python scrapy-redis分布式爬虫 学习笔记
2019-02-26 19:16
267 查看
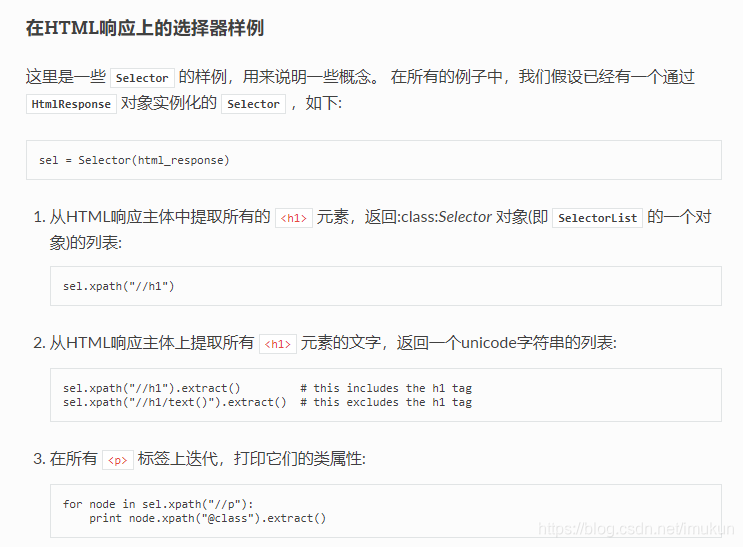
1、xpath的exract()方法
xpath()方法返回的是
SelectorList实例,是一个选择器列表,必须使用extract()方法才能提取最终的数据,
extract_first() 用来提取第一个匹配到的元素,如果没有匹配的元素,则返回
None
切片,从一个对象中得到list
xpath(query)
对列表中的每个元素调用
.xpath()方法,返回结果为另一个单一化的
SelectorList。
query和
Selector.xpath()中的参数相同。
extract()
对列表中的各个元素调用
.extract()方法,返回结果为单一化的unicode字符串列表。

相关文章推荐
- Python自动化开发学习-分布式爬虫(scrapy-redis)
- python爬虫学习笔记六:Scrapy爬虫的使用步骤
- Python爬虫框架Scrapy 学习笔记 1 ----- 环境搭建
- Python之Scrapy框架Redis实现分布式爬虫详解
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第1章 课程介绍
- Python爬虫框架Scrapy 学习笔记 4 ------- 第二个Scrapy项目
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(2)
- 基于Python,scrapy,redis的分布式爬虫实现框架
- Python的学习笔记DAY7---关于爬虫(2)之Scrapy初探
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
- 基于Python,scrapy,redis的分布式爬虫实现框架
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(1)
- python 爬虫 学习笔记(一)Scrapy框架入门
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第2章 windows下搭建开发环境
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第5章 scrapy爬取知名问答网站(2)
- Python爬虫框架Scrapy 学习笔记 7------- scrapy.Item源码剖析
- Python的Scrapy爬虫框架简单学习笔记
- 学习笔记Python爬虫之Scrapy《三》(css、xpath)