[Python 爬虫] 使用 Scrapy 爬取新浪微博用户信息(二) —— 编写一个基本的 Spider 爬取微博用户信息
上一篇:[Python 爬虫] 使用 Scrapy 爬取新浪微博用户信息(一) —— 新建爬虫项目
在上一篇我们新建了一个 sina_scrapy 的项目,这一节我们开始正式编写爬虫的代码。
选择目标网站
目前,新浪微博主要有三个域名,分别是:微博简化版(https://weibo.cn)、微博移动端(https://m.weibo.cn)、微博PC网页端(https://weibo.com/)反爬的技术也是逐渐加强。从上文我们创建 Spider 所填写的域名也可以看出,我们选用的是微博简化版(https://weibo.cn)作为爬取对象。
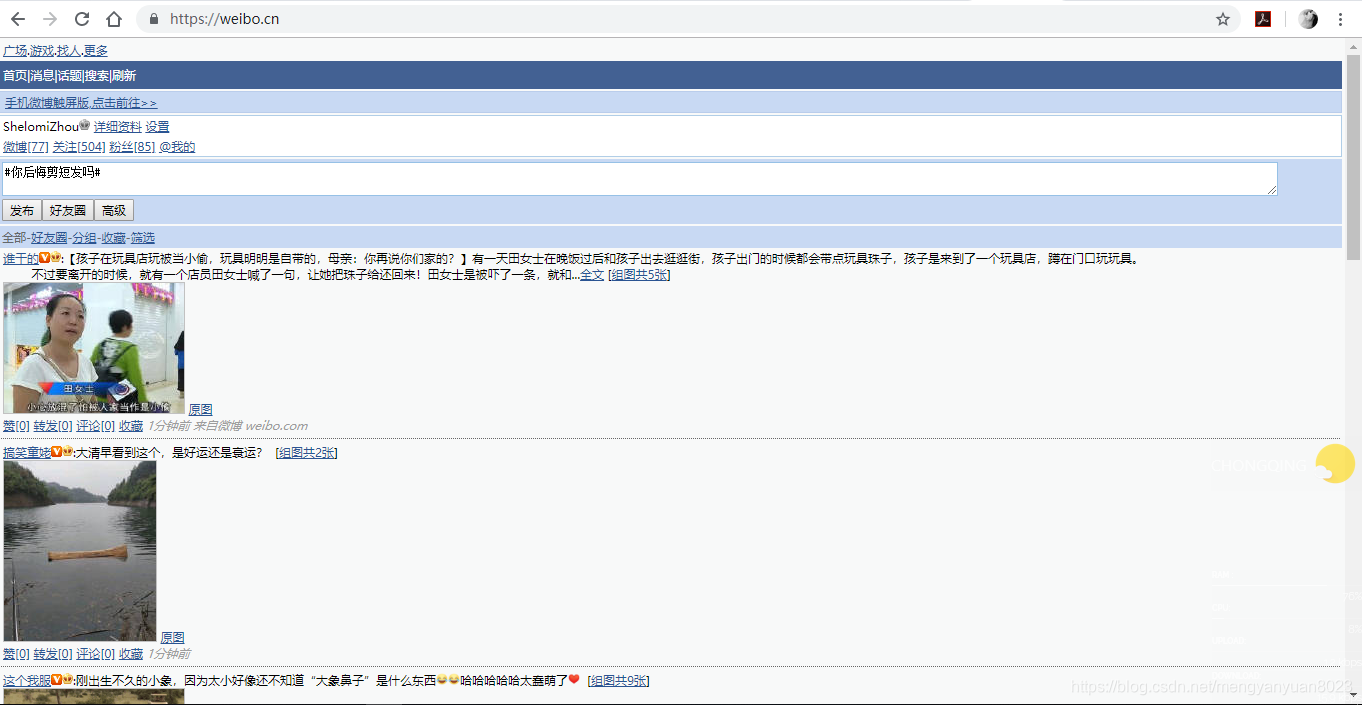

编写数据模型(Items)
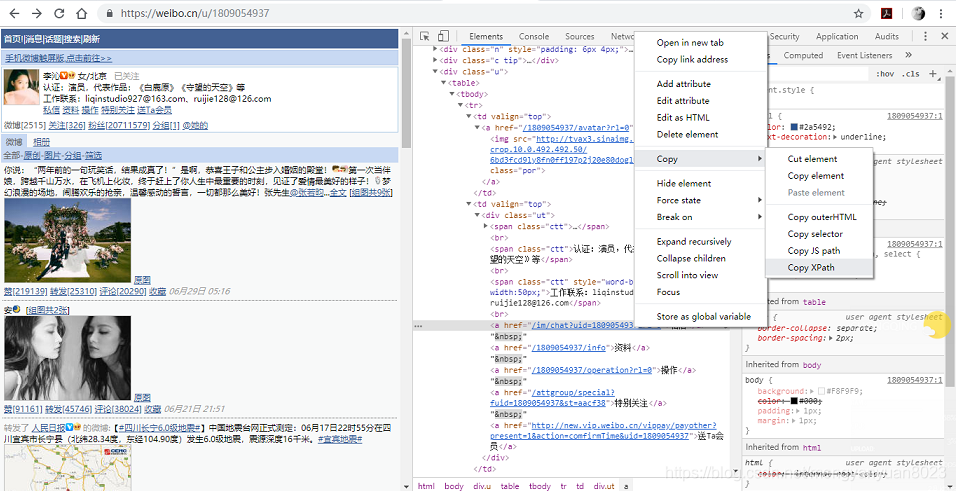
我们首先明确需要获得微博用户哪些信息。我们在访问每一位用户的主页的时候 URL 上都由域名+"u"+一串数字组成,类似:https://weibo.cn/u/1809054937,而且每个用户主页URL后面那串数字都不一样,通过分析网页源码也能看到这串数字在很多关键位置都有出现,于是可以推断,这串数字就是微博用户的ID。当然,有些认证的名人主页 URL 后面跟随的不是用户ID,但是依然能从网页源码中得到用户ID,如下图:

从上图中我们能够得到的用户信息包括:用户Id、用户昵称、认证信息、简介、微博数、关注数、粉丝数等,然后我们继续点开资料,能够进一步获得更详细的信息,包括:昵称、认证、性别、地区、认证信息、简介(其他还有工作信息、教育信息等,这里不考虑)。当然,这些信息并非所有用户都有,毕竟不是每个人都会仔细填写这些资料信息的。

经过整理,我们决定爬取如下表列出的数据:
| 字段名 | 字段类型 | 字段描述 |
|---|---|---|
| user_id | str | 微博用户Id,微博用户的唯一标识 |
| username | str | 用户昵称 |
| webo_num | int | 发布的微博数量 |
| follow_num | int | 用户的关注人数 |
| fans_num | int | 用户的粉丝人数 |
| gender | str | 用户性别 |
| district | str | 地区 |
| province | str | 省份 |
| city | str | 城市 |
| birthday | str | 生日 |
| identify | str | 认证 |
| head_img | str | 用户头像url |
| crawl_time | str | 记录爬取时间 |
上一篇我们提到 Items 文件主要用来定义要爬取的数据模型,接下来我们就按照上面的数据字典来编写 Item,在 items 文件下编写 SinaUserItem 类,继承 scrapy.Item,代码如下:
[code] import scrapy class SinaUserItem(scrapy.Item): # 微博用户唯一标识 user_id = scrapy.Field() # 用户昵称 username = scrapy.Field() # 微博数量 webo_num = scrapy.Field() # 关注人数 follow_num = scrapy.Field() # 粉丝人数 fans_num = scrapy.Field() # 性别 gender = scrapy.Field() # 地区 district = scrapy.Field() # 省份 province = scrapy.Field() # 地市 city = scrapy.Field() # 生日 birthday = scrapy.Field() # 简介 brief_intro = scrapy.Field() # 认证 identify = scrapy.Field() # 头像 URL head_img = scrapy.Field() # 爬取时间 crawl_time = scrapy.Field()
编写 Spider
在上一篇帖子中,我们在 spider 包下生成了一个爬虫应用(Spider)sina_user,代码如下。它继承了 scrapy.Spider,并为我们初始化了一些属性和方法。其中:name 是 spider 的名字,是每一个 spider 的唯一标识,allowed_domains 是一个列表类型的变量,表示爬虫允许爬取的域名范围,解析到的 request 不属于这个域名内就会被爬虫丢弃。starts_url 是爬虫开始的地址,如果不为空,第一个地址将是爬取的第一页面,也就是爬虫的入口,如果 starts_url 为空或者不填写,就必须重写父类的 start_request 方法,指定爬虫的入口。parse() 方法是爬虫的默认解析方法,用于解析 下载中间件(Downloader) 返回给 Spider 的数据。
[code]# -*- coding: utf-8 -*- import scrapy class SinaUserSpider(scrapy.Spider): # 爬虫的名字,唯一标识 name = 'sina_user' # 允许爬取的域名范围 allowed_domains = ['weibo.cn'] # 爬虫的起始页面url start_urls = ['http://weibo.cn/'] def parse(self, response): """ 默认解析函数 :param response: :return: """ pass
我们开始编写一个最简单的爬虫,爬取 李沁 的微博信息,首先在浏览器打开 李沁 的微博,然后按 F12 调试窗口,打开页面源码,如下所示:

当我们抓取网页时,通常都需要分析网页源码,然后通过元素获取到数据,Scrapy提取数据有自己的一套机制,被称作选择器(Selector),当然,你也可以选择其他框架,例如:BeautifulSoup、lxml 。在这里我们采用Selector,通过右击元素,然后选择 Copy -> Copy XPath 就可以获取元素的 xpath 路径了。
在提取页面数据的时候,我们先构造一个选择器(Selector)
[code]# 构造选择器(由于在response中使用XPath、CSS查询十分普遍,因此,Scrapy提供了两个实用的快捷方式: response.xpath() 及 response.css(),不过为了学习Selector,我们还是构造一个Selector) selector = scrapy.Selector(response)
在微博用户首页,我们能获取到的数据有:user_id、webo_num、follow_num、fans_num。分别解析这几个数据:
[code]# 解析微博用户 id
re_url = selector.xpath('//div[@class="tip2"]/a[4]/@href').re('uid=(\d{10})')
user_id = re_url[0] if re_url else ''
# 微博数
webo_num_re = selector.xpath('//div[@class="tip2"]').re(u'微博\[(\d+)\]')
webo_num = int(webo_num_re[0]) if webo_num_re else 0
# 关注人数
follow_num_re = selector.xpath('//div[@class="tip2"]').re(u'关注\[(\d+)\]')
follow_num = int(follow_num_re[0]) if follow_num_re else 0
# 粉丝人数
fans_num_re = selector.xpath('//div[@class="tip2"]').re(u'粉丝\[(\d+)\]')
fans_num = int(fans_num_re[0]) if fans_num_re else 0
另外,我们将提取的数据装载到数据模型中去,这里我们使用 Scrapy 提供的装载器(Loader)来构造数据模型。
[code]# 装载器(Loader) load = ItemLoader(item=SinaUserItem(), response=response)
页面分析完以后,我们还不能成功访问微博页面,因为我们发送的请求没有登录的身份信息,很容易被微博服务器判定为爬虫程序,然后禁止我们访问。目前只是为了熟悉爬虫的过程,我们先从浏览器复制登录的 Cookies,然后构造 Headers,来发送请求(后续会增加 IP代理池和 Cookies池),如下图,打开调试模式 Network,任意找到一个请求,点开 Headers,复制Request Headers,如下图所示:
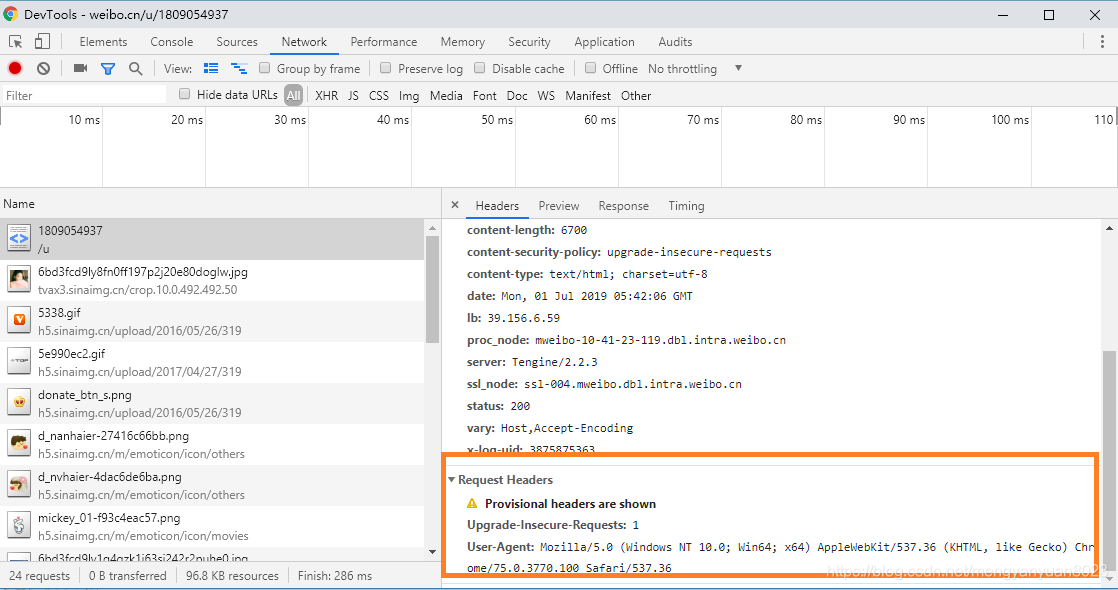
然后在Application-》Cookies 复制以下值到我们的代码中:
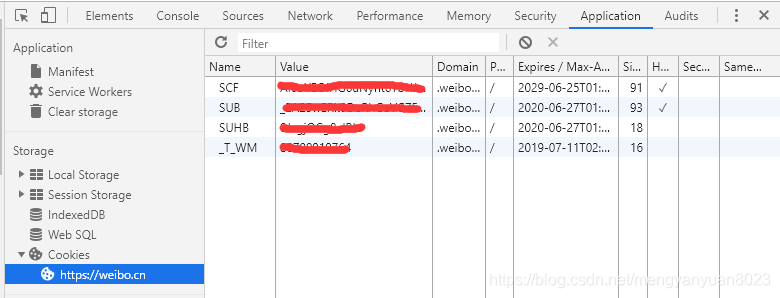
SinaUserSpider的完整代码如下(已隐去 Cookies 的值)需要注意的是,装载器(Loader)只有在最后调用 load_item() 方法时才将所有数据装载到装载器,在此之前装载器中并没有 items 的数据:
[code]# -*- coding: utf-8 -*-
import scrapy, time
from scrapy.loader import ItemLoader
from sina_scrapy.items import SinaUserItem
class SinaUserSpider(scrapy.Spider):
# 爬虫的名字,唯一标识
name = 'sina_user'
# 允许爬取的域名范围
allowed_domains = ['weibo.cn']
# 爬虫的起始页面url
start_urls = ['https://weibo.cn/u/1809054937']
def __init__(self):
self.headers = {
'Referer': 'https://weibo.cn/u/1809054937',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
