《Designing.Data-Intensive.Applications》笔记 一
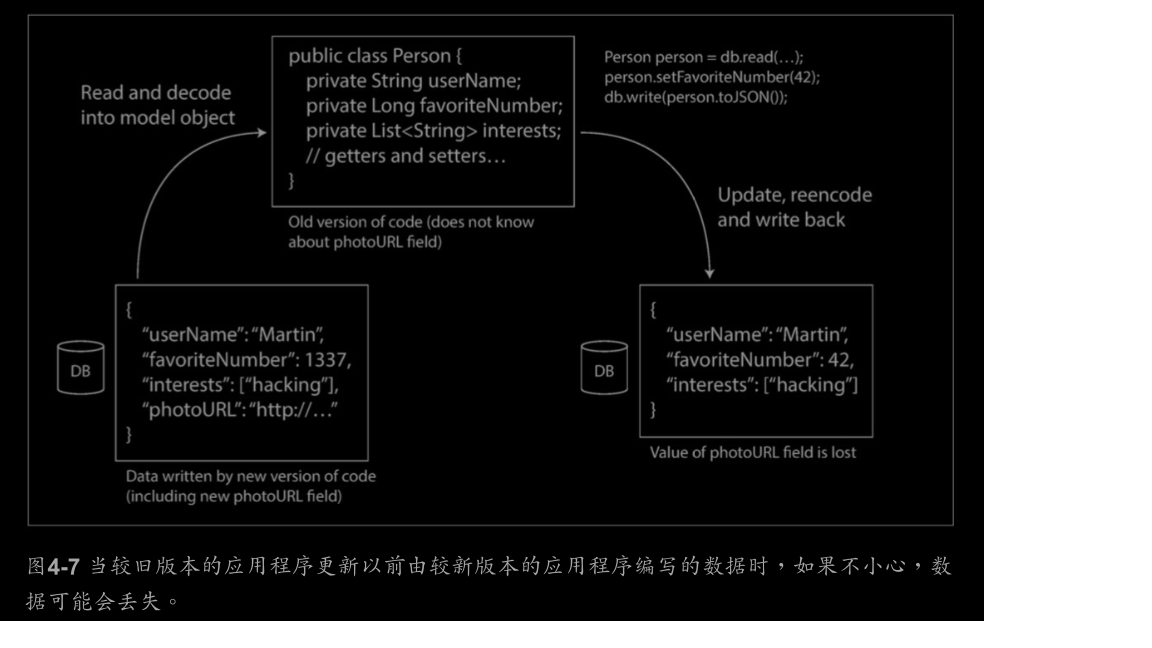
程序通常(至少)使用两种形式的数据:
1.内存中,数据保存在对象、结构体、列表、数组、哈希表、树等中。这些数据
结构针对CPU的高效访问和操作进行了优化(通常使用指针)。
2.如果要将数据写入文件,或通过网络发送,则必须将其编码(encode)为某种
字节序列(如JSON文档)。由于每个进程都有自己独立的地址空间,一个
进程的指针对其他进程没有任何意义,所以这个字节序列通常与内存中的
数据结构完全不同。
所以,需要在两种表示之间进行翻译。
内存到字节序列称为编码(Encoding)、序列化(serialization)、编组(marshalling)
字节序列到内存称为解码(Decoding)、反序列化(deserialization)、反编组(unmarshalling)、解析(parsing)
数据在流程之间流动的最常见方式:
- 通过数据库
- 通过服务调用(REST、RPC)
- 通过异步消息传递
数据库中,写入数据库的过程对数据进行编码,从数据库读取的过程对数据进行解码。
服务中的数据流:REST与SOA
当需要网络通信时,最常见的配置是两个角色:客户端和服务器。
服务器本身可以是另一个服务的客户端(典型的Web应用服务器充当数据库的客户端)
这种方法通常用于将大型应用程序按照功能区域分解为较小的服务,这样当一个服务
需要另一个服务的某些功能或数据时,会向另一个服务发出请求。这种构建应用程序
的方式称为面向服务的体系结构(service-oriented architecture,SOA)现在被改进为
微服务架构(microservices architecture)
当服务使用HTTP作为底层通信协议时,称之为Web服务。有两种流行的Web服务方法:REST、SOAP
REST(Representational State Transfer)不是一个协议,是基于HTTP原则的设计哲学,强调简单的数据格式。
SOAP(Simple Object Access Protocol)是基于XML的协议,与HTTP协议结合使用。
RPC(Remote Procedure Call)远程过程调用:
PRC要解决两个问题:
- 解决分布式系统中,服务之间的调用问题。
