python分布式爬虫scrapy_redis
2019-06-05 18:16
190 查看
安装 scrapy_redis
pip install scrapy-redis
Scrapy-Redis分布式策略
- Master端(核心服务器) :我使用的虚拟机系统为linux,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
- Slaver端(爬虫程序执行端) :我使用的win10,负责执行爬虫程序,运行过程中提交新的Request给Master
分布式爬虫的运作过程
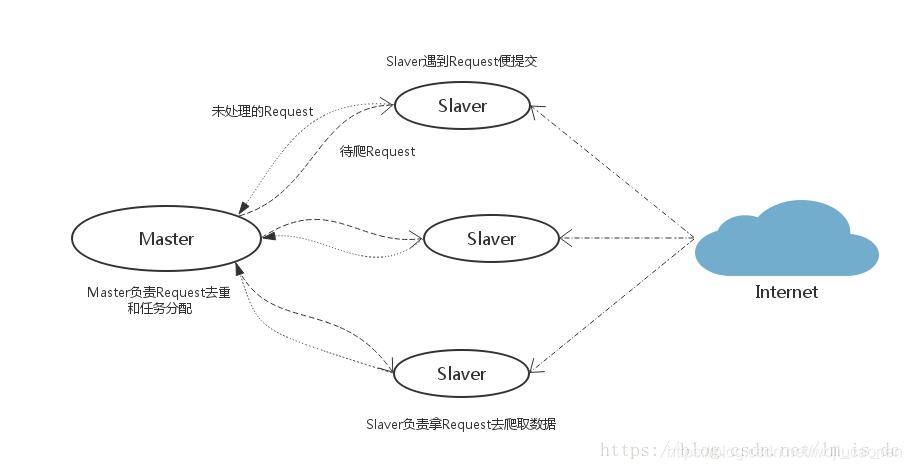
- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
实例-使用分布式爬虫爬取豆瓣250
此处省略了虚拟机redis数据库的配置。
先从github上拿到scrapy-redis的示例,然后将里面的example-project目录移到指定的地址:
https://github.com/rmax/scrapy-redis
scrapy-redis 源码中有自带一个example-project项目,这个项目包含3个spider,分别是dmoz, myspider_redis,mycrawler_redis,
此处使用的是mycrawler_redis
在mycrawler_redis 中不再有start_urls,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
下面是代码
1. 修改items
from scrapy.item import Item, Field from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose, TakeFirst, Join class ExampleItem(Item): mingzi = Field() daoyan = Field() riqi = Field() jianjie = Field() url = Field() class ExampleLoader(ItemLoader): default_item_class = ExampleItem default_input_processor = MapCompose(lambda s: s.strip()) default_output_processor = TakeFirst() description_out = Join()
2. 修改pipelines
class ExamplePipeline(object):
#把数据保存在本地txt中
def __init__(self):
self.file = open("douban.txt", "w", encoding="utf-8")
def process_item(self, item, spider):
self.file.write(str(item) + "\r\n")
self.file.flush()
print(item)
return item
def __del__(self):
self.file.close()
3. 修改setting
REDIS_HOST = 'x.x.x.x' REDIS_PORT = 6379 REDIS_URL = "redis://:123456@x.x.x.x:6379" #REDIS_URL = "redis://:密码@x.x.x.x:6379"
4.写spider
Mydouban.py
from bs4 import BeautifulSoup
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisMixin
from scrapy.spiders import CrawlSpider
from scrapy_redis.spiders import RedisCrawlSpider
from ..items import ExampleItem
import re
import scrapy
class MyCrawler(RedisCrawlSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'mydouban_redis'
redis_key = 'douban:start_urls'
rules = (
# follow all links
Rule(LinkExtractor(allow=(r'\?start=\d+&filter=')), follow=True),
Rule(LinkExtractor(allow=(r'movie\.douban\.com/subject/\d+/')), callback='parse_page', follow=False),
)
def set_crawler(self, crawer):
CrawlSpider.set_crawler(self, crawer) # 设置默认爬去
RedisMixin.setup_redis(self) # url由redis
#def __init__(self, *args, **kwargs):
# # Dynamically define the allowed domains list.
# domain = kwargs.pop('domain', '')
# self.allowed_domains = filter(None, domain.split(','))
# super(MyCrawler, self).__init__(*args, **kwargs)
def getinf(self,response):
mingzi =response.xpath('//*[@id="content"]/h1/span[1]/text()').extract()
daoyan =response.xpath('//*[@id="info"]/span[1]/span[2]/a/text()').extract()
riqi =response.xpath('//*[@id="info"]/span[10]/text()').extract()
jianjie =response.xpath('//*[@id="link-report"]/span[1]/span/text()').extract()
jianjie =response.xpath('//*[@id="link-report"]/span[1]/text()').extract()
url =response.url
return mingzi,daoyan,riqi,jianjie,url
def parse_page(self, response):
result=self.getinf(response)
item=ExampleItem()
item['url']=result[4]
item['mingzi']=result[0]
item['daoyan']=result[1]
item['riqi']=result[2]
item['jianjie']=result[3]
yield item
运行项目
-
通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider mydouban_redis.py -
在Master端的redis-cli输入push指令,参考格式:
*$redis > lpush mycrawler:start_urls https://movie.douban.com/top250 -
爬虫获取url,开始执行。
此处使用 scrapy runspider mydouban_redis.py ,执行失败,提示找不到mydouban_redis.py,不明原因,有大佬知道原因的望告知。
此处我使用的是 scrapy crawl 我的爬虫name 才执行成功。

相关文章推荐
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
- 基于Python,scrapy,redis的分布式爬虫实现框架
- 基于Python+scrapy+redis的分布式爬虫实现框架
- 基于Python使用scrapy-redis框架实现分布式爬虫 注
- python scrapy-redis分布式爬虫 学习笔记
- Python自动化开发学习-分布式爬虫(scrapy-redis)
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
- python 全栈开发,Day140(RabbitMQ,基于scrapy-redis实现分布式爬虫)
- 基于Python,scrapy,redis的分布式爬虫实现框架
- Python之Scrapy框架Redis实现分布式爬虫详解
- 分布式爬虫scrapy-redis
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
- scrapy-redis 更改队列和分布式爬虫
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(2)
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第5章 scrapy爬取知名问答网站(2)
- python爬虫框架之Scrapy分布式的使用