self.cookies = {
'SCF': 'xxxxxxxxxxxxx',
'SUB': 'xxxxxxxxxxxxx',
'SUHB': 'xxxxxxxxxxxxxxx',
'_T_WM': xxxxxxxxxxxxxxx
}
def start_requests(self):
"""
构造最初 request 函数\n
:return:
"""
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.base_info_parse, headers=self.headers, cookies=self.cookies)
def base_info_parse(self, response):
"""
微博用户基本信息解析函数\n
:param response:
:return:
"""
# 加载器(Loader)
load = ItemLoader(item=SinaUserItem(), response=response)
selector = scrapy.Selector(response)
# 解析微博用户 id
re_url = selector.xpath('///a[contains(@href,"uid")]/@href').re('uid=(\d{10})')
user_id = re_url[0] if re_url else ''
load.add_value('user_id', user_id)
# 微博数
webo_num_re = selector.xpath('//div[@class="tip2"]').re(u'微博\[(\d+)\]')
webo_num = int(webo_num_re[0]) if webo_num_re else 0
load.add_value('webo_num', webo_num)
# 关注人数
follow_num_re = selector.xpath('//div[@class="tip2"]').re(u'关注\[(\d+)\]')
follow_num = int(follow_num_re[0]) if follow_num_re else 0
load.add_value('follow_num', follow_num)
# 粉丝人数
fans_num_re = selector.xpath('//div[@class="tip2"]').re(u'粉丝\[(\d+)\]')
fans_num = int(fans_num_re[0]) if fans_num_re else 0
load.add_value('fans_num', fans_num)
# 记录爬取时间
load.add_value('crawl_time', time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
return load.load_item()
我们打开编译器的 Console,进入到 sina_scrapy 目录下,执行以下命令,启动爬虫:
[code]scrapy crawl sina_user
运行结果如下:
往下翻,能够看到这样一行信息:被 rebots.txt 禁止。 rebots.txt 是一种网络爬虫排除标准,但并不是强制的,类似于服务器与爬虫程序之间的一种“君子协定”。
