如何保证消息队列的高可用及消息不被重复消费?
在实际生产环境中,MQ承担着消息传递的作用,如果MQ意外挂掉了,整个系统就无法正常工作了,那么消息队列的高可用性就非常重要了。
本文主要讲RabbitMQ和kafka两个消息队列的高可用性分析。
一、 RabbitMQ的高可用(非分布式)
1.1 rabbitmq有三种模式:
- 单机模式
- 普通集群模式
- 镜像集群模式
1.1.1 单机模式
基本上是做Demo使用
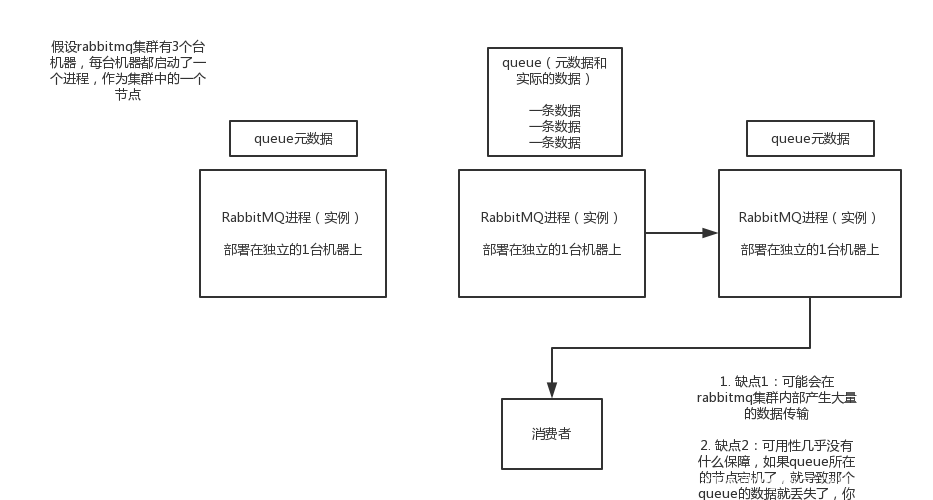
1.1.2 普通集群模式
多台服务器独立部署RabbitMQ,但是只有一台上有实际数据和元数据,其他服务器上只有元数据.。访问其他服务器的队列时,会向主服务器上的队列请求数据。
优点:能提高吞吐量
缺点:1,产生大量的内部数据传输
2,如果队列所在服务器宕机了,消息就丢失了,几乎没有高可用而言的
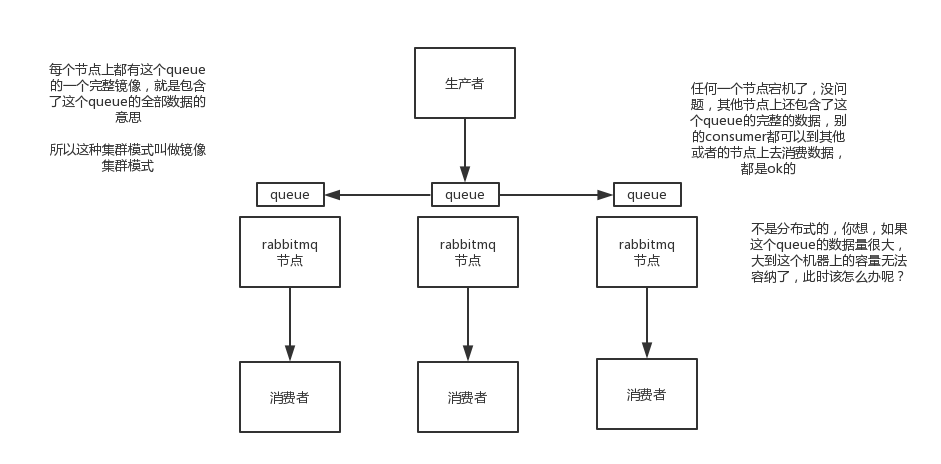
1.1.3 镜像集群模式
每个节点上都有完整的镜像,即有完整的数据。
优点:高可用,当其中一个节点宕机了,消费者去访问其他节点,都是可以拿到数据。
缺点:不是分布式,如果大到服务器无法容纳,该怎么办
(如何开启镜像集群:在管理控制台开启镜像集群,可以选择开启多少服务器镜像集群)
2 kafka的高可用性
kafka一个最基本的架构认识:多个broker组成,每个broker是一个节点;你创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。
这就是天然的分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。
每个topic消息分分多个partition发送到队列中,每个组中有多台服务器数据同步,其中一个为leader,其他为follower,当leader挂了,会选出一个follower做为leader持续工作,进而保证高可用

3 如何保证消息不被重复消费啊(如何保证消息消费时的幂等性)?
