python下的ORM和SQLALchemy框架
 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
1. ORM
ORM,对象关系映射,对象和关系的映射,使用面向对象的方式来操作数据库。
关系模型和python对象之间的映射
table => class , 表映射为类
row => object ,行映射为实例
column => property ,字段映射为属性
2. SQLALchemy
SQLALchemy是一个ORM框架,SQLALchemy内部使用了连接池。安装: $ pip install sqlalchemy
**官方文档:**http://docs.sqlalchemy.org/en/latest
查看版本:
import sqlalchemy print(sqlalchemy.__version__)
2.1 创建连接
数据库连接的事情,交给引擎。
import sqlalchemy
# https://docs.sqlalchemy.org/en/13/orm/tutorial.html,如何使用sqlalchemy
from sqlalchemy import create_engine
print(sqlalchemy.__version__)
IP = '127.0.0.1'
USERNAME = 'root'
PASSWORD = 'root'
DB_NAME = 'test'
PORT = 3306
# mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
# https://docs.sqlalchemy.org/en/13/dialects/mysql.html#module-sqlalchemy.dialects.mysql.pymysql
conn = "mysql+pymysql://{}:{}@{}:{}/{}".format(USERNAME, PASSWORD, IP, PORT, DB_NAME)
# pymysql是驱动
engine = create_engine(conn, echo=True)
# echo=True 引擎是否打印执行的语句
print(engine)
# Engine(mysql+pymysql://root:***@127.0.0.1:3306/test)
# lazy connecting: 懒连接,创建引擎不会马上连接数据库,直到让数据库执行任务时才连接
2.2 Declare a Mapping创建映射
2.2.1 创建基类
from sqlalchemy.ext.declarative import declarative_base # 创建基类,便于实体类继承。SQLALchemy大量使用了元编程 Base = declartive_base()
2.2.2 创建实体类
from sqlalchemy import Column, Integer, String
class Student(Base):
__tablename__ = 'students'
# 字段名和属性名一致时,字段名可以省略不写
id = Column(Integer, primary_key=True) # 定义字段类型和属性
name = Column(String(40), nullable=False)
age = Column(Integer, nullable=False)
# age = Column('age', Integer, nullable=False)
def __repr__(self):
# return "<{} id={}, name={}, age={}>".format(__class__.__name__, self.id, self.name, self.age)
# 推荐使用C风格的写法
return "<id='%s', name='%s', age='%s'>" % (self.id, self.name, self.age)
print(Student.__dict__)
print(repr(Student.__table__)
实例化:
student = Student(name='James', age=35) print(student.name, student.age, student.id)
创建表:
可以使用SQLALchemy来创建表、删除表
# 删除继承自Base的所有表 Base.metadata.drop_all(engine) # 创建继承自Base的所有表 Base.metadata.create_all(engine)
注意:生产环境很少这样创建表,都是系统上线的时候由脚本生成。生产环境很少删除表,宁可废弃都不删除。
创建会话session:
在一个会话中操作数据库,会话建立在连接上,连接被引擎管理。当第一次使用数据库时,从引擎维护的连接池中获取一个连接使用。
from sqlalchemy.orm import sessionmaker # 创建session Session = sessionmaker(bind=engine) # 工厂方法返回类 session = Session() # 实例化 # 依然在第一次使用时连接数据库
session对象线程不安全,所以不同线程应该使用不同的session对象。
CRUD操作:
增
add():增加一个对象
add_all: 可以增加多个对象,元素是可迭代对象
import sqlalchemy
# https://docs.sqlalchemy.org/en/13/orm/tutorial.html,如何使用sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
print(sqlalchemy.__version__)
IP = '127.0.0.1'
USERNAME = 'root'
PASSWORD = 'root'
DB_NAME = 'test'
PORT = 3306
# mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
# https://docs.sqlalchemy.org/en/13/dialects/mysql.html#module-sqlalchemy.dialects.mysql.pymysql
conn = "mysql+pymysql://{}:{}@{}:{}/{}".format(USERNAME, PASSWORD, IP, PORT, DB_NAME)
# pymysql是驱动
engine = create_engine(conn, echo=True)
# echo=True 引擎是否打印执行的语句
print(engine)
# Engine(mysql+pymysql://root:***@127.0.0.1:3306/test)
# lazy connecting: 懒连接,创建引擎不会马上连接数据库,直到让数据库执行任务时才连接
Base = declarative_base() # 基类
class Student(Base):
__tablename__ = 'students'
# 字段名和属性名一致时,字段名可以省略不写
id = Column(Integer, primary_key=True) # 定义字段类型和属性
name = Column(String(40), nullable=False)
age = Column(Integer, nullable=False)
# age = Column('age', Integer, nullable=False)
def __repr__(self):
