基于standalone的Spark架构与工作原理理解
standalone模式下的模块架构
Client 客户端进程,负责提交作业到Maste
Client就是我们的客户端,例如我们在windows上通过eclipse编写Scala程序向Spark提交作业,那么我们的Client就是eclipse
Master Standalone模式中主节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
Master在这里就相当于一个公司的包工头,负责接收Client提交上来的作业,然后管理Worker。
Worker Standalone模式中的从节点,负责管理本节点的资源,定期向Master汇报心跳,接受Master的命令,启动Driver和Executor。
那么Worker就比较苦逼了,作为一个小打工仔,除了定期要向Master汇报执行情况,还要无条件接受Master各种唧唧歪歪的命令,还得找到一个Driver来帮助自己,负责找到负责具体执行任务的执行人Executor来执行需要完成的任务。
Driver 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析,生成Stage并调度Task到Executor上。包括DAGScheduler(有向无环图调度器),TaskScheduler(任务调度器)。
我们的司机在收到Worker打工仔的命令后开始工作,首先要找老板要点资源经费,之后将作业转化为RDD Gragh,再由DAGScheduler将RDD Gragh转化成一个或多个Stage阶段,每个Stage根据RDD的Partition数量决定Task的个数,又形成一个个Taskset,然后给TaskScheduler负责分配给Executor执行者。
Executor 真正执行作业的地方,一个集群一般包含多个Executor,每个Executor,每个Executor接受Driver的命令Launch Task,一个Executor可以执行一到多个Task。
Spark的四大核心组件
1.Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源类型,例如Hive表、Parquet以及JSON等。Spark SQL不仅为Spark提供了一个SQL接口,还支持开发者将SQL语句融入到Spark应用程序开发过程中,无论是使用Python、Java还是Scala,用户可以在单个的应用中同时进行SQL查询和复杂的数据分析。由于能够与Spark所提供的丰富的计算环境紧密结合,Spark SQL得以从其他开源数据仓库工具中脱颖而出。Spark SQL在Spark l.0中被首次引入。在Spark SQL之前,美国加州大学伯克利分校曾经尝试修改Apache Hive以使其运行在Spark上,进而提出了组件Shark。然而随着Spark SQL的提出与发展,其与Spark引擎和API结合得更加紧密,使得Shark已经被Spark SQL所取代。
2.Spark Streaming
众多应用领域对实时数据的流式计算有着强烈的需求,例如网络环境中的网页服务器日志或是由用户提交的状态更新组成的消息队列等,这些都是实时数据流。Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。由于这些API与Spark Core中的基本操作相对应,因此开发者在熟知Spark核心概念与编程方法之后,编写Spark Streaming应用程序会更加得心应手。从底层设计来看,Spark Streaming支持与Spark Core同级别的容错性、吞吐量以及可伸缩性。
3.MLlib
MLlib是Spark提供的一个机器学习算法库,其中包含了多种经典、常见的机器学习算法,主要有分类、回归、聚类、协同过滤等。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化基础算法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。
4.GraphX
GraphX是Spark面向图计算提供的框架与算法库。GraphX中提出了弹性分布式属性图的概念,并在此基础上实现了图视图与表视图的有机结合与统一;同时针对图数据处理提供了丰富的操作,例如取子图操作subgraph、顶点属性操作mapVertices、边属性操作mapEdges等。GraphX还实现了与Pregel的结合,可以直接使用一些常用图算法,如PageRank、三角形计数等。
standalone的Spark工作原理理解
Spark的工作分为两种,一种是在Worker上,一种是在Local上。
首先我们先看一下RDD的两种操作,Tranformation和Action
Tranformation是得到一个新的RDD,方式很多,比如从数据源生成一个RDD,或是从一个RDD生成一个新的RDD
Action是得到一个值,或是一个结果。
Tranformation是最懒的,当你只提交Tranformation时,他是不会进行计算的,只有在提交Action时,他才会被触发计算
接下来我们来看RDD的宽窄依赖
如果子RDD中的分区依赖数个父RDD中的分区,就是窄依赖(narrow-dependency)
如果子RDD中的分区依赖父RDD中的所有分区,就是宽依赖(wide-dependency)
如下图所示