首先就是比如rabbitmq、rocketmq、kafka,都有可能会出现消费重复消费的问题,正常。因为这问题通常不是mq自己保证的,是给你保证的。然后我们挑一个kafka来举个例子,说说怎么重复消费吧。
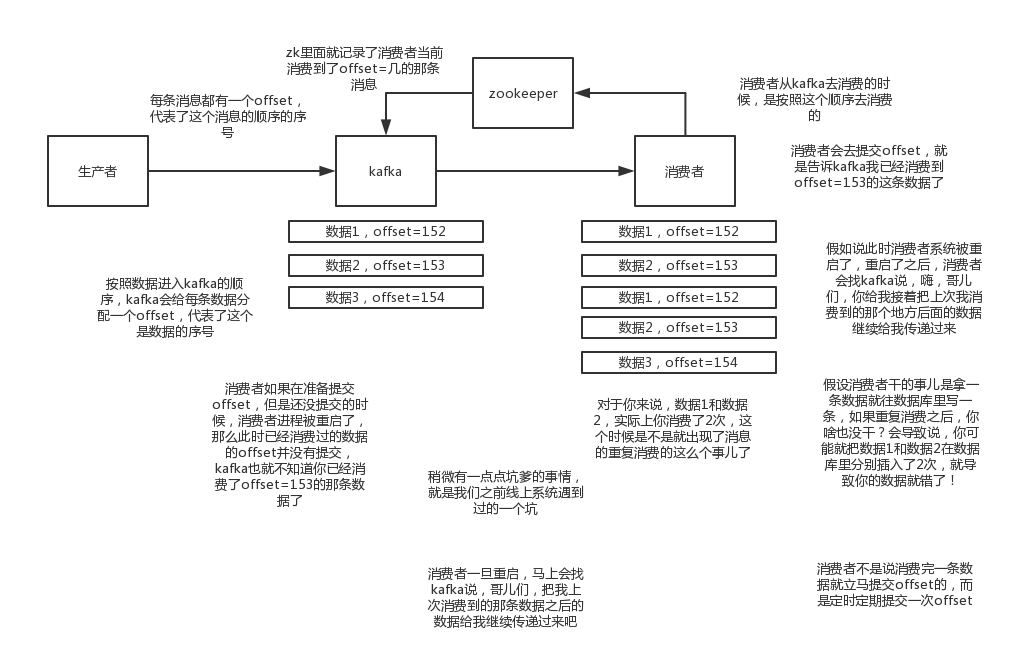
kafka实际上有个offset的概念,就是每个消息写进去,都有一个offset,代表他的序号,然后consumer消费了数据之后,每隔一段时间,会把自己消费过的消息的offset提交一下,代表我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的offset来继续消费吧。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接kill进程了,再重启。这会导致consumer有些消息处理了,但是没来得及提交offset,尴尬了。重启之后,少数消息会再次消费一次。
消费者不是每消费一条数据就返回一个offset,而是定时返回offset
怎么保证消息队列消费的幂等性?
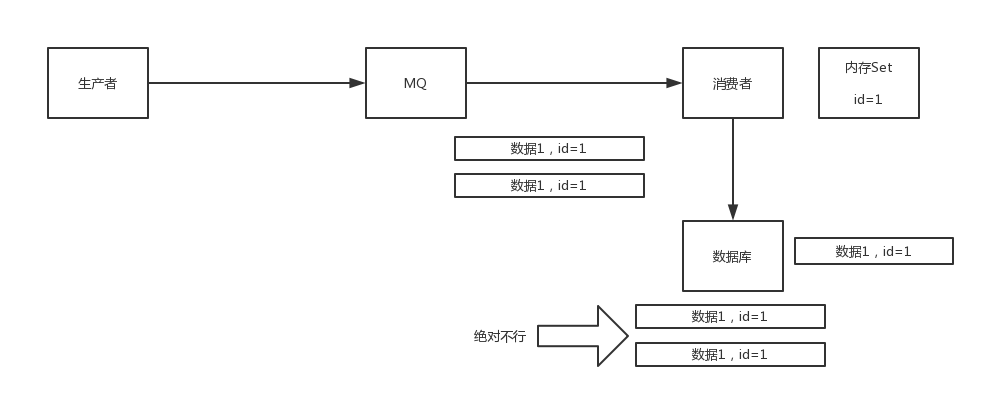
其实还是得结合业务来思考,我这里给几个思路:
(1)比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下好吧
(2)比如你是写redis,那没问题了,反正每次都是set,天然幂等性
(3)比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
还有比如基于数据库的唯一键来保证重复数据不会重复插入多条,我们之前线上系统就有这个问题,就是拿到数据的时候,每次重启可能会有重复,因为kafka消费者还没来得及提交offset,重复数据拿到了以后我们插入的时候,因为有唯一键约束了,所以重复数据只会插入报错,不会导致数据库中出现脏数据
如何保证MQ的消费是幂等性的,需要结合具体的业务来看

- 消息队列之如何保证消息没有重复消费?
- 如何保证消息队列消息不被重复消费
- RabbitMQ如何保证队列里的消息99.99%被消费?
- 如何保证消息队列的高可用?
- MQ如何保证消息不被重复消费
- 如何保证消息队列的高可用?
- 如何保证消息不被重复消费?(如何保证消息消费时的幂等性)
- 消息中间件面试题:如何保证消息不被重复消费?
- 如何保证消息队列的高可用?
- 如何保证消息不被重复消费?(如何保证消息消费的幂等性)
- 阿里Java面试题剖析:如何保证消息队列的高可用?
- 面试题剖析,如何保证消息队列的高可用?
- 【史上最强Java面试题系列】如何保证消息队列的高可用?
- 阿里面试题剖析,如何保证消息不被重复消费?
- 消息队列如何保证高可用呢
- 阿里面试题剖析,如何保证MQ消息不被重复消费?
- 阿里巴巴Java面试题剖析:如何保证消息不被重复消费?或者说,如何保证消息消费的幂等性?
- 如何保证消息不被重复消费?或者说,如何保证消息消费的幂等性?
- RabbitMQ如何保证队列里的消息99.99%被消费?
- RabbitMQ使用教程(五)如何保证队列里的消息99.99%被消费?