目标检测算法之SSD
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xiaohu2022/article/details/79833786 </div> <link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-f57960eb32.css"> <div id="content_views" class="markdown_views"> <!-- flowchart 箭头图标 勿删 --> <svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <p><strong>码字不易,欢迎给个赞!</strong></p>
欢迎交流与转载,文章会同步发布在公众号:机器学习算法全栈工程师(Jeemy110)
目录
前言
目标检测近年来已经取得了很重要的进展,主流的算法主要分为两个类型:(1)two-stage方法,如R-CNN系算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage方法的优势是准确度高;(2)one-stage方法,如Yolo和SSD,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡(参见Focal Loss),导致模型准确度稍低。不同算法的性能如图1所示,可以看到两类方法在准确度和速度上的差异。
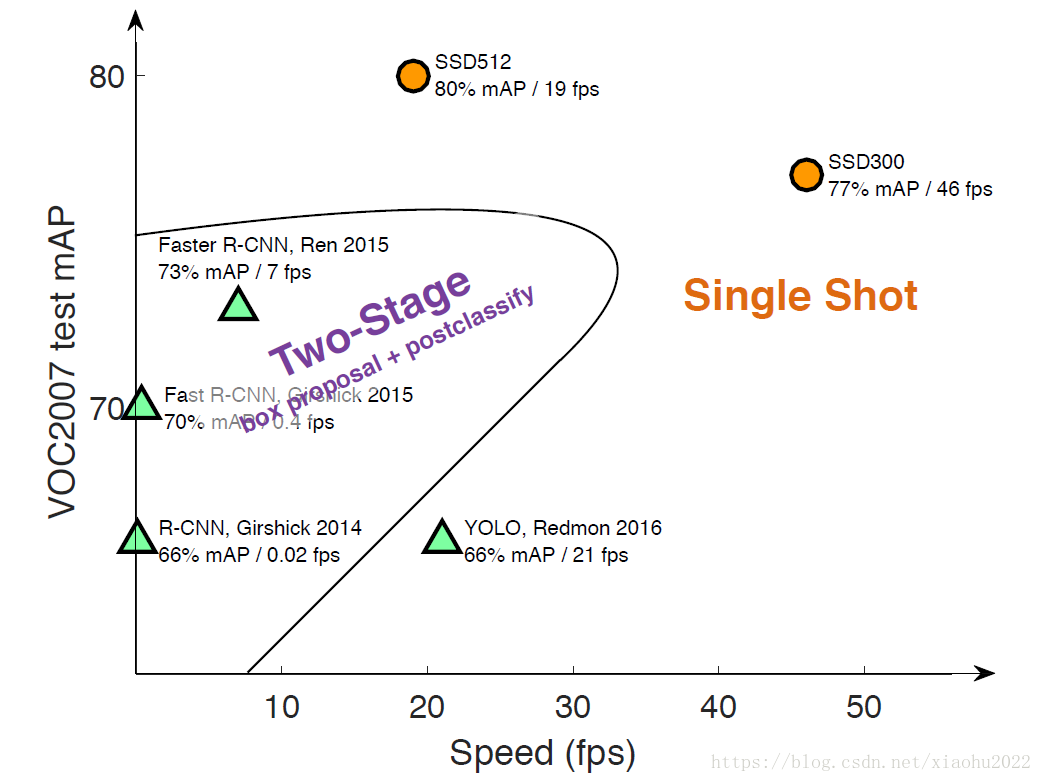
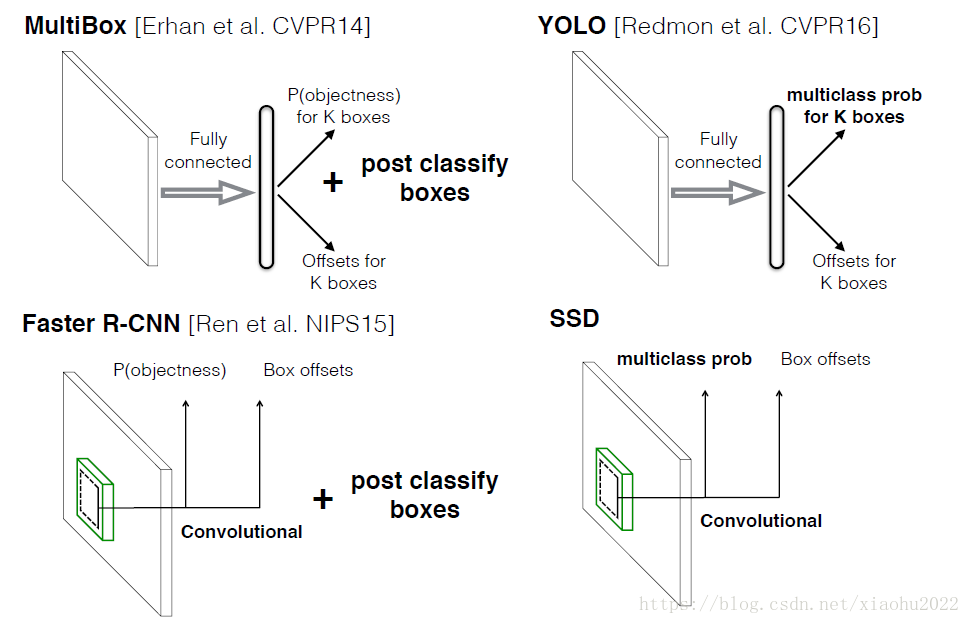
本文讲解的是SSD算法,其英文全名是Single Shot MultiBox Detector,名字取得不错,Single shot指明了SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测。在上一篇文章中我们已经讲了Yolo算法,从图1也可以看到,SSD算法在准确度和速度(除了SSD512)上都比Yolo要好很多。图2给出了不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。下面我们详细讲解SDD算法的原理,并最后给出如何用TensorFlow实现SSD算法。
设计理念
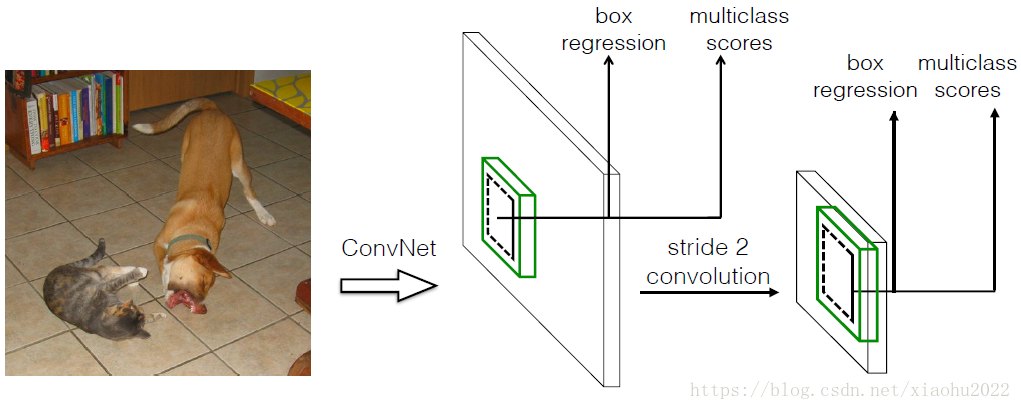
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,其基本架构如图3所示。下面将SSD核心设计理念总结为以下三点:
(1)采用多尺度特征图用于检测
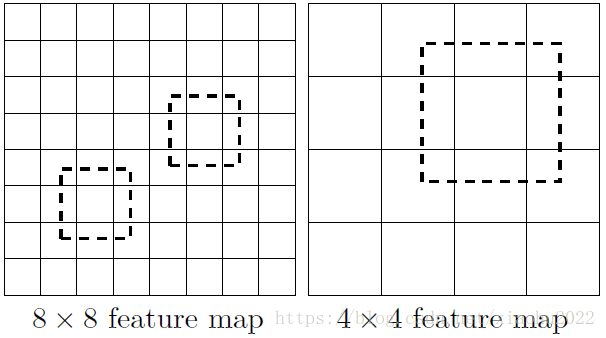
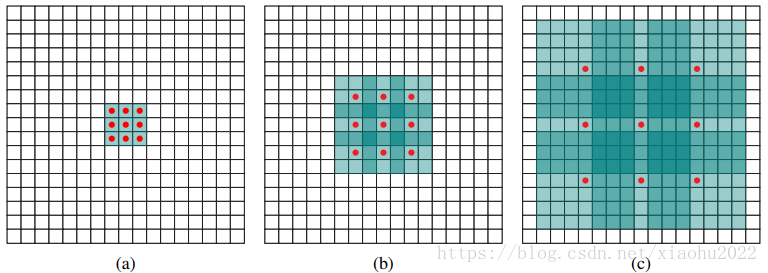