# return "<{} id={}, name={}, age={}>".format(__class__.__name__, self.id, self.name, self.age)
# 推荐使用C风格的写法
return "<id='%s', name='%s', age='%s'>" % (self.id, self.name, self.age)
print(Student.__dict__)
# print(Student.__table__) # 没有出自己想要的结果(默认调用str方法),可以调用一下repr方法
print(repr(Student.__table__))
Base.metadata.create_all(engine) # 创建继承自Base的所有表
# Base.metadata.drop_all(engine)
student = Student(name='James', age=35)
print(student.name, student.age, student.id)session = sessionmaker(bind=engine)() # 线程不安全,不适用多线程
student = Student(id=1, name='James', age=28)
session.add(student)
session.commit()
try:
student.name = 'Klay'
session.add_all([
Student(id=2, name='Curry', age=31),
Student(id=3, name='KD', age=32),
Student(id=4, name='Green', age=29)
])
session.commit()
print('~~~~~~~~~~~~~~~')
except Exception as e:
session.rollback()
print(e)
print('+++++++++++++++++')
简单查询:
students = session.query(Student)
print(students) # 无内容,惰性的
for s in students:
print(s)
print('-----------------')
"""\
<id='1', name='Klay', age='28'>
<id='2', name='Curry', age='31'>
<id='3', name='KD', age='32'>
<id='4', name='Green', age='29'>
"""
student = session.query(Student).get(2) # 通过主键查询
print(student)
# <id='2', name='Curry', age='31'>
query方法将实体类传入,返回类的对象(可迭代对象),这时候并不查询,迭代它就执行SQL来查询数据库,封装数据到指定的类的实例。get方法使用主键查询,返回一条传入类的一个实例。
改:
student = session.query(Student).get(3) # 必须先查出来,然后修改,最后在提交 print(student) # <id='3', name='KD', age='32'> student.name = 'Kevin' student.age = 32 print(student) # <id='3', name='Kevin', age='32'> session.add(student) session.commit()
状态 ***
每一个实体,都有一个状态属性_sa_instance_state,其类型是sqlalchemy.orm.state.InstanceState,可以使用sqlalchemy.inspect(entity)函数查看状态。常见的状态值有transient、peding、persistent、deleted、detached。
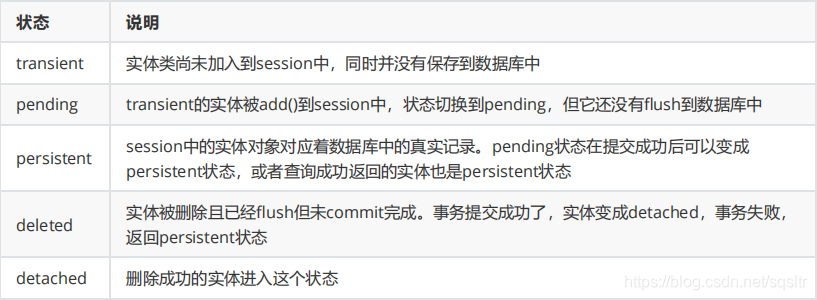 新建一个实体,状态就是transient临时的,一旦add()后从transient变成pending状态。成功提交后从pending变成persistent状态,成功查询返回的实体对象也是persistent状态,persistent状态的实体,修改后还是persistent状态,persistent状态的实体,删除后,flush后没有commit,就变成deleted状态,成功提交,就变成detached状态,提交失败,还原到persistent状态。flush方法,主要是把改变应用到数据库中去。
新建一个实体,状态就是transient临时的,一旦add()后从transient变成pending状态。成功提交后从pending变成persistent状态,成功查询返回的实体对象也是persistent状态,persistent状态的实体,修改后还是persistent状态,persistent状态的实体,删除后,flush后没有commit,就变成deleted状态,成功提交,就变成detached状态,提交失败,还原到persistent状态。flush方法,主要是把改变应用到数据库中去。
import sqlalchemy
# https://docs.sqlalchemy.org/en/13/orm/tutorial.html,如何使用sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm.state import InstanceState
print(sqlalchemy.__version__)
IP = '127.0.0.1'
USERNAME = 'root'
PASSWORD = 'root'
DB_NAME = 'test'
PORT = 3306
# mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
# https://docs.sqlalchemy.org/en/13/dialects/mysql.html#module-sqlalchemy.dialects.mysql.pymysql
conn = "mysql+pymysql://{}:{}@{}:{}/{}".format(USERNAME, PASSWORD, IP, PORT, DB_NAME)
# pymysql是驱动
engine = create_engine(conn, echo=True)
# echo=True 引擎是否打印执行的语句
print(engine)
# Engine(mysql+pymysql://root:***@127.0.0.1:3306/test)
# lazy connecting: 懒连接,创建引擎不会马上连接数据库,直到让数据库执行任务时才连接
Base = declarative_base() # 基类
class Student(Base):
__tablename__ = 'students'
# 字段名和属性名一致时,字段名可以省略不写
id = Column(Integer, primary_key=True) # 定义字段类型和属性
name = Column(String(40), nullable=False)
age = Column(Integer, nullable=False)
# age = Column('age', Integer, nullable=False)
def __repr__(self):