- 远程调用时,能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。
RPC与本地函数调用非常不同:
- 本地函数调用是可预测的,RPC不可预知;由于网络问题,请求和响应可能丢失。
但网络问题是常见的,必须预测它们,如重试失败的请求。
2. 本地函数要么返回结果,要么抛出异常,或永远不返回(无限循环或进程崩溃)。RPC
由于超时,可能返回没有结果。
3.如果重试失败的RPC,可能前一个请求已通过,只是响应丢失。除非你在协议中引入
除重idempotence机制。
4.本地方法,每次执行时间大致相同;RPC则慢得多,根据网络状况,时间波动也很大。
5.调用本地函数,可以高效的将引用(指针)传给本地内存中的对象。RPC所有参数必须被
编码成可用过网络发送的字节,如参数是较大的对象,就存在问题。
PRC与数据库之间的异步消息传递系统-通过消息中间件来临时存储信息
与直接RPC相比,使用消息中间件(message-oriented middleware)的优点:
- 如果收件人不可用或过载,可以充当缓冲区,提高系统可靠性;
- 可以自动将消息重新发送给已崩溃的进程,防止消息丢失;
- 避免发件人需要知道收件人的IP地址、端口号(虚拟机经常出入的云部署中有用)
- 允许将一条消息发送给多个收件人;
- 将收件人和发件人逻辑分离(发件人只发布邮件,不关心使用者)
中间件(也称Message brokers)的大体运行方式:
one process sends a message to a named queue or topic, and the broker ensures that
the message is delivered to one or more consumers of or subscribers to that queue or topic.
There can be many producers and many consumers on the same topic.
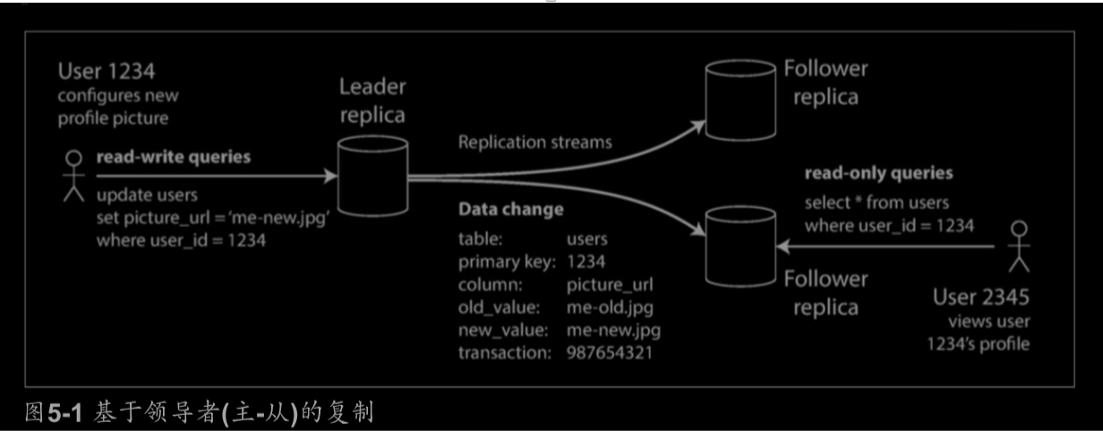
数据分布在多个节点上通常有两种方式:复制(Replication)、分区(Partitioning)
使用复制的原因:
- 使得数据与用户在地理上接近(从而减少延迟)
- 即使系统的一部分出现故障,系统还能正常工作