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如图3所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如图4所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。
(2)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m×n×pm×n×p这样比较小的卷积核得到检测值。
(3)设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图5所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。
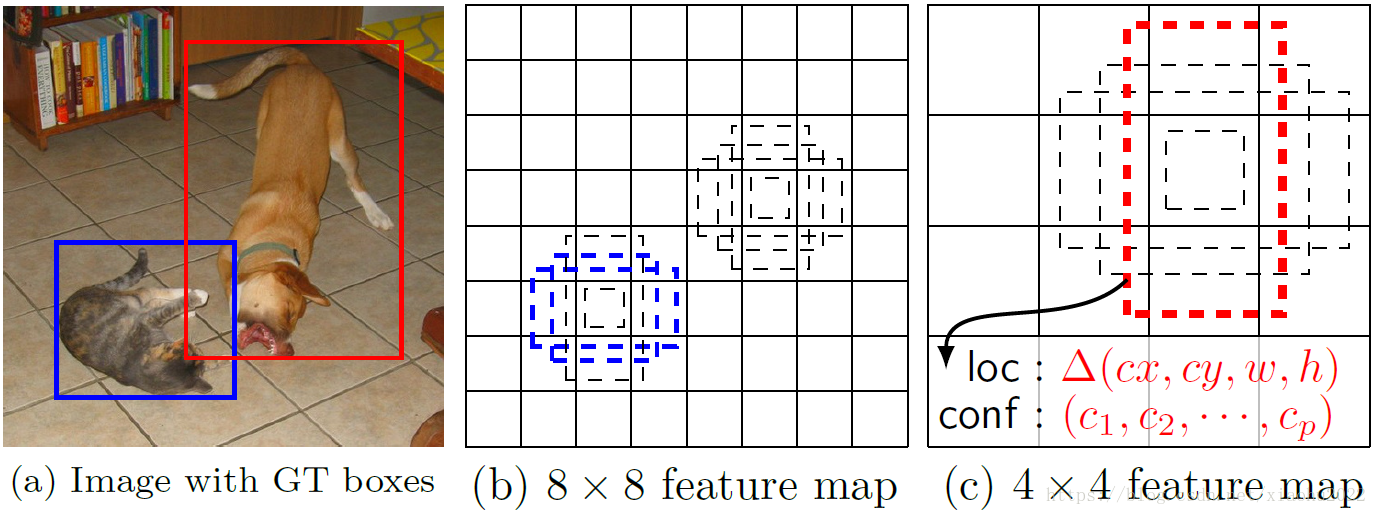
SSD的检测值也与Yolo不太一样。对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有cc
综上所述,对于一个大小m×nm×n个卷积核完成这个特征图的检测过程。
网络结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图6所示。上面是SSD模型,下面是Yolo模型,可以明显看到SSD利用了多尺度的特征图做检测。模型的输入图片大小是300×300300×300,其与前者网络结构没有差别,只是最后新增一个卷积层,本文不再讨论)。
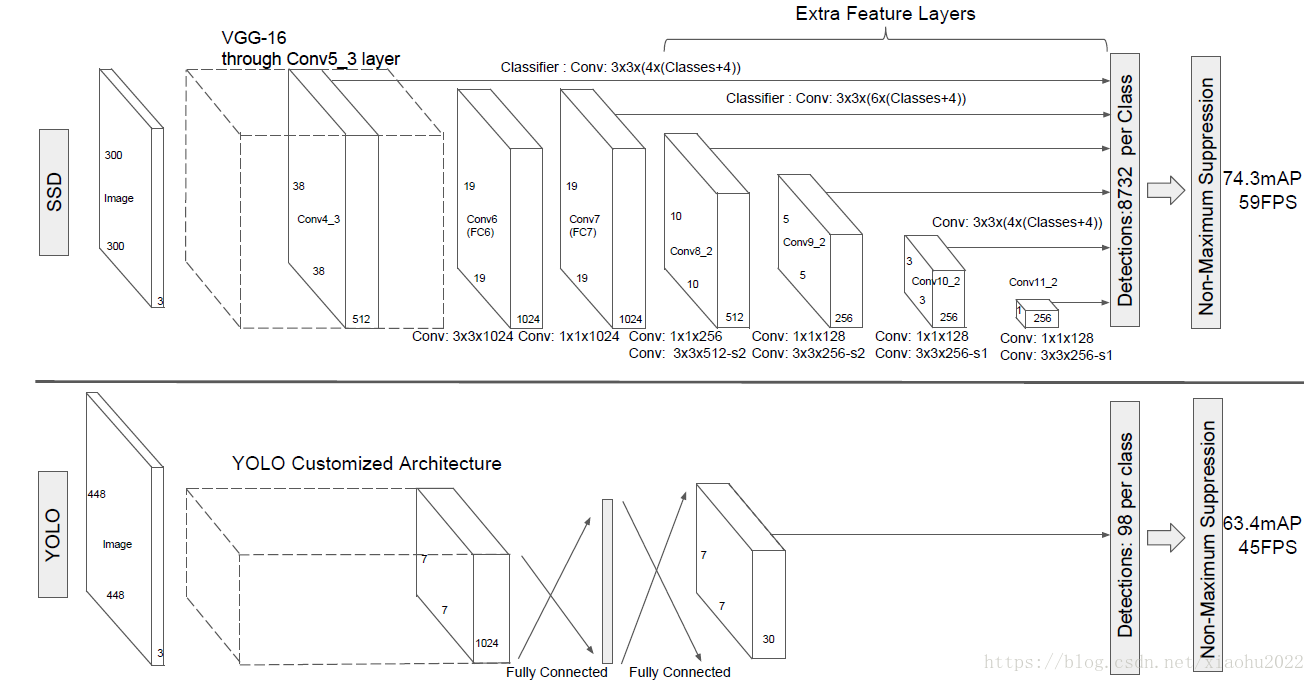
