python读取excel数据(头文件处理)
1)对于第一行数据是脏数据的文件(非列名),可利用参数header指定超始行。
people=pd.read_excel(‘D:/test.xlsx’,header=1)
2)如果第一行或者前面的某几行都是空格的话,则可不指定,也可以顺利读取。
即people=pd.read_excel(‘D:/test.xlsx’)
3)而对于第一行是空的情况,没有任何其他数据,读取也是不正常的,则可先指定header=None,再对列名进行赋值即可。
people=pd.read_excel(D:/test,xlsx’,header=None)
people.columns=[‘id’,‘address’,‘title’]
4)指定index_col=‘ID’,可以避免其在导入导出中,由于Python与excel的不同,而导致第一列是不是数据或者索引而出现问题。
5)sheet1.append(sheet2).reset_index(drop=True),reset_index索引处,可以重设索引;而true参数,则把数据列2的ID也接着sheet1。
6)增加一行,则先创建一个Series,注意ignore_index=True。
如图:

7)插入一行,可以用切片方式,如下:

8)而删除,则也可以用切片方式删除:注意inplace=True.

有条件删除时,可以先写条件:
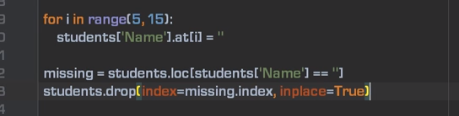
9)列操作,可用pd.concat…。
直接用列名,可以加一列:

删除列:

在第1列后,插入数据,指名列名,还有值即可:

用rename和字典(对)的形式,可对列名进行更改:

10)对于空值操作,可以用下面的方式dropna,浮点数(即可):

上面就是比较用常的excel文件处理,包括了头部文件处理,还有常用的行列处理,参考了青藤学院学习的一些资料。

- 【python图像处理】txt文件数据的读取与写入
- Java读取、写入、处理Excel文件中的数据
- Python使用pandas读取Excel文件数据和预处理小案例
- python读取文件的几种方式以及数据的处理
- Java读取、写入、处理Excel文件中的数据
- python数据分析-处理CSV/EXCEL表格文件
- python 在excel文件中写入date日期数据,以及读取excel日期数据,如何在python中正确显示date日期。
- Python导出数据到Excel可读取的CSV文件的方法
- Java读取、写入、处理Excel文件中的数据
- Python读取文件,路径问题,以及在对数据进行处理之前如何查看数据的相关信息
- 读书笔记--python数据可视化--002_读取Excel文件数据
- phpExcel 读取数据,大数据文件处理方案
- 如何处理ODBC中EXCEL驱动读取EXCEL文件中字段长度大于255字符时出现的"数据截断"问题.
- 处理EXCEL驱动读取EXCEL文件中字段长度大于255字符时出现的数据截断
- 使用OLEDB方式读取Excel文件到DataTable中数据类型的处理
- phpExcel 读取数据,大数据文件处理方案
- Python读取和处理文件后缀为".sqlite"的数据文件
- Python读取和处理文件后缀为.sqlite的数据文件(实例讲解)
- python读取Excel文件中的时间数据
- Selenium(Python) ddt读取Excel文件数据驱动