# return "<{} id={}, name={}, age={}>".format(__class__.__name__, self.id, self.name, self.age)
# 推荐使用C风格的写法
return "<id='%s', name='%s', age='%s'>" % (self.id, self.name, self.age)
session = sessionmaker(bind=engine)()
def get_state(instance, i):
state: InstanceState = sqlalchemy.inspect(instance)
output = "{} :{} {} \n"\
"attached={}, transient={}, pending={}\n"\
"persistent={}, deleted={}, detached={}\n".format(i, state.key, state.session_id,
state._attached, state.transient, state.pending,
state.persistent, state.deleted, state.detached)
print(output, end="~~~~~~~~~~~~~~~\n")
student = session.query(Student).get(2)
get_state(student, 1) # persistent
try:
student = Student(id=5, name='AD', age=28)
get_state(student, 2) # transient
student = Student(id=6, name='Durant', age=32)
get_state(student, 3) # transient
session.add(student)
get_state(student, 4) # pending
session.commit()
get_state(student, 5) # persistent
except Exception as e:
session.rollback()
print(e, '~~~~~~~~~~~~')
student = session.query(Student).get(6)
get_state(student, 6) # persistent
try:
session.delete(student)
get_state(student, 7) # persistent(未flush)
session.flush()
get_state(student, 8) # deleted
session.commit()
get_state(student, 9) # detached(分离)
except Exception as e:
session.rollback()
print('++++++++++++++++')
print(e)
复杂查询
from sqlalchemy import create_engine, Column, String, Integer, Enum, Date, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship # , scoped_session
# from sqlalchemy import and_, or_, not_
from sqlalchemy import func
import enum
Base = declarative_base() # 基类
IP = '127.0.0.1'
USERNAME = 'root'
PASSWORD = 'root'
DB_NAME = 'test'
PORT = 3306
# mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
# https://docs.sqlalchemy.org/en/13/dialects/mysql.html#module-sqlalchemy.dialects.mysql.pymysql
conn = "mysql+pymysql://{}:{}@{}:{}/{}".format(USERNAME, PASSWORD, IP, PORT, DB_NAME)
# pymysql 是驱动
engine = create_engine(conn, echo=True)
session = sessionmaker(bind=engine)()
class MyEnum(enum.Enum): # 枚举一般不用,建议直接写0,1
F = 'F'
M = 'M'
class Employee(Base):
__tablename__ = 'employees'
emp_no = Column(Integer, primary_key=True)
birth_date = Column(Date, nullable=False)
first_name = Column(String(14), nullable=False)
last_name = Column(String(16), nullable=False)
gender = Column(Enum(MyEnum), nullable=False)
hire_date = Column(Date, nullable=False)
departments = relationship('DeptEmp')
def __repr__(self):
return "<{} emp_no={}, name={}, gender={}, dept={}>".format(__class__.__name__, self.emp_no,
"{} {}".format(self.first_name, self.last_name),
self.gender.value, self.departments)
class Department(Base):
__tablename__ = 'departments'
dept_no = Column(Integer, primary_key=True)
dept_name = Column(String(40), unique=True)
def __repr__(self):
return "<{} dept_no={}, dept_name={}>".format(__class__.__name__, self.dept_no, self.dept_name)
class DeptEmp(Base):
__tablename__ = 'dept_emp'
emp_no = Column(Integer, ForeignKey('employees.emp_no', ondelete='CASCADE'), primary_key=True)
dept_no = Column(Integer, ForeignKey('departments.dept_no', ondelete='CASCADE'), primary_key=True)
from_date = Column(Date, nullable=False)
to_date = Column(Date, nullable=False)
def __repr__(self):
return "<{} emp_no={}, dept_no={}>".format(__class__.__name__, self.emp_no, self.dept_no)
def show(ems):
for x in ems:
print(x)
print('\n\n')
