大数据应用技术实验报告三 MapReduce分布式编程
2019-05-25 15:28
435 查看
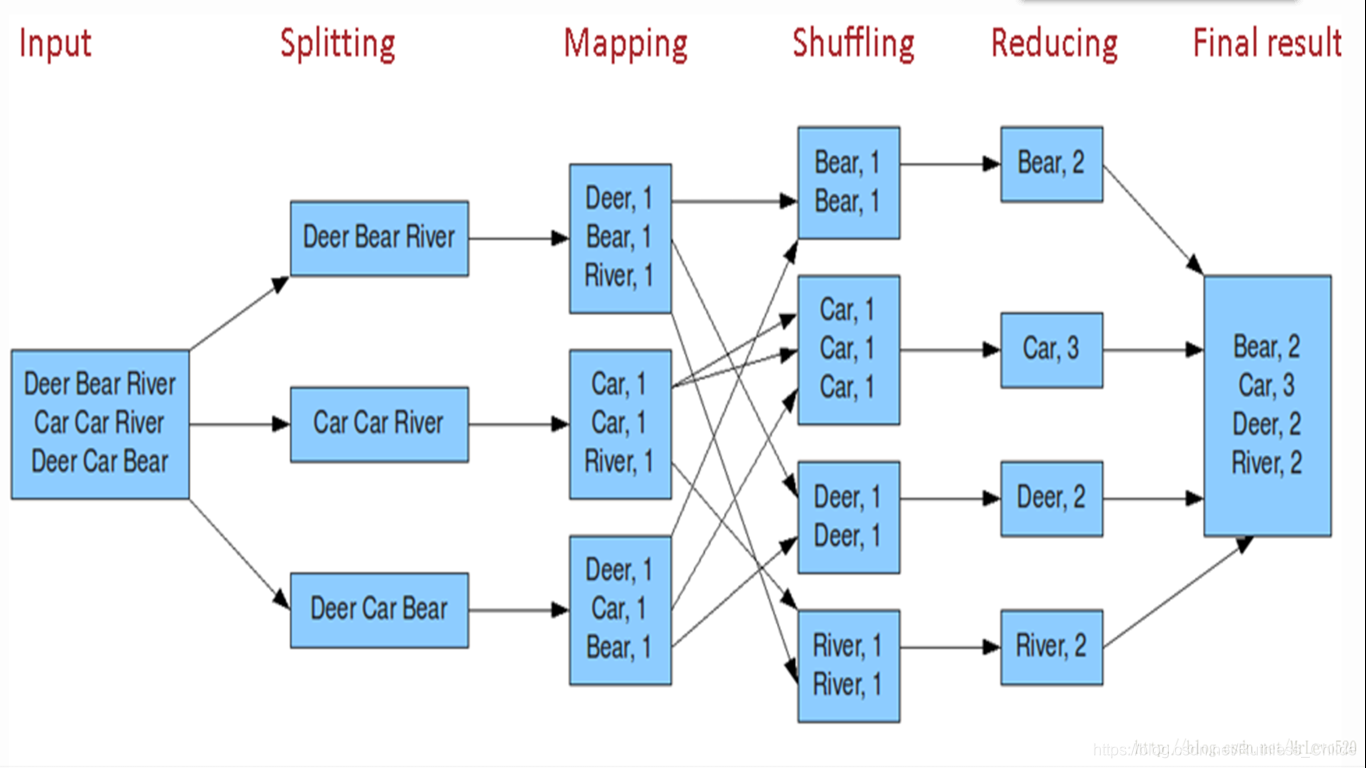
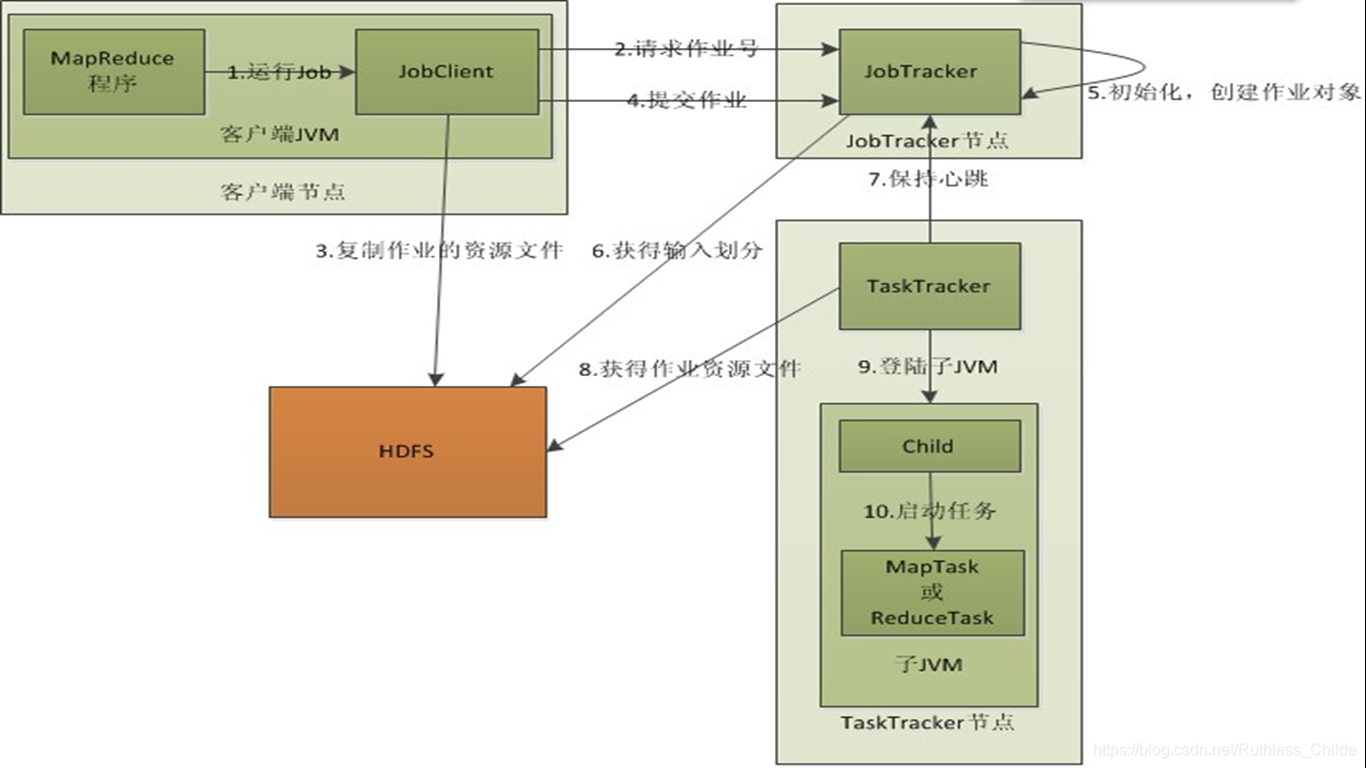
MapReduce 分布式计算系统

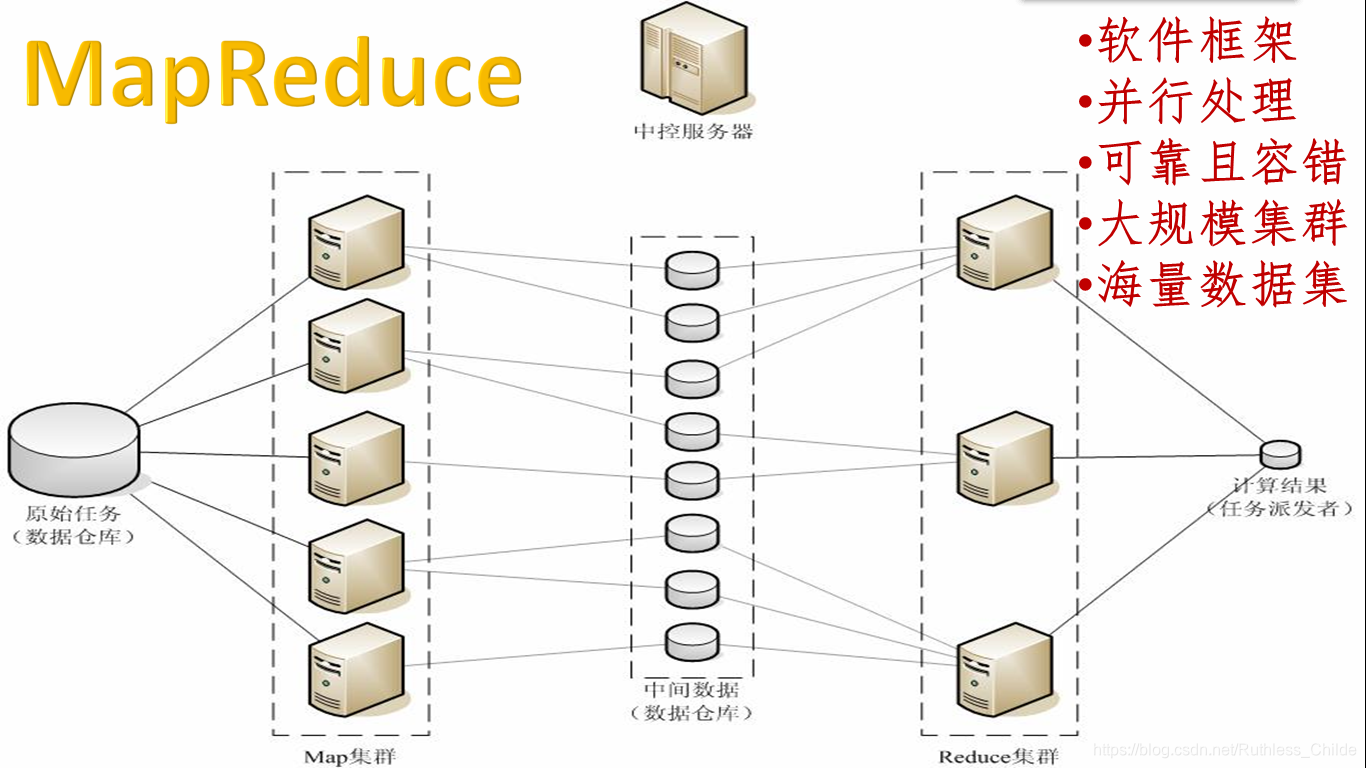
Mapper负责“分”
分解计算任务,规模大大缩小;
“计算向数据靠近” ;
这些小任务可以并行计算。
Reducer负责“汇总” map阶段的结果
