IO同步、异步与多路复用
 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
1. 重要概念
1.1 同步、异步
函数或方法被调用的时候,调用者是否能得到最终结果。直接得到最终结果的,就是同步调用,不直接得到最终结果的,就是异步调用。
1.2 阻塞、非阻塞
函数或方法调用的时候,是否like返回,立即返回就是非阻塞调用,不立即返回就是阻塞调用。
同步、异步,与阻塞、给阻塞不相关,同步、异步强调的是,是否得到最终的结果,阻塞、非阻塞强调是时间,是否等待。
同步与异步区别在于:调用者是否得到了想要的最终结果。 同步就是一直要执行到返回最终结果; 异步就是直接返回了,但是返回的不是最终结果。调用者不能通过这种调用得到结果,需要通过被调用者的其它方 式通知调用者,来取回最终结果。 阻塞与非阻塞的区别在于,调用者是否还能干其他事。 阻塞,调用者就只能干等; 非阻塞,调用者可以先去忙会别的,不用一直等。
1.3 操作系统知识
X86 CPU有4种工作级别:
Ring0,可以执行特权指令,可以访问所有级别数据,可以访问IO设备等。Ring3级,级别最低,只能访问本级别数据。内核代码运行在Ring0,用户代码运行在Ring3。
操作系统中,内核程序独立且运行在 较高的特权级别上,它们驻留在被保护的内存空间上,拥有访问硬件的所有权限,这部分内存称为内核空间(内核态)
普通应用程序运行在用户空间(用户态)。应用程序想访问某些硬件资源就需要通过操作系统提供的系统调用,系统调用可以使用特权指令运行在内核空间,此时进程陷入内核态运行。系统调用完成,进程将返回到用户态执行用户空间代码。

1.4 同步IO、异步IO、IO多路复用
1.4.1 IO两个阶段
- 数据准备阶段。内核从设备读取数据到内核空间的缓冲区
- 内核空间复制回用户空间进程缓冲区阶段
发生IO的时候:
- 内核从IO设备读数据
- 进程从内核复制数据
1.5 IO模型
1.5.1 同步IO
同步IO模型包括阻塞IO、非阻塞IO、IO多路复用
阻塞IO:

进程等待(阻塞),直到读写完成。(全程等待)
非阻塞IO:

进程调用recvfrom操作,如果IO设备没有准备好,立即返回ERROR,进程不阻塞。用户可以再次发起系统调用(可以轮询)。如果内核已经准备好,就阻塞,然后复制数据到用户空间。
第一阶段数据没有准备好,可以先忙别的,等会再来看看,检查数据是否准备好了的过程是非阻塞的。第二阶段是阻塞的,即内核空间和用户空间之间复制数据是阻塞的。
IO多路复用:
所谓IO多路复用,就是同时监控多个IO,有一个准备好了,就不需要等了开始处理,提高了同时处理IO的能力。select几乎所有操作系统平台都支持,poll是对select的升级。epoll,Linux系统内核2.5+开始支持,对select和poll的升级,在监视的基础上,增加了回调机制。BSD、Mac平台有kqueue,Windows有iocp。

以select为例,将关注的IO操作告诉select函数并调用,进程阻塞,内核“监视”关注的文件描述符fd,被关注的任意一个fd对应的IO准备好了数据,s 7ff7 elect返回。再使用read将数据复制到用户进程。
一般情况下,select最多能监听1024个fd,但是由于select采用轮询的方式,当管理的IO多了,每次都要 遍历全部fd,效率低下。epoll没有管理的fd上限,且是回调机制,不需遍历,效率很高。
信号驱动IO:
进程在IO访问时,先通过sigaction系统调用,提交一个信号处理函数,立即返回,进程不阻塞。当内核准备好数据后,产生一个SIGIO信号并投递给信号处理函数,可以在此函数中调用recvfrom函数操作数据从内核空间复制到用户空间,这段过程阻塞。

异步IO: (注意:回调是被调用者做得,不是调用者)
进程发起异步IO请求,立即返回。内核完成IO的两个阶段,内核给进程发一个信号。在整个过程中,进程都可以忙别的,等好了再过来。

Linux的aio的系统调用,内核从版本二2.6开始支持:

1.6 python中的IO多路复用
IO多路复用:
- 大多数操作系统都支持select和poll
- Linux2.5+支持epoll
- BSD、Mac支持kqueue
- Solaris实现了/dev/poll
- WindowsDE IOCP
python的select库实现了select、poll系统调用,这个基本上操作系统都支持。部分实现了epoll,它是底层的额IO多路复用模块。
开发中的选择:
- 完全跨平台,使用select、poll。但是性能较差。
- 针对不同操作系统自行选择支持的技术,这样做会提高IO处理的性能。
select维护一个文件描述符数据结构,单个进程使用有上限,通常是1024,线性扫面这个数据结构,效率低。poll和select的区别是内部数据结构使用链表,没有这个最大限制,但是依然要遍历才能知道哪个设备就绪了。epoll、使用事件通知机制,使用回调机制提高效率。select、poll还要从内核空间复制数据到用户空间,而epoll通过内核空间和用户空间共享一块内存来减少复制。
1.6.1 selectors库
poython3.4提供了selectors库,高级的IO复用库。
类层次结构:
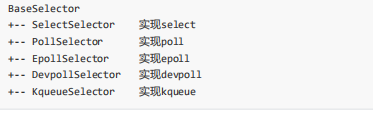
selectors.DefaultSelector返回当前平台最有效、性能最高的实现。但是没有实现Windows下的IOCP,所以,Windows下只能退化为select。
[code]# 在selects模块源码最下面有如下代码 # Choose the best implementation, roughly: # epoll|kqueue|devpoll > poll > select. # select() also can't accept a FD > FD_SETSIZE (usually around 1024) if 'KqueueSelector' in globals(): DefaultSelector = KqueueSelector elif 'EpollSelector' in globals(): DefaultSelector = EpollSelector elif 'DevpollSelector' in globals(): DefaultSelector = DevpollSelector elif 'PollSelector' in globals(): DefaultSelector = PollSelector else: DefaultSelector = SelectSelector
事件注册:
[code]class SelectSelector(BaseselctorImpol): """Select-based selector.""" def register(fileobj, events, data=None) -> SelectorKey: pass
- 为selector注册一个文件对象,监视它的IO事件,返回SelectorKey对象。
- fileobj 被监视文件对象,例如socket对象
- events 事件,该文件对象必须等待的事件
- data 可选的与此文件对象相关联的不透明数据,例如,关联用来存储每个客户端的会话ID,关联方法。通过这个 参数在关注的事件产生后让selector干什么事。

