的分红数据,包括了分红次数还有每份的分红额
from datetime import datetime
%matplotlib inline
plt.rcParams['figure.figsize'] = (30.0, 15.0)
divF=pd.read_excel('D:/PythonData/divF.xlsx',converters = {'code':str})
#print(divF.head(3))
数据显示如下:

,结合发行基金数,我们对基金的历史进行一个简单的回顾,是一件比较有意思的事情:
divF['FoundDate2']=pd.to_datetime(divF['FoundDate'])
df=divF[['FoundDate2','code']]
df['Month'] = [datetime.strftime(x,'%Y-%m') for x in df['FoundDate2']]
df =df.pivot_table(index='Month',aggfunc='count')
fig=plt.figure()
ax=fig.add_subplot(111)
x_major_locator=MultipleLocator(4)
ax.xaxis.set_major_locator(x_major_locator)#把x轴的主刻度设置为3的倍数
plt.title('历年基金发布情况汇总及大事件汇总',fontsize=24) #设置图表标题和标题字号
plt.tick_params(axis='both',which='major',labelsize=16,rotation=45) #设置刻度的字号
plt.xlabel('基金发布时间',fontsize=18)#设置x轴标签及其字号
plt.ylabel('当月发布基金数',fontsize=18)#设置x轴标签及其字号
#基金大件事:
plt.annotate(u'2001年,中国证监会发布《关于申请设立基金管理公司若干问题的通知》\n 首次引入“好人举手”制度\n首只开放式基金—华安创新发行',
xy=('2001-04',1),xytext=('2001-04',110),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2002年,社保基金管理人“选秀”',
xy=('2002-08',5),xytext=('2002-08',25),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2003年《基金法》获通过,\n 同年年,基金“价值投资”理念首次登场。',
xy=('2003-08',6),xytext=('2003-08',76),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'基金法,2004年6月1日起正式实施',
xy=('2003-12',8),xytext=('2003-12',18),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2005年,首家银行系基金公司工银瑞信基金成立',
xy=('2005-04',5),xytext=('2005-04',10),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2007年,基金规模爆增,创出3.27万亿的第一个行业巅峰。\n“公奔私”元年,阳光私募大发展。\n然而,QDII初次出海,遭遇次贷风暴',
xy=('2007-04',12),xytext=('2007-04',52),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2008年,证监会对基金“老鼠仓”开出处罚第一单',
xy=('2008-04',14),xytext=('2008-04',25),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2012年5月,“宏伟”谢幕,震动华夏。同年6月,中国证券投资基金业协会成立',
xy=('2012-04',16),xytext=('2012-04',75),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2013年,新《基金法》实施;券商保险等资管机构进军公募。\n同年,余额宝上线,基金业迈进互联网金融时代,\n 基金股权激励破冰,国务院明确个人持股条件',
xy=('2013-04',20),xytext=('2013-04',108),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2017年,首批FOF获批发行\n,公募基金进入资产配置新时代',
xy=('2017-04',85),xytext=('2017-04',95),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.annotate(u'2018年,养老目标基金指引正式发布\n,有望引爆基金业新一轮发展大潮。',
xy=('2018-04',40),xytext=('2018-04',46),
bbox = dict(boxstyle = 'round,pad=0.5',
fc = 'yellow', alpha = 0.5),
arrowprops=dict(facecolor='red',
shrink=0.05),fontsize=20)
plt.plot(df.index,df.code)
4000
plt.show()
结果如下图,是不是很好玩?
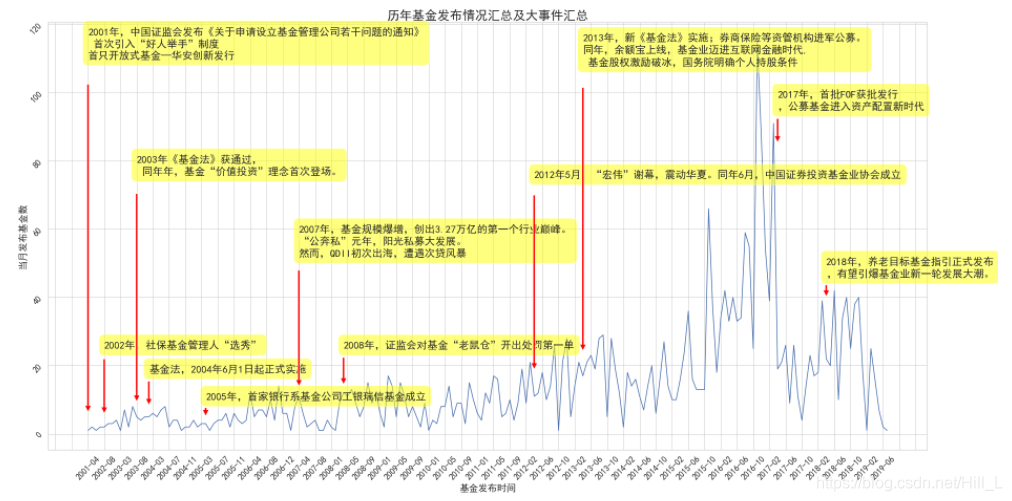
看一下基金分红的情况:
#coding:utf-8 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容' ax=plt.gca() x_major_locator=MultipleLocator(10) #间隔设置为10 ax.xaxis.set_major_locator(x_major_locator) plt.xlabel(u'分红次数',fontsize=14) plt.ylabel(u'基金个数',fontsize=14) plt.hist(divF.div_count,bins=60,color='brown')
ax=plt.gca() x_major_locator=MultipleLocator(1) #间隔设置为1 ax.xaxis.set_major_locator(x_major_locator) plt.xlabel(u'份分红总金额',fontsize=14) plt.ylabel(u'基金个数',fontsize=14) plt.hist(divF.div_sum,bins=50,color='brown')