- 扩展可以接收读请求的机器数量(从而提高读取吞吐量)
复制的数据会随时间改变,因此处理复制数据的变更是难点,有三种流行的变更复制算法:
- singer leader(单领导者)
- multi leader(多领导者)
- leaderless(无领导者)
复制系统的一个重要细节:复制是同步还是异步发生
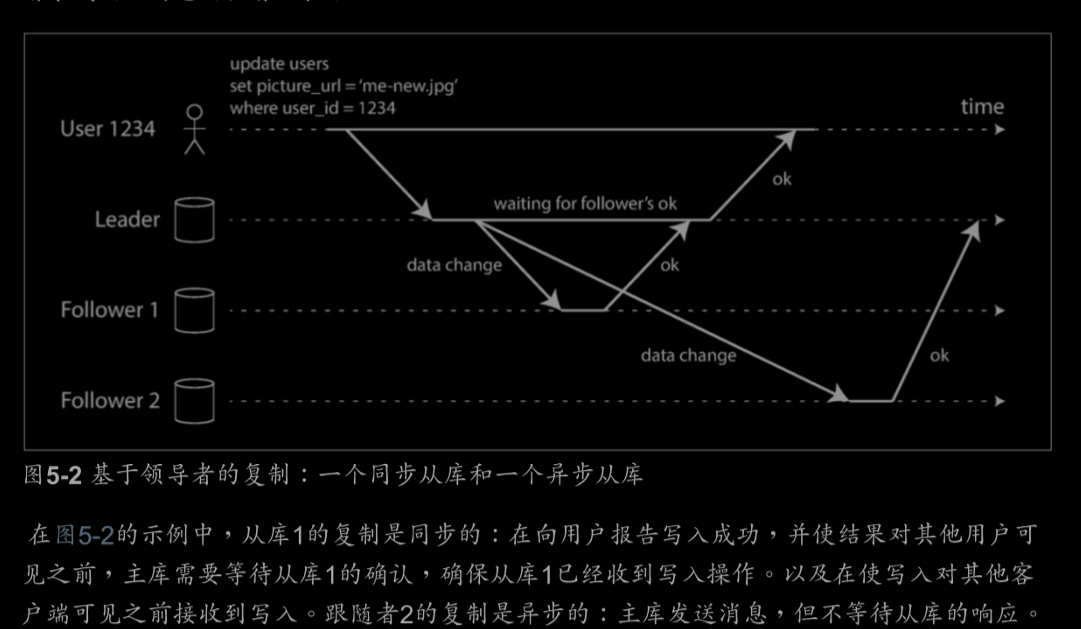
最终一致性(eventually consistency)

这种情况下,我们需要读写一致性(read-after-write consistency),也称读己之写一致性(read-your-writes consistency)

单调读(Monotonic Reads):
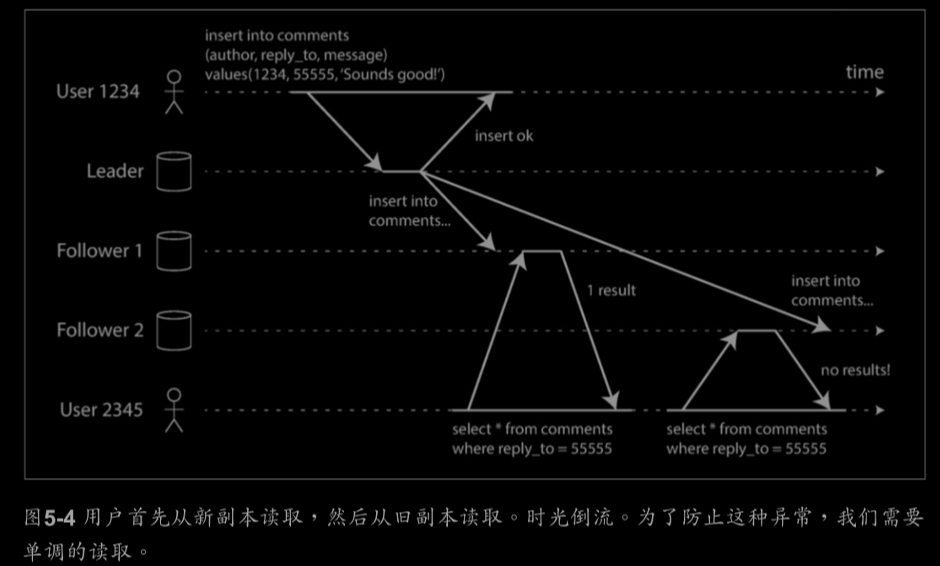
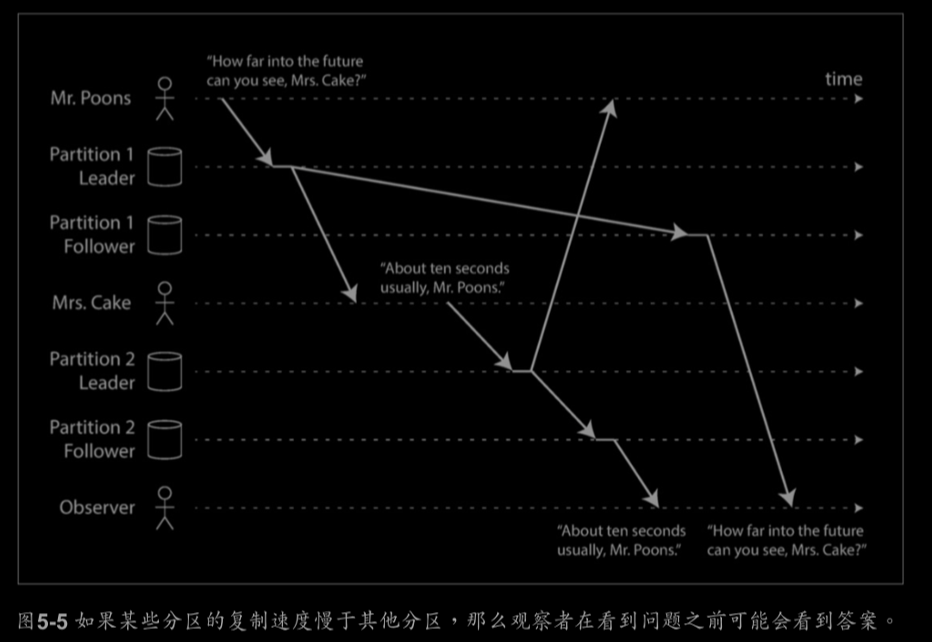
一致前缀读取(Consistent Prefix Reads):
如果一系列写入按某个顺序发生,那么任何人也会按同样的顺序读取
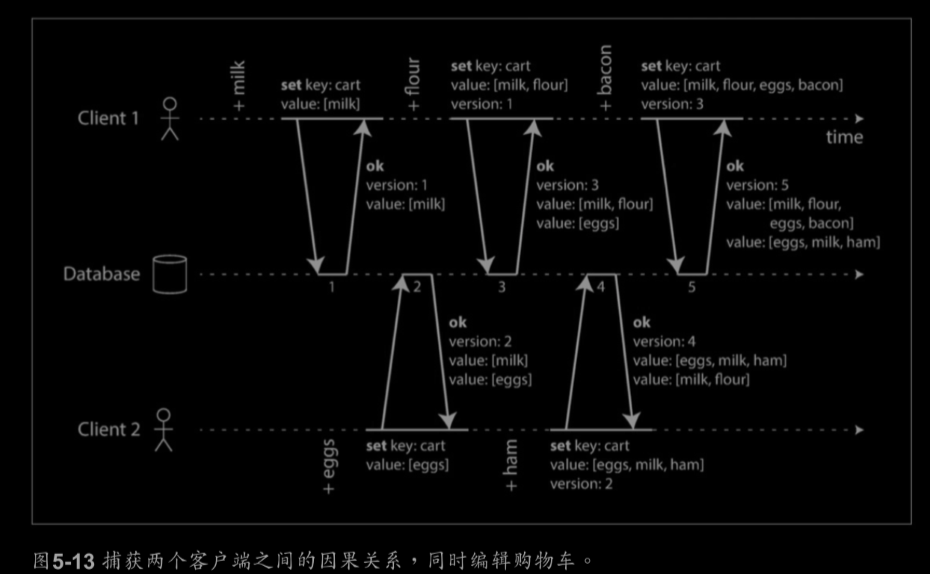
The "happens-before" relationship and concurrency(在之前发生与并发)

- 《Designing.Data-Intensive.Applications》笔记 四
- 《Designing.Data-Intensive.Applications》笔记 二
- 《Designing.Data-Intensive.Applications》笔记 三
- 《Data-Intensive_Text_Processing0Awith_MapReduce》笔记第3章
- Maryland-Data-Intensive Information Processing Applications/Cloud Computing - Jimmy LIN
- Building Applications with Force.com and VisualForce(Dev401)(十一):Designing Applications for Multiple Users: Proseving Data Quality
- 《Data-intensive Text Processing with MapReduce》读书笔记第2章:MapReduce基础(3)