# eps = session.query(Employee).filter(Employee.emp_no > 10015) # filter相当于where
# # query可以理解为select * from
# show(eps)
# and or not
# eps = session.query(Employee).filter(Employee.emp_no > 10015, Employee.emp_no < 10019)
# show(eps)
# eps = session.query(Employee).filter(Employee.emp_no > 10015).filter(Employee.emp_no < 10019)
# show(eps)
# eps = session.query(Employee).filter((Employee.emp_no > 10015) & (Employee.emp_no < 10019))
# show(eps)
# eps = session.query(Employee).filter(and_(Employee.emp_no > 10015, Employee.emp_no < 10019))
# show(eps)
#
# es = session.query(Employee).filter(or_(Employee.emp_no == 10015, Employee.emp_no == 10018))
# show(es)
#
# # es = session.query(Employee).filter((Employee.emp_no == 10015) | (Employee.emp_no == 10018))
# # show(es)
#
# ss = session.query(Employee).filter(not_(Employee.emp_no < 10019))
# show(ss)
# ss = session.query(Employee).filter(~(Employee.emp_no < 10019))
# show(ss)
# # in, 注意调用的是in_函数
# emp_list = (10010, 10019, 10021)
#
# esm = session.query(Employee).filter(Employee.emp_no.in_(emp_list))
# show(esm)
#
# # # not in
# # ems = session.query(Employee).filter(~(Employee.emp_no.in_(emp_list)))
# # show(ems)
#
# # like
# ms = session.query(Employee).filter(Employee.first_name.like('P%'))
# show(ms)
#
#
# # # not like,ilike默认不区分大小写
# # mse = session.query(Employee).filter(Employee.last_name.notlike('M%'))
# # show(mse)
#
# sm = session.query(Employee).filter(Employee.emp_no > 10017).order_by(Employee.emp_no)
# show(sm)
#
# sme = session.query(Employee).filter(Employee.emp_no > 10017).\
# order_by(Employee.gender).order_by(Employee.emp_no.desc())
# # 注意Employees.gender不是按照升序排列的,而是类变量的定义顺序,暂时还是有问题,明天继续探索?
# show(sme)
# 分页
sem = session.query(Employee).filter(Employee.emp_no > 10015).limit(2).offset(2)
show(sem)
# 消费者方法,消费者方法调用后,Query对象就转换成了一个容器
ps = session.query(Employee)
# print(ps.count()) # 聚合函数count(*)的查询,用了子查询,效率不高
print(len(list(ps)))
# for i in ps:
# print(i)
print(ps.all()) # 结果是列表,列表中是21个对象,查不到返回空列表
print(ps.first()) # 返回行首,查不到返回None
