第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
2017-08-04 17:53
555 查看
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
[b]编写spiders爬虫文件循环抓取内容[/b]
Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数,
参数:
url='url'
callback=页面处理函数
使用时需要yield Request()
parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接
Request()函数在返回url时,同时可以通过meta属性返回一个自定义字典给回调函数
Scrapy内置图片下载器使用
[b]Scrapy给我们内置了一个图片下载器在crapy.pipelines.images.ImagesPipeline,专门用于将爬虫抓取到图片url后将图片下载到本地[/b]
[b]第一步、[/b][b]爬虫抓取图片URL地址后,填充到 items.py文件的容器函数[/b]
[b] 爬虫文件[/b]
第二步、设置 [b][b]items.py 文件的容器函数,接收爬虫获取到的数据填充[/b][/b]
第三步、在pipelines.py使用crapy内置的图片下载器
1、首先引入内置图片下载器
2、自定义一个图片下载内,继承crapy内置的ImagesPipeline图片下载器类
3、使用ImagesPipeline类里的item_completed()方法获取到图片下载后的保存路径
4、在settings.py设置文件里,注册自定义图片下载器类,和设置图片保存路径
在settings.py设置文件里,注册自定义图片下载器类,和设置图片保存路径
IMAGES_URLS_FIELD 设置要下载图片的url地址,一般设置的items.py里接收的字段
IMAGES_STORE 设置图片保存路径
[b]编写spiders爬虫文件循环抓取内容[/b]
Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数,
参数:
url='url'
callback=页面处理函数
使用时需要yield Request()
parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request #导入url返回给下载器的方法
from urllib import parse #导入urllib库里的parse模块
class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com'] #起始域名
start_urls = ['http://blog.jobbole.com/all-posts/'] #起始url
def parse(self, response):
"""
获取列表页的文章url地址,交给下载器
"""
#获取当前页文章url
lb_url = response.xpath('//a[@class="archive-title"]/@href').extract() #获取文章列表url
for i in lb_url:
# print(parse.urljoin(response.url,i)) #urllib库里的parse模块的urljoin()方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接
yield Request(url=parse.urljoin(response.url, i), callback=self.parse_wzhang) #将循环到的文章url添加给下载器,下载后交给parse_wzhang回调函数
#获取下一页列表url,交给下载器,返回给parse函数循环
x_lb_url = response.xpath('//a[@class="next page-numbers"]/@href').extract() #获取下一页文章列表url
if x_lb_url:
yield Request(url=parse.urljoin(response.url, x_lb_url[0]), callback=self.parse) #获取到下一页url返回给下载器,回调给parse函数循环进行
def parse_wzhang(self,response):
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract() #获取文章标题
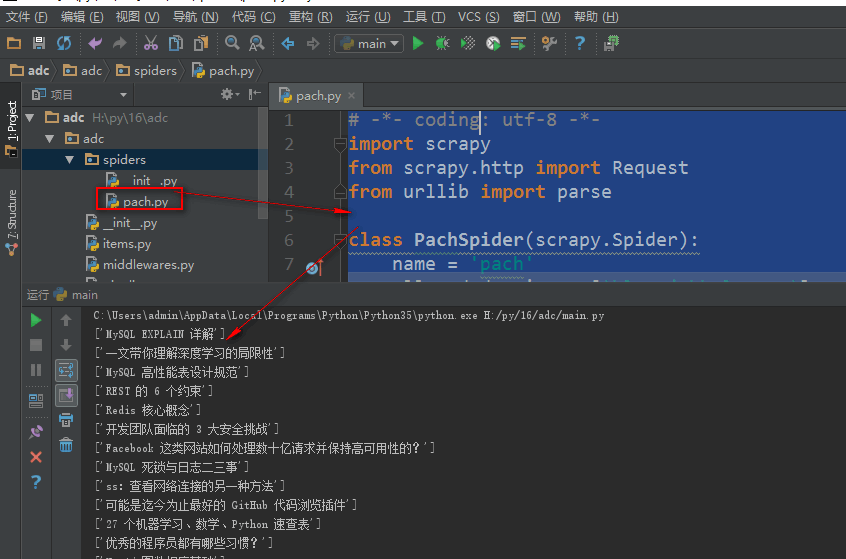
print(title)Request()函数在返回url时,同时可以通过meta属性返回一个自定义字典给回调函数
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request #导入url返回给下载器的方法
from urllib import parse #导入urllib库里的parse模块
from adc.items import AdcItem #导入items数据接收模块的接收类
class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com'] #起始域名
start_urls = ['http://blog.jobbole.com/all-posts/'] #起始url
def parse(self, response):
"""
获取列表页的文章url地址,交给下载器
"""
#获取当前页文章url
lb = response.css('div .post.floated-thumb') #获取文章列表区块,css选择器
# print(lb)
for i in lb:
lb_url = i.css('.archive-title ::attr(href)').extract_first('') #获取区块里文章url
# print(lb_url)
lb_img = i.css('.post-thumb img ::attr(src)').extract_first('') #获取区块里文章缩略图
# print(lb_img)
yield Request(url=parse.urljoin(response.url, lb_url), meta={'lb_img':parse.urljoin(response.url, lb_img)}, callback=self.parse_wzhang) #将循环到的文章url添加给下载器,下载后交给parse_wzhang回调函数
#获取下一页列表url,交给下载器,返回给parse函数循环
x_lb_url = response.css('.next.page-numbers ::attr(href)').extract_first('') #获取下一页文章列表url
if x_lb_url:
yield Request(url=parse.urljoin(response.url, x_lb_url), callback=self.parse) #获取到下一页url返回给下载器,回调给parse函数循环进行
def parse_wzhang(self,response):
title = response.css('.entry-header h1 ::text').extract() #获取文章标题
# print(title)
tp_img = response.meta.get('lb_img', '') #接收meta传过来的值,用get获取防止出错
# print(tp_img)
shjjsh = AdcItem() #实例化数据接收类
shjjsh['title'] = title #将数据传输给items接收模块的指定类
shjjsh['img'] = tp_img
yield shjjsh #将接收对象返回给pipelines.py处理模块Scrapy内置图片下载器使用