分红次数与分红金额,分红次数绝大部分只有一次,而分红金额均落在0.5元以内的占了约大部分。
对分红次数进行分区间统计,有如下结果
bins=[1,2,3,4,5,6,7,8,9,10,11,divF.div_count.max()]
group_names=['1次','2次','3次','4次','5次','6次','7次','8次','9次','10次','大于10次']
cats=pd.cut(divF.div_count,bins,labels=group_names,right=True)
s1=pd.value_counts(cats)
attr=s1.index
v1=s1.values
bar = Bar("基金成立以来分红次数公布图")
bar.add("基金在该区间个数", attr,v1, xaxis_interval=0, xaxis_rotate=36, yaxis_rotate=0)

分红金额如下:
bins=[0,0.1,0.2,0.5,0.8,1,2,5,divF.div_sum.max()]
cats=pd.cut(divF.div_sum,bins,right=False)
s1=pd.value_counts(cats)
attr=s1.index
v1=s1.values
bar = Bar("基金成立以来分红金额公布图(单位:元)")
bar.add("基金在该区间个数", attr,v1, xaxis_interval=0, xaxis_rotate=36, yaxis_rotate=0)

可以看得到,一毛钱的分红金额数量是很多的。
再对数据进行初步筛选,作为这一步的结果,保存起来。如下:
divF.head(2) print(divF.count()) #分红可能受基金的上市时间影响,但是我们仍希望基金的发红次数大于2次,分红金额位于均值0.32元以上。这样,可以使我们的投资策略更为稳健。 divF_total=divF[(divF.div_count>2) & (divF.div_sum>0.32)] divF_last=divF_total print(divF_last.describe())
第四步,我们要结合券商的评级数据进行分析了,评级机构有上海证券,招商证券以及济安金信。
#读取天天基金网评级数据,如果需要透视数据,excel数据透视图会比较高效一些。
df_T=pd.read_excel('D:/PythonData/tiantianRank.xlsx',converters = {u'code':str})
df_T.tail(5) #存在数据空值
结果如下:
charge=df_T['charge'].str.strip('%').astype(float)/100
df_T['charge']=charge
#df_T.describe() #count体现出各项空值数量并一致
#看一下各基金评级公司给出五星评价的分布情况 df_T.pivot_table(index=['Fivestars_of_count'],aggfunc='count')
#看一下在不同公司的分布 df_T.pivot_table(index=['Fivestars_of_count'],columns=['Company'],aggfunc='count')
#三个评级公司对不同的基金公司给出的评级分布 df_T.pivot_table(index=['Company'],columns=['Fivestars_of_count'],aggfunc='count')
#某一家评级公司对各基金公司给出的评价分布情况 df_T.pivot_table(index=['SHZQ'],columns=['Company'],aggfunc='count',margins_name='Company')
#在数据透视层面,excel可根据透视表直接得出透视图,所以转用excel对基金质量分布,优秀基金公司和优秀基金经理等进行分析。
#在天天基金给出的三家评级机构包括招商证券/上海证券/济安金信,其筛选结果如何,我们看看。其评级已为浮点数,如果选四星以上的也方便运算。 #目前来看,我们不缺好基金,继续以3个五星评价的严格条件进行筛选。 df_T.head(2) df_T_total=df_T[df_T.Fivestars_of_count==3] df_T_total.describe() #看一下还有52家。不多。 df_T_last=df_T_total
#最后,才是投资者关心的,大数据支撑之下,哪些基金才是值得投资的。 #前面我们进行了初步筛选后的基金的DataFrame数据openF_total,这个更多考虑的是收益率与收益稳定性。 openF_total.describe()
为了保证结构的完整性,这里放上部分Excel数据透视表做成的数据透视图:



#再结合晨星网的三星以上评级,我们进行二次筛选,也得出了另一个DataFrame,df_RF_CX df_RF_CX.describe() #我们看到还有295个基金,对于选择来说,还是有点多。继续利用三家证券评级公司的数据进行帅选。结合晨星网数据后的优良基金。 #结合历年分红金额和分红数据,我们还获取了一个DateFrame。divF_total divF_last.describe() #一共544个。 #获得三家评级公司均5星评价的基金,如下: df_T_last.describe()#一共52家
第五部,就是相当于把以上的结果综合起来了,其最终的文件,我们选择保存在电脑当中。以此结束数据分析这步。
#最后是见证优质基诞生的时候了。
df1=pd.merge(df_RF_CX,divF_last,on='code') #结合了收益率,晨星评级还有分红三个因素。
df2=pd.merge(df1,df_T_last,on='code') #在df1的基础上,再加上三大证券公司的评级。
result=df2.T.drop_duplicates().T
WorthyOfInvestment=result.drop(columns=result['name_x']) #看到有些网站对命名显示简称,我们取一列即可。
WorthyOfInvestment.to_excel('D:/PythonData/优质投资基金2019年8月.xlsx')
为避免推荐基金的嫌疑,其最终的结果截取部分如下:除了工银金融地产,其他基金都是老基。经受住了时间的考验,相信以后,还会继续给我们带来惊喜。老基成立以来有2个,更是有10倍的收益率。而2013年相对新的,也有2.4倍收益率。年化15%的复利收益率,很可靠。(得益于这几年金融地产行业股票的股份拉升)。

第五部分 洞察与结论
在这里,主要描述了分析的流程步骤,还有技术实现。主要分析部分放在数据分析报告,这里做一下简单的分析结论:
1)今年投基金比去年投基金的收益率要好好多;去年做基金,大概律面临亏损的状况;
2)期望收益率15%是一个比较难达到的门槛,但是10%左右,按照目前的基金回报率,大概率是可以实现的;负收益率的基金还是不少的,基金经理也不一定专业;
3)易方达,景顺长城,前海开源这三家公司的基金整体质量都不错;而对于评级而言,结合我们选出来的数据的回报率,至少五星级评级的基金,是我们长期投资的很重要的参考对象;
4)选择好的基金经理并追踪他的基金,确实可以让我们投资更加安心,好的基金经理,非常重要;
5)一句话概括投资建议:好基,好基金公司,好基金经理,好时机,好的期望,好的收益率。

- Python操纵 Excel 文件实现复杂数据分析
- Python实现的大数据分析操作系统日志功能示例
- [转] websocket新版协议分析+python实现 & websocket 通信协议
- python 域名分析工具实现代码
- 使用Storm实现实时大数据分析
- 养老投资计划——定期定投指数基金分析(下)
- python实现汉字转拼音和读写excel
- 使用Storm实现实时大数据分析!
- Python——主成分分析及实现
- 用Python实现一个细粒度hadoop作业监控分析工具
- 一种分析代金券使用分布情况的方法python实现版(下)
- 能分析压缩的日志,且基于文件输入的PYTHON代码实现
- python实现Excel转json
- 使用Storm实现实时大数据分析!
- 大数据分析与机器学习领域Python兵器谱
- 二,使用Storm实现实时大数据分析实例:用storm来监测车辆速度是否超过80km/h
- python实现马耳可夫链算法实例分析
- 用Python实现简单的HTTP服务器(1)--使用Firebug简单分析HTTP协议
- ASP.NET下将Excel表格中的数据规则的导入数据库思路分析及实现
- python实现excel转json的例子