EVENT_READ = (1 << 0)
EVENT_WRITE = (1 << 1)
这样定义常量的好处是便于合并
selectors.SelectorKey有4个属性:
- fileobj注册的文件对象
- fd文件描述符
- events等待上面的文件描述符的文件对象的事件
- data注册时关联的数据
IO多路复用实现TCP Server:
[code]import selectors
import socket
s = selectors.DefaultSelector() # 1拿到selector
# 准备类文件对象
server = socket.socket()
server.bind(('127.0.0.1', 9997))
server.listen()
# 官方建议采用非阻塞IO
server.setblocking(False)
def accept(sock: socket.socket, mas: int):
conn, r_address = sock.accept()
# print(conn)
# print(r_address)
print(mas)
# pass
conn.setblocking(False)
key1 = s.register(conn, selectors.EVENT_READ, rec)
print(key1)
def rec(conn: socket.socket, mas: int):
print(mas)
data = conn.recv(1024)
print(data)
msg = 'Your msg = {} form {}'.format(data.decode(), conn.getpeername())
conn.send(msg.encode())
# 2注册关注的类文件对象和其事件们
key = s.register(server, selectors.EVENT_READ, accept) # socket fileobject
print(key)
while True:
events = s.select() # epoll select,默认是阻塞的
# 当你注册时的文件对象们,这其中的至少一个对象关注的事件就绪了,就不阻塞了
print(events) # 获得了就绪的对象们,包括就绪的事件,还会返回data
for key, mask in events: # event =>key, mask
# 每一个event都是某一个被观察的就绪的对象
print(type(key), type(mask)) # key, mask
# <class 'selectors.SelectorKey'> <class 'int'>
print(key.data)
# <function accept at 0x0000000001EA3A60>
key.data(key.fileobj, mask) # mask为掩码
server.close()
s.close()
IO多路复用实现群聊:
[code]# IO多路复用,实现TCP版本的群聊
import socket
import threading
import selectors
import logging
FORMAT = "%(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
class ChatServer:
def __init__(self, ip='127.0.0.1', port=9992):
self.sock = socket.socket()
self.address = ip, port
self.event = threading.Event()
self.selector = selectors.DefaultSelector()
def start(self):
self.sock.bind(self.address)
self.sock.listen()
self.sock.setblocking(False)
key = self.selector.register(self.sock, selectors.EVENT_READ, self.accept) # 只有一个
logging.info(key) # 只有一个
# self.accept_key = key
# self.accept_fd = key.fd
threading.Thread(target=self.select, name='select', daemon=True).start()
def select(self):
while not self.event.is_set():
events = self.selector.select() # 阻塞
for key, _ in events:
key.data(key.fileobj) # select线程
def accept(self, sock: socket.socket): # 在select线程中运行的
new_sock, r_address = sock.accept()
new_sock.setblocking(False)
print('~' * 30)
key = self.selector.register(new_sock, selectors.EVENT_READ, self.rec) # 有n个
logging.info(key)
def rec(self, conn: socket.socket): # 在select线程中运行的
data = conn.recv(1024)
logging.info(data.decode(encoding='cp936'))
if data.strip() == b'quit' or data.strip() == b'':
self.selector.unregister(conn) # 关闭之前,注销,理解为之前的从字典中移除socket对象
conn.close()
return
for key in self.selector.get_map().values():
s = key.fileobj
# if key.fileobj is self.sock: # 方法一
# continue
# if key == self.accept_key: # 方法二
# continue
# if key.fd == self.accept_fd: # 方法三
# continue
# msg = 'Your msg = {} form {}'.format(data.decode(encoding='cp936'), conn.getpeername())
# s.send(msg.encode(encoding='cp936'))
# print(key.data)
# print(self.rec)
# print(1, key.data is self.rec) # False
# print(2, key.data == self.rec) # True
if key.data == self.rec: # 方法四
msg = 'Your msg = {} form {}'.format(data.decode(encoding='cp936'), conn.getpeername())
s.send(msg.encode(encoding='cp936'))
def stop(self): # 在主线程中运行的
self.event.set()
fs = set()
for k in self.selector.get_map().values():
fs.add(k.fileobj)
for f in fs:
self.selector.unregister(f) # 相当于以前的释放资源
f.close()
self.selector.close()
if __name__ == "__main__":
cs = ChatServer()
cs.start()
while True:
cmd = input(">>>").strip()
if cmd == 'quit':
cs.stop()
break
logging.info(threading.enumerate())
logging.info(list(cs.selector.get_map().keys()))
# for fd, ke in cs.selector.get_map().items():
# logging.info(fd)
# print(ke)
# print()
总结:
使用IO多路复用 + (select、epoll)并不一定比多线程+ 同步阻塞性能好,其最大的优势是可以处理更多的连接。多线程+同步阻塞IO模式,开辟太多的线程,线程开辟、销毁开销还是较大,倒是可以使用线程池;线程多,线程自己使用的内存也很可观,多线程切换时,要保护现场和恢复现场,线程过多,切换回占用大量的时间 。
连接较少,多线程+同步阻塞IO模式比较合适,效率也不低。如果连接非常多,对服务端来说,IO并发还是比较高的,这时候开辟很多线程其实也不是很划算,此时IO多路复用或许是更好的选择。

- 同步阻塞 IO、同步非阻塞 IO、多路复用IO 、 异步 IO
- 【转】IO多路复用,同步异步,阻塞和非阻塞
- 同步和异步 阻塞和非阻塞 IO多路复用和select总结
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO
- 并发式IO的解决方案---非阻塞式、多路复用和异步通知(异步IO)
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO
- 多路复用及同步、异步和阻塞、非阻塞
- nginx的io复用、阻塞非阻塞、同步异步、apache与nginx的区别
- IO复用\阻塞IO\非阻塞IO\同步IO\异步IO .
- linux设备驱动程序中的阻塞、IO多路复用与异步通知机制
- IO复用模型同步,异步,阻塞,非阻塞及实例详解
- 阻塞IO 非阻塞IO IO多路复用 同步IO 异步IO
- IO复用(模型/阻塞/同步/异步)
- 【学习笔记】io多路复用中的poll, 以及异步io。
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO
- IO模型(阻塞、非阻塞、多路复用与异步)
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO
- [翻译]各个类型的IO - 阻塞, 非阻塞,多路复用和异步
- 聊聊IO多路复用之select、poll、epoll详解
- IO多路复用select,poll,epoll的区别