图中矩形框围住的部分是RDD, 实心小矩形是分区(Partition)
在RDD经过Tranformation将数据源形成一个个RDD后,当用户调用Action函数时,DAGScheduler会逆向遍历该RDD的宗族(lineage)以形成Stage,每个Stage会尽可能的包含连续的窄依赖;如果当前的Stage向上回溯时遇见宽依赖,则当前Stage结束,一个新的Stage被构建,第二个Stage是第一个Stage的parent,还有一种情况也会结束当前Stage,那就是那个partition已经被其他的Action计算出来,缓存在内存中,这种情况下我们就不必作多余的计算了。
在向上回溯时遇见宽依赖的情况下,生成新的Stage后,宽依赖会触发Shuffle操作,例如下图

我们抽象出其中的RDD和抽象关系:A-w-B-n-G C-n-D-n-F-w-G E-n-F-w-G
对应的划分后的RDD结构为:

最终我们得到了整个执行过程:

完整的shuffle过程就是在前一个Stage中创建ShuffleMapTask 进行Shuffle Write 将数据写入到Block Manager中,并且将数据位置元信息上报到Driver中的mapoutTrack中,下一个Stage根据数据位置元信息,进行Shuffle Read 拉取上个Stage中的输出信息。
BB那么多,现在我们来看Driver在Local上是如何工作的:

1.客户端启动后直接运行用户程序,启动Driver相关的工作:DAGScheduler和BlockManagerMaster等。
2.客户端的Driver向Master注册。
3.Master还会让Worker启动Exeuctor。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
4.ExecutorBackend启动后会向Driver的SchedulerBackend注册。Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过TaskScheduler分配给Executor执行。
5.所有stage都完成后作业结束
Driver在Worker上:
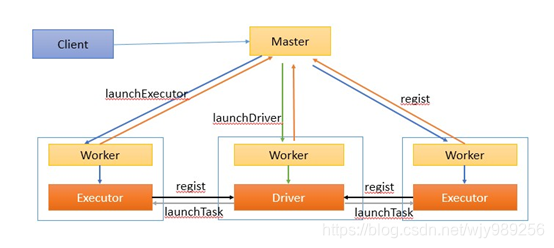
1。客户端提交作业给Master
2.Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。
3。另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
4。ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。
5.所有stage都完成后作业结束。
参考:
https://www.jianshu.com/p/da75bb9f3629
https://blog.csdn.net/zhuiqiuuuu/article/details/84330127

- 第2课:通过案例对SparkStreaming透彻理解三板斧之二:解密SparkStreaming运行机制和架构
- 深入理解Spark 2.1 Core (七):Standalone模式任务执行的原理与源码分析
- 第2课:通过案例对SparkStreaming 透彻理解三板斧之二:解密SparkStreaming运行机制和架构
- IMF传奇行动第82课:Spark Streaming第一课:案例动手实战并在电光石火间理解其工作原理
- 第82课:Spark Streaming第一课:案例动手实战并在电光石火间理解其工作原理
- 量化派基于Hadoop、Spark、Storm的大数据风控架构--转
- 深入理解STM32之储存器和总线架构2(基于STM32F411)
- 深入理解Spark 2.1 Core (五):Standalone模式运行的原理与源码分析
- 深入理解Spark 2.1 Core (八):Standalone模式容错及HA的原理与源码分析
- Hadoop1.0 MapReduce工作原理 与 Hadoop 2.x Yarn 设计理验与基本架构理解
- 第3课:SparkStreaming 透彻理解三板斧之三:解密SparkStreaming运行机制和架构进阶之Job和容错
- Spark定制班第2课:通过案例对Spark Streaming透彻理解三板斧之二:解密Spark Streaming运行机制和架构
- 深入理解Spark 2.1 Core (八):Standalone模式容错及HA的原理与源码分析
- spark与hadoop架构比较理解链接
- 基于Kafka的实时计算引擎如何选择?Spark or Flink? - 架构
- Spark定制班第3课:通过案例对SparkStreaming 透彻理解三板斧之三:解密SparkStreaming运行机制和架构进阶之Job和容错
- 第3课:通过案例对SparkStreaming 透彻理解三板斧之三:解密SparkStreaming运行机制和架构进阶
- Spark定制班第3课:通过案例对SparkStreaming透彻理解三板斧之三:解密Spark Streaming运行机制和架构进阶之Job和容错
- Spark 概念学习系列之Apache Spark 架构详解(十)(必须好好理解悟透)
- 基于消息的分布式架构理解1