Python数据分析:scikit-learn基础(二)
2019-05-06 14:55
676 查看
Python数据分析:scikit-learn基础(二)
使用scikit-learn流程

- 数据处理 数据集格式
- 二维数组,形状(n_samples,n_features)
- 使用np.reshape()转换数据集形状
-
特征提取
-
preprocessing.scale()

- estimator对象
- 从训练数据学习得到
- 可以使分类算法、回归算法或是特征提取算法
- fit方法用于训练estimator
- estimator的参数可以训练前初始化或者之后更新
- get_params()返回之前定义的参数
- score()对estimator进行评分 回归模型使用决定系数评分(coefficient of determination)
- 分类模型使用准确率评分(accuracy)
- 依靠经验
- 交叉验证(cross validation) cross_val_score()
- model.predict(X_test) 返回测试样本的预测标签
- model.score(X_test,y_test) 根据预测值和真实值计算评分
import numpy as np
from sklearn.model_selection import train_test_split
X = np.random.randint(0, 100, (10, 4))
y = np.random.randint(0, 3, 10)
y.sort()
print('样本:')
print(X)
print('标签:', y)
运行:

# 分割训练集、测试集
# random_state确保每次随机分割得到相同的结果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3., random_state=7)
print('训练集:')
print(X_train)
print(y_train)
print('测试集:')
print(X_test)
print(y_test)
运行:

# 特征归一化
from sklearn import preprocessing
x1 = np.random.randint(0, 1000, 5).reshape(5,1)
x2 = np.random.randint(0, 10, 5).reshape(5, 1)
x3 = np.random.randint(0, 100000, 5).reshape(5, 1)
X = np.concatenate([x1, x2, x3], axis=1)
print(X)
print('归一化后的数据集:')
print(preprocessing.scale(X))
运行:

from sklearn import svm from sklearn.datasets import make_classification X, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2, random_state=25, n_clusters_per_class=1, scale=100) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3., random_state=7) svm_classifier = svm.SVC() svm_classifier.fit(X_train, y_train) svm_classifier.score(X_test, y_test)
运行:

from sklearn import svm from sklearn.datasets import make_classification X, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2, random_state=25, n_clusters_per_class=1, scale=100) #归一化 X = preprocessing.scale(X) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3., random_state=7) svm_classifier = svm.SVC() svm_classifier.fit(X_train, y_train) svm_classifier.score(X_test, y_test)
运行:

from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
%matplotlib inline
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3., random_state=10)
k_range = range(1, 31)
cv_scores = []
for n in k_range:
knn = KNeighborsClassifier(n)
scores = cross_val_score(knn, X_train, y_train, cv=10, scoring='accuracy') # 分类问题使用
cv_scores.append(scores.mean())
plt.plot(k_range, cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()
运行:

# 选择最优的K best_knn = KNeighborsClassifier(n_neighbors=5) best_knn.fit(X_train, y_train) print(best_knn.score(X_test, y_test)) print(best_knn.predict(X_test))
运行:
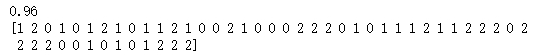

相关文章推荐
- python3.6中安装numpy,pandas,scipy,scikit_learn,matplotlib等数据分析工具
- Python数据分析与机器学习-scikit-learn模型建立与评估
- 尝试向分析类转型1--scikit-learn(机器学习) 和 Weka(数据挖掘)
- 利用python进行数据分析-NumPy基础2
- 利用python进入数据分析之Numpy基础知识
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
- 【scikit-learn】04:sklearn库下进行文本数据分析
- Python数据挖掘入门与实践(二)——用scikit-learn估计器分类
- 用python进行数据分析笔记1--基础知识篇
- python data analysis | python数据预处理(基于scikit-learn模块)
- 利用Python进行数据分析 pandas基础: 处理缺失数据
- Python 数据分析包:pandas 基础
- python数据分析基础4_参考博文
- 大数据实战课程第一季Python基础和网络爬虫数据分析
- 利用Python进行数据分析(14) pandas基础: 数据转换
- PythonStock(17):使用scikit-learn进行股票分析
- Python玩转数据分析学习笔记-01基础
- 利用 Python 进行数据分析(四)NumPy 基础:ndarray 简单介绍
- 利用Python进行数据分析(13) pandas基础: 数据重塑/轴向旋转
- 利用Python数据分析:Numpy基础(一)