- pandas笔记3:修改Dataframe一列的最大值及loc,iloc用法
- 【ASP.NET开发】菜鸟时期的.net笔记[about data binding]
- Effective C#阅读笔记-1.使用属性(Properties)代替数据成员(Data Member)
- Python学习笔记 --- Pycharm中遇到 no data sources are configured to run thi s sql...
- sencha touch 学习笔记- 基本属性-data 、Record和tpl(ps:博客园phonegap版rss 阅读器可以用了,在被窝里逛园子)
- Building Applications with Force.com and VisualForce(Dev401)( 九):Designing Applications for Multiple Users: Putting It All Together
- spring data elasticsearch学习笔记_02自动化测试用例
- spring data elasticsearch学习笔记_03参数校验
- SPRING IN ACTION 第4版笔记-第九章Securing web applications-011-把敏感信息请求转为https(requiresChannel())
- [深度学习论文笔记][Weight Initialization] Data-dependent Initializations of Convolutional Neural Networks
- SPRING IN ACTION 第4版笔记-第十一章Persisting data with object-relational mapping-003编写JPA-based repository( @PersistenceUnit、 @PersistenceContext、PersistenceAnnotationBeanPostProcessor)
- Web Mining and Big Data 公开课学习笔记 ---lecture1
- 【深度学习】【caffe实用工具1】笔记23 Windows下【Caffe实用工具】之convert_cifar_data的用法