大数据应用技术实验报告一 Hadoop三种模式安装配置
JDK+Hadoop安装配置、单机模式配置
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
(以上来自百度百科)
以下操作在SecureCRT里面完成
1.关闭防火墙
firewall-cmd --state 显示防火墙状态running/not running
systemctl stop firewalld 临时关闭防火墙,每次开机重新开启防火墙
systemctl disable firewalld 禁止防火墙服务。
2.传输JDK和HADOOP压缩包
SecureCRT 【File】→【Connect SFTP Session】开启sftp操作
put jdk-8u121-linux-x64.tar.gz
put hadoop-2.7.3.tar.gz
传输文件从本地当前路径(Windows)到当前路径(Linux)


3.解压JDK、HADOOP
tar -zxvf jdk-8u121-linux-x64.tar.gz -C /opt/module 解压安装
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/module 解压安装
4.配置JDK并生效
vi /etc/profile文件添加:
export JAVA_HOME=/opt/module/jdk1.8.0_121
export PATH=JAVAHOME/bin:JAVA_HOME/bin:JAVAHOME/bin:PATH
Esc :wq!保存并退出。不需要配置CLASSPATH。
source /etc/profile配置生效
运行命令javac,检验是否成功。
5.配置HADOOP并生效
vi /etc/profile文件添加:
export HADOOP_HOME=/opt/module/hadoop-2.7.3
export PATH=HADOOPHOME/bin:HADOOP_HOME/bin:HADOOPHOME/bin:HADOOP_HOME/sbin:$PATH
Esc :wq!保存并退出。
source /etc/profile配置生效
运行命令hadoop,检验是否成功。
5.单机模式配置hadoop -env.sh
vi /opt/module/hadoop-2.7.3/etc/hadoop/hadoop-env.sh文件修改
显示行号 Esc :set number 取消行号Esc :set nonumber
修改第25行export JAVA_HOME=/opt/module/jdk1.8.0_121
Esc :wq!保存并退出
本地模式没有HDFS和Yarn,配置JDK后MapReduce能够运行java程序。
6.运行自带程序wordcount
cd /opt/module/hadoop-2.7.3/share/hadoop/mapreduce 转入wordcount所在路径。
运行touch in.txt,创建In.txt文件,作为输入文件。
(如果in.txt是空文件,运行vi in.txt,输入内容作为被统计词频的输入文件)
输出目录/output必须不存在,程序运行后自动创建。
运行wordcount:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /adir/in.txt output/
运行成功之后,进入/output目录,打开文件part-r-00000查看计数结果。
Hadoop伪分布式模式配置
只有一台虚拟机bigdata128,既是namenode又是datanode。
一、基础安装配置
完成上述1-5安装配置。
二、修改以下5个配置文件
在与之间添加如下property:
①core-site.xml
Hadoop完全分布式模式配置
一、新建另外两台Linux虚拟机
完全分布式模式共三台虚拟机,前述伪分布式的虚拟机(bigdata128)作为master主节点,克隆另外两个虚拟机(bigdata129、bigdata131)作为slaves子节点,克隆机自带安装JDK、Hadoop及配置文件。
注:此配置是为学习所用,且电脑资源有限,因此照搬伪分布式配置,将NameNode、SecondaryNameNode、ResourceManager全部配置在主节点bigdata128上面,实际情况则相反,应该分别配置在不同的节点上面。
二、修改以下配置文件
①slaves配置文件
三台虚拟机分别都运行命令 vi /opt/module/hadoop-2.7.3/etc/hadoop slaves
修改slaves为:
bigdata129
bigdata131
②修改\etc\hosts配置文件
三台虚拟机分别都运行命令 vi \etc hosts
注释已有内容,添加集群三台虚拟机的ip及对应主机名:
192.168.163.128 bigdata128
192.168.163.129 bigdata129
192.168.163.131 bigdata131
③修改\etc\hostname配置文件
三台虚拟机分别都运行命令 vi \etc hostname
添加各自的主机名bigdata128或者bigdata129或者bigdata131。
重启全部虚拟机,主机名生效。
三、格式化
在主节点bigdata128上面输入格式化命令(hdfs namenode -format),格式化集群。
注:如果不是第一次格式化,三台虚拟机都删除\opt\module\hadoop-2.7.3\下面的tmp、logs目录:rm –rf \opt\module\hadoop-2.7.3\tmp rm –rf \opt\module\hadoop-2.7.3\logs
注:如果格式化之前启动过集群,先在主节点bigdata128上面停止集群(stop-all.sh),再格式化。
四、启动集群
在主节点bigdata128上面输入启动命令(start-all.sh),启动集群。
注:如果启动之前启动过集群,先在主节点bigdata128上面停止集群(stop-all.sh),再启动。
启动正常,输入jps命令,显示如下:

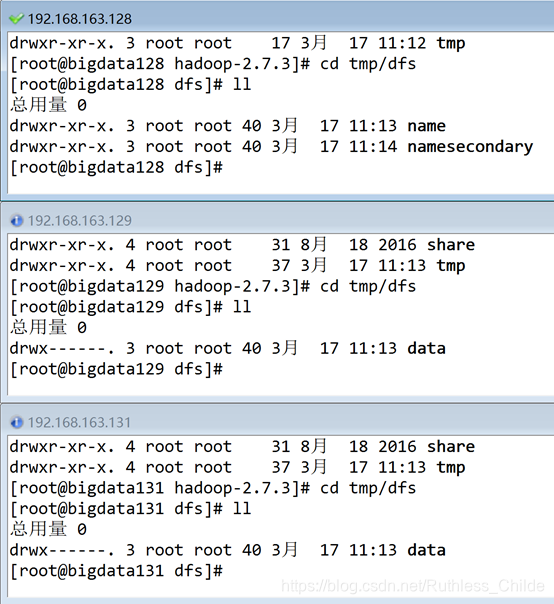
启动正常jps显示3台主机如上如下

启动正常目录显示如下:
web控制台访问:http://192.168.163.132:50070 、http://192.168.163.132:8088
页面正常显示,则成功。
五、运行wordcount
hdfs dfs -put in.txt /adir 上传本地当前路径下的in.txt文件 到hdfs的/adir目录下。
运行hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /adir/in.txt output/。
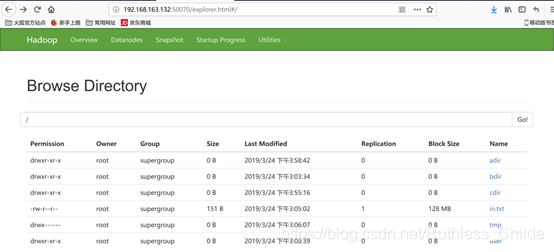
在http://192.168.163.132:50070 查看/user/root/output/part-r-00000文件里的词频统计结果。
如下图所示:



- 大数据应用技术实验报告二 HDFS命令和Java API
- 大数据应用技术实验报告七 Spark
- 大数据应用技术实验报告四 HBase
- 大数据应用技术实验报告六 Hive和MySQL
- JDK+Hadoop安装配置、单机模式配置(实验一)
- 大数据应用技术实验报告五 NoSQL
- 大数据应用技术实验报告三 MapReduce分布式编程
- Lvs之NAT、DR、TUN三种模式的应用配置案例
- 配置安装zabbix实验报告
- hadoop完全分布式模式的安装和配置
- Ubuntu下安装配置Hadoop独立模式和伪分布式
- hadoop0.20.2完全分布模式安装和配置
- Lvs之NAT、DR、TUN三种模式的应用配置案例
- hadoop初识之三:搭建hadoop环境(配置HDFS,Yarn及mapreduce 运行在yarn)上及三种运行模式(本地模式,伪分布式和分布式介)
- 完全分布模式hadoop集群安装配置之二 添加新节点组成分布式集群
- Ubuntu11.10下安装和配置hadoop2.20(单机模式)
- Lvs之NAT、DR、TUN三种模式的应用配置案例
- hadoop+zookeeper+hbase安装、配置及应用实例
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式