[code]2019-07-01 17:42:20 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://weibo.cn/u/1809054937>
我们只需要在 settings 文件里面关闭这个设置就行了:
[code]# 是否遵循网络爬虫排除标准 ROBOTSTXT_OBEY = False
然后我们再次运行爬虫程序,就可以看到输出我们爬取的信息:
[code]2019-07-01 17:52:56 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weibo.cn/u/1809054937>
{'crawl_time': ['2019-07-01 17:52:56'],
'fans_num': [20714189],
'follow_num': [326],
'user_id': ['1809054937'],
'webo_num': [2515]}
至此,我们已经成功编写了一个简单的爬虫应用了!
总结
在这一篇博客中,主要介绍了如何编写一个 Scrapy 的爬虫应用,以及 Scrapy 用到的基本技术,下一篇将扩展爬取的信息,并添加分页的爬取以及介绍如何编写 item pipline 将爬取到的数据保存到 MongoDB 中。
下一篇:[Python 爬虫] 使用 Scrapy 爬取新浪微博用户信息(三) —— 数据的持久化——使用MongoDB存储爬取的数据

- [Python 爬虫] 使用 Scrapy 爬取新浪微博用户信息(三) —— 数据的持久化——使用MongoDB存储爬取的数据
- python使用cookie登陆新浪微博用户信息
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
- python爬虫批量抓取新浪微博用户ID及用户信息、微博内容
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
- Python爬虫小实践:使用BeautifulSoup+Request爬取CSDN博客的个人基本信息
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
- 使用Python编写爬虫的基本模块及框架使用指南
- 搜索引擎–Python下开源爬虫(spider)框架scrapy的使用
- 【python爬虫02】使用Scrapy框架爬取拉勾网招聘信息
- python爬虫实战笔记---以轮子哥为起点Scrapy爬取知乎用户信息
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- Python中使用Scrapy爬虫抓取上海链家房价信息
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
- 欢迎使用CSDN-markdown编辑器一个用于定期增量式解析 Scrapy 爬虫日志的 Python 库,配合 ScrapydWeb 使用可实现爬 ...
- 使用scrapy模块编写爬虫,运行出现spider中 no moudle named ‘item’问题
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- 零基础写python爬虫之使用Scrapy框架编写爬虫