[b]Scrapy给我们内置了一个图片下载器在crapy.pipelines.images.ImagesPipeline,专门用于将爬虫抓取到图片url后将图片下载到本地[/b]
[b]第一步、[/b][b]爬虫抓取图片URL地址后,填充到 items.py文件的容器函数[/b]
[b] 爬虫文件[/b]
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request #导入url返回给下载器的方法
from urllib import parse #导入urllib库里的parse模块
from adc.items import AdcItem #导入items数据接收模块的接收类
class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com'] #起始域名
start_urls = ['http://blog.jobbole.com/all-posts/'] #起始url
def parse(self, response):
"""
获取列表页的文章url地址,交给下载器
"""
#获取当前页文章url
lb = response.css('div .post.floated-thumb') #获取文章列表区块,css选择器
# print(lb)
for i in lb:
lb_url = i.css('.archive-title ::attr(href)').extract_first('') #获取区块里文章url
# print(lb_url)
lb_img = i.css('.post-thumb img ::attr(src)').extract_first('') #获取区块里文章缩略图
# print(lb_img)
yield Request(url=parse.urljoin(response.url, lb_url), meta={'lb_img':parse.urljoin(response.url, lb_img)}, callback=self.parse_wzhang) #将循环到的文章url添加给下载器,下载后交给parse_wzhang回调函数
#获取下一页列表url,交给下载器,返回给parse函数循环
x_lb_url = response.css('.next.page-numbers ::attr(href)').extract_first('') #获取下一页文章列表url
if x_lb_url:
yield Request(url=parse.urljoin(response.url, x_lb_url), callback=self.parse) #获取到下一页url返回给下载器,回调给parse函数循环进行
def parse_wzhang(self,response):
title = response.css('.entry-header h1 ::text').extract() #获取文章标题
# print(title)
tp_img = response.meta.get('lb_img', '') #接收meta传过来的值,用get获取防止出错
# print(tp_img)
shjjsh = AdcItem() #实例化数据接收类
shjjsh['title'] = title #将数据传输给items接收模块的指定类
shjjsh['img'] = [tp_img]
yield shjjsh #将接收对象返回给pipelines.py处理模块第二步、设置 [b][b]items.py 文件的容器函数,接收爬虫获取到的数据填充[/b][/b]
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy #items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件 class AdcItem(scrapy.Item): #设置爬虫获取到的信息容器类 title = scrapy.Field() #接收爬虫获取到的title信息 img = scrapy.Field() #接收缩略图 img_tplj = scrapy.Field() #图片保存路径
第三步、在pipelines.py使用crapy内置的图片下载器
1、首先引入内置图片下载器
2、自定义一个图片下载内,继承crapy内置的ImagesPipeline图片下载器类
3、使用ImagesPipeline类里的item_completed()方法获取到图片下载后的保存路径
4、在settings.py设置文件里,注册自定义图片下载器类,和设置图片保存路径
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline #导入图片下载器模块 class AdcPipeline(object): #定义数据处理类,必须继承object def process_item(self, item, spider): #process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象 print('文章标题是:' + item['title'][0]) print('文章缩略图url是:' + item['img'][0]) print('文章缩略图保存路径是:' + item['img_tplj']) #接收图片下载器填充的,图片下载后的路径 return item class imgPipeline(ImagesPipeline): #自定义一个图片下载内,继承crapy内置的ImagesPipeline图片下载器类 def item_completed(self, results, item, info): #使用ImagesPipeline类里的item_completed()方法获取到图片下载后的保存路径 for ok, value in results: img_lj = value['path'] #接收图片保存路径 # print(ok) item['img_tplj'] = img_lj #将图片保存路径填充到items.py里的字段里 return item #将item给items.py 文件的容器函数 #注意:自定义图片下载器设置好后,需要在
在settings.py设置文件里,注册自定义图片下载器类,和设置图片保存路径
IMAGES_URLS_FIELD 设置要下载图片的url地址,一般设置的items.py里接收的字段
IMAGES_STORE 设置图片保存路径
# Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'adc.pipelines.AdcPipeline': 300, #注册adc.pipelines.AdcPipeline类,后面一个数字参数表示执行等级, 'adc.pipelines.imgPipeline': 1, #注册自定义图片下载器,数值越小,越优先执行 } IMAGES_URLS_FIELD = 'img' #设置要下载图片的url字段,就是图片在items.py里的字段里 lujin = os.path.abspath(os.path.dirname(__file__)) IMAGES_STORE = os.path.join(lujin, 'img') #设置图片保存路径

相关文章推荐
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
- 第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第2章 windows下搭建开发环境
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(2)
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
- python分布式爬虫打造搜索引擎--------scrapy实现
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装