采用VGG16做基础模型,首先VGG16是在ILSVRC CLS-LOC数据集预训练。然后借鉴了DeepLab-LargeFOV,分别将VGG16的全连接层fc6和fc7转换成3×33×3大小但dilation rate=6的扩展卷积。
然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做finetuing。
其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是38×3838×38,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层(参见ParseNet),以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma,使用TF可以这样简单实现:
# l2norm (not bacth norm, spatial normalization)
def l2norm(x, scale, trainable=True, scope="L2Normalization"):
n_channels = x.get_shape().as_list()[-1]
1ddc4
l2_norm = tf.nn.l2_normalize(x, [3], epsilon=1e-12)
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)为特征图的大小。
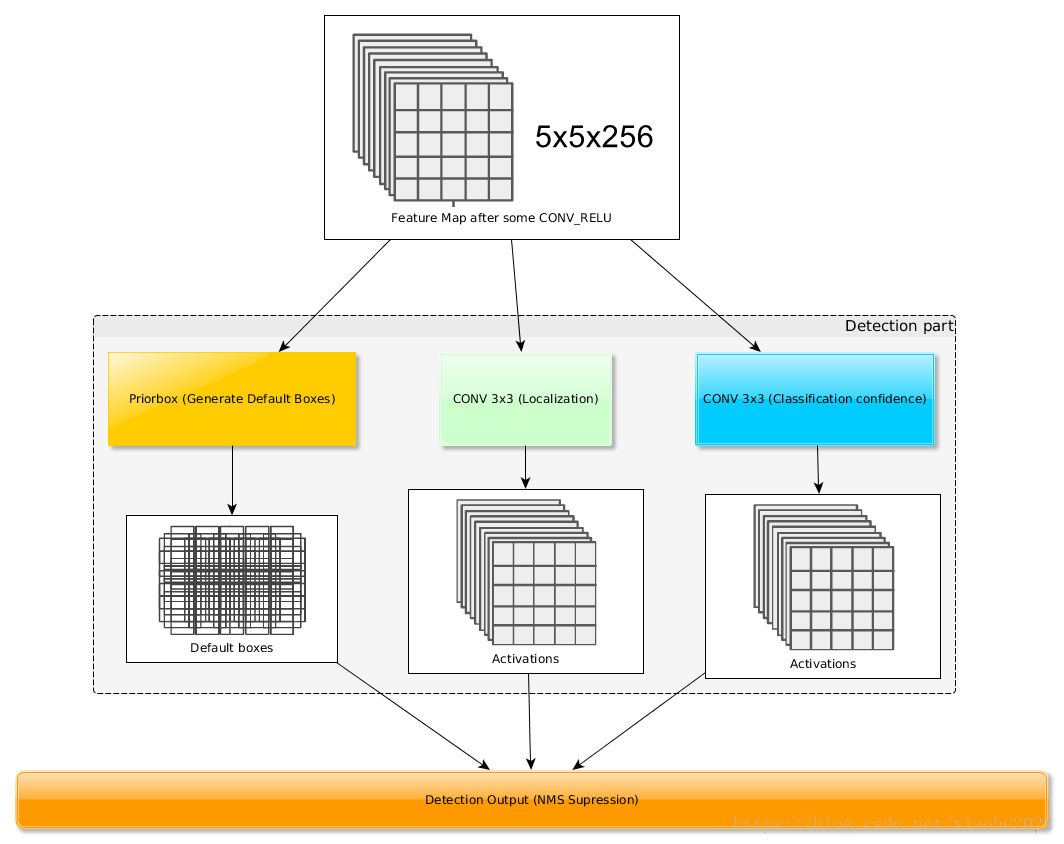
得到了特征图之后,需要对特征图进行卷积得到检测结果,图8给出了一个5×55×5个边界框,这是一个相当庞大的数字,所以说SSD本质上是密集采样。

- 基于深度学习的目标检测算法:SSD
- 深度学习 目标检测算法 SSD 论文简介
- 目标检测算法之SSD
- 目标检测算法SSD在window环境下GPU配置训练自己的数据集
- 【转载】从RCNN到SSD,这应该是最全的一份目标检测算法盘点(二)
- 基于深度学习的目标检测算法:SSD
- SSD目标检测算法中default box在ssd_pascal.py的设置
- 【转载】从RCNN到SSD,这应该是最全的一份目标检测算法盘点(三)
- 目标检测算法SSD源码解读~~~~~~~~~~ssd_pascal.py
- opencv3.3中基于ssd算法的目标检测示例教程
- 目标检测:SSD算法的Default Box
- SSD目标检测算法改进DSSD(反卷积)
- 目标检测算法的另一分支(one stage检测算法):YOLO、SSD、YOLOv2/YOLO 9000、YOLOv3
- SSD目标检测算法改进:DSOD(不需要预训练的目标检测算法)
- 目标检测算法SSD之训练自己的数据集
- 目标检测算法之SSD
- 【目标检测】SSD算法—-模型结构的详解及Python源码分析
- 目标检测算法SSD在Ubuntu+CPU下运行
- SSD目标检测算法中default box在ssd_pascal.py的设置