# print(ps.one()) # 有且只能有一行,如果查询结果是多行则抛异常
# 删除 delete
# session.query(Employee).filter(Employee.emp_no > 10019).delete()
# session.commit() # 提交后就真的删除了
# # 聚合、分组
# query = session.query(func.count(Employee.emp_no))
# print(query.all()) # [(21,)],结果是列表
# print(query.first()) # (21,),结果是元组
# print(query.one()) # (21,),结果是元组
# print(query.scalar()) # 21,取one的第一个元素
query = session.query(Employee.gender, func.count(Employee.emp_no)).group_by(Employee.gender).all()
print(query)
# [(<MyEnum.M: 'M'>, 13), (<MyEnum.F: 'F'>, 8)]
for g, y in query:
print(g)
print(g.value, y)
print("~~~~~~~~~~~~~~~")
# 关联查询
# 查询10010员工的所在部门编号及员工信息
result = session.query(Employee, DeptEmp).filter(Employee.emp_no == DeptEmp.emp_no, Employee.emp_no == 10010).all()
# 隐式连接等价于
"""\
SELECT *
from employees, dept_emp
where employees.emp_no = dept_emp.emp_no and employees.emp_no = 10018;
"""
show(result) # 结果是两个对象
# 使用join
# results = session.query(Employee).join(DeptEmp).filter(Employee.emp_no == 10010).all()
# show(results)
# results = session.query(Employee).join(DeptEmp, Employee.emp_no == DeptEmp.emp_no).\
# filter(Employee.emp_no == 10010).all()
#
# show(results)
results = session.query(Employee).join(DeptEmp, (Employee.emp_no == DeptEmp.emp_no) & (Employee.emp_no == 10010))
show(results.all()) # 注意返回的结果是一个对象
# <Employee emp_no=10010, name=Duangkaew Piveteau, gender=F, dept=[<DeptEmp emp_no=10010, dept_no=d004>,
# <DeptEmp emp_no=10010, dept_no=d006>]>
for j in results:
print(j)
print(j.emp_no) # 10010
print(j.departments)
# [<DeptEmp emp_no=10010, dept_no=d004>, <DeptEmp emp_no=10010, dept_no=d006>]
总结:
在开发中,一般都会采用ORM框架,这样就可以使用对象操作表了。定义表映射的类,使用Column的描述器定义类属性,使用ForeignKey来定义外键约束。如果在一个对象中,想查看其它表对应的对象的内容,就要使用relationship来定义关系。

- Python的Django框架中使用SQLAlchemy操作数据库的教程
- Python的SQLAlchemy框架使用入门
- Flask框架(SQLAlchemy(python3版本)中修改数据的方法和删除数据 的方法)
- python-flask框架学习笔记(五)--一(多)对多关系映射在SQLAlchemy中的实现
- 【SQLAlchemy】python最常用ORM (二)
- flask框架:Python 3.5下使用 flask_SqlAlchemy和mysql
- python与数据库sqlalchemy框架简述
- Python程序和Flask框架中使用SQLAlchemy的教程
- Python-ORM-SQLALchemy
- Flask框架(SQLAlchemy(python3版本)中查询数据的方法,以及定义显示信息 )
- Python(SQLAlchemy-ORM)模块之mysql操作
- 我的第一个python web开发框架(32)——定制ORM(八)
- 【SQLAlchemy】python最常用ORM (三)
- 我的第一个python web开发框架(27)——定制ORM(三)
- python3开发进阶-Django框架中的ORM的常用(增,删,改,查)操作
- werkzeug实现简单Python web框架(4):添加orm支持
- 我的第一个python web开发框架(31)——定制ORM(七)
- Python ORM :SQLAlchemy基础使用
- python的sqlalchemy框架
- 我的第一个python web开发框架(30)——定制ORM(六)