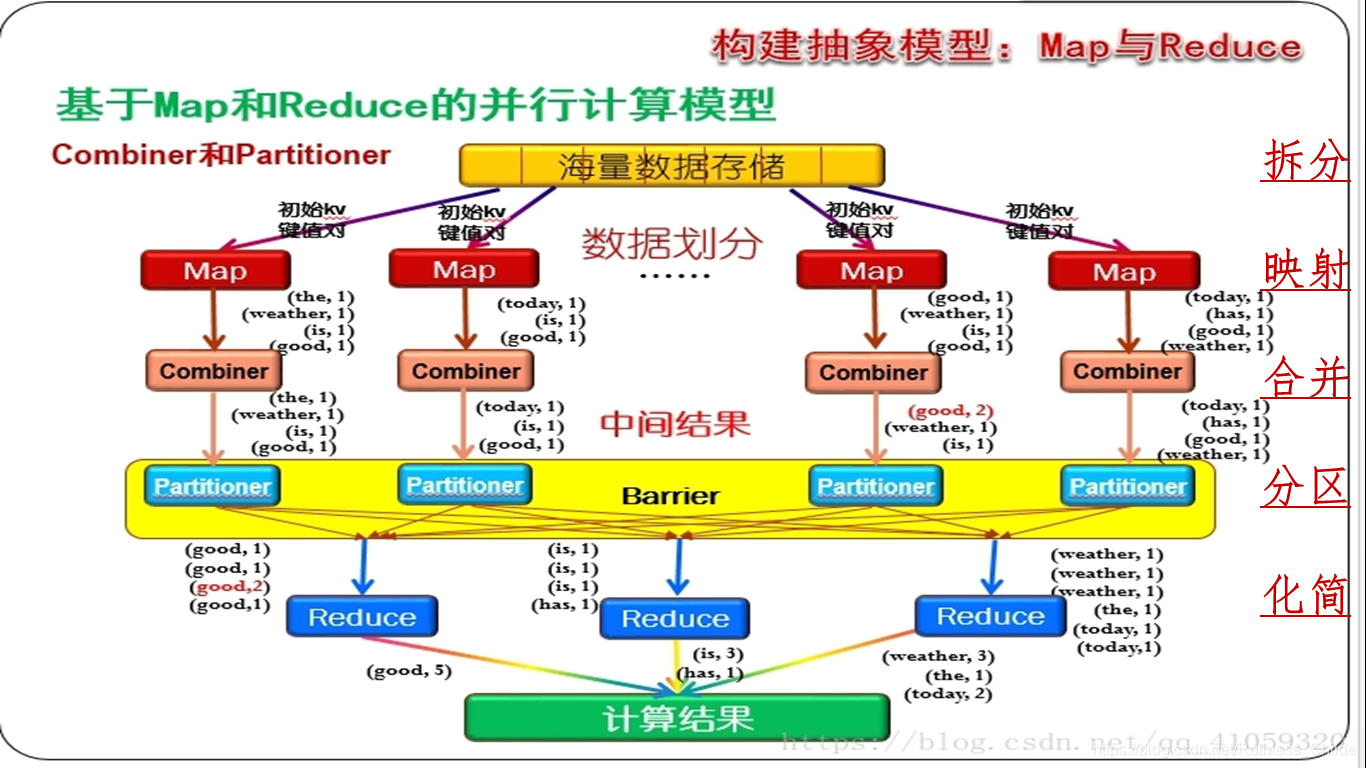
Combiner函数
本地化的reducer
Partitioner函数
决定着Map节点的输出将被分区到哪个Reduce节点
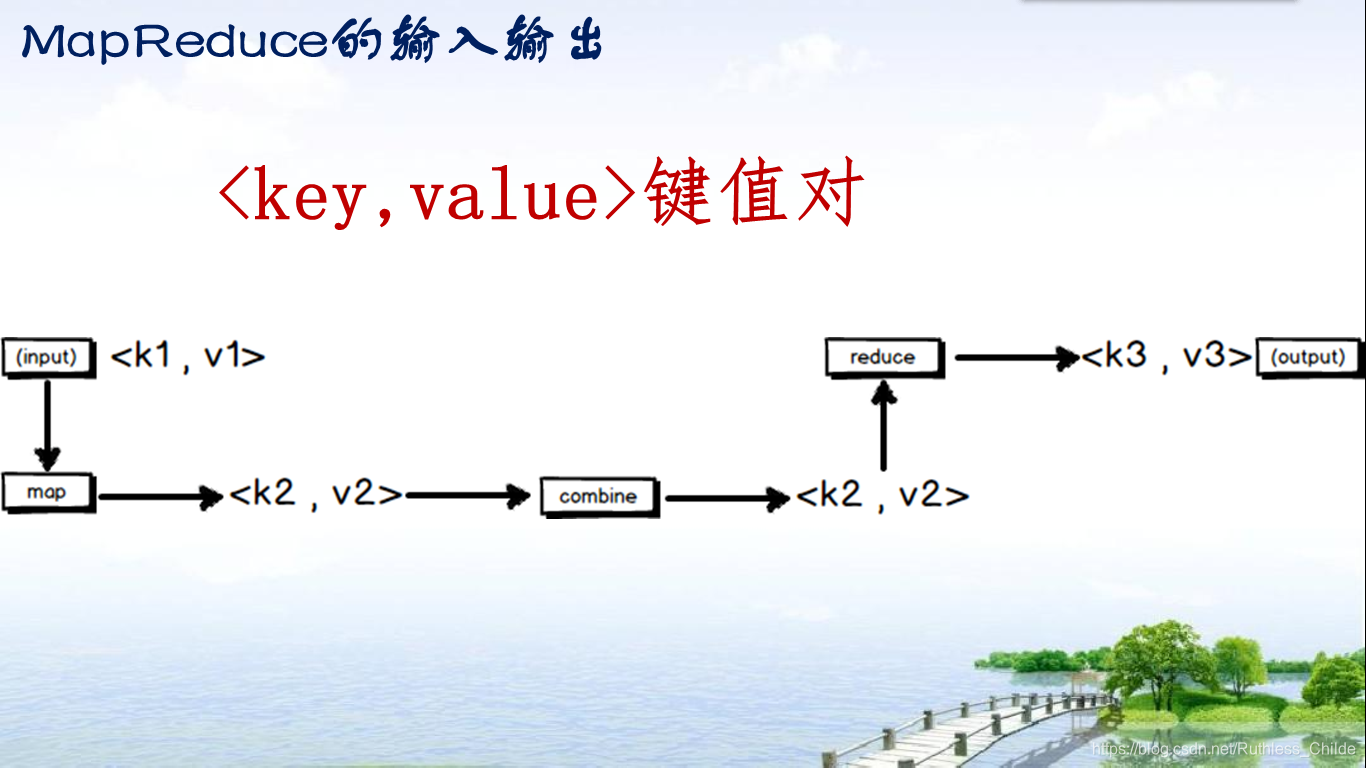
什么是shuffle
怎样把map task的输出结果有效地传送到reduce端?
map输出之前,在内存里经过sort和combiner,再将所有的输出集合到partitioner进行划分到不同的reducer,在每个分区(partition)中,再进行内存中排序,再运行combiner,最后输出到HDFS。








相关文章推荐
- 大数据应用技术实验报告五 NoSQL
- 大数据应用技术实验报告六 Hive和MySQL
- 大数据应用技术实验报告七 Spark
- 大数据应用技术实验报告四 HBase
- 分布式编程模式MapReduce应用
- 分布式编程模式MapReduce应用
- 20155307 刘浩 信息安全技术(李冬冬) 实验三 数字证书应用 实验报告
- 大数据技术 - MapReduce 应用的配置和单元测试
- Java分布式应用技术架构介绍
- 实验一: vc编程灵活应用
- 浅谈HOOK技术在VC编程中的应用 .
- C#实验8Windows应用编程
- 分布式应用的各基本领域及开发技术概要
- 萃取(traits)编程技术的介绍和应用
- [Hadoop]MapReduce编程---分布式grep的实现
- 实验五 网络编程与安全 实验报告
- 《数据结构》实验一:VC编程环境灵活应用
- 《数据结构》实验一:VC编程工具的灵活使用 实验报告
- 浅谈HOOK技术在VC编程中的应用