Python数据分析:scikit-learn基础(一)
2019-05-05 16:02
288 查看
Python数据分析:scikit-learn基础(一)
基本步骤:-
加载示例数据集
digits
在训练集上训练模型
-
SVM模型
在测试集上测试模型
-
.predict() 进行预测
保存模型
-
pickle.dumps()
加载模型预测
加载示例数据集
from sklearn import datasets digits = datasets.load_digits() # 查看数据集digits print(digits.data) print(digits.data.shape) print(digits.target_names) print(digits.target)
运行:

训练模型
# 手动划分训练集、测试集 n_test = 100 # 测试样本个数 train_X = digits.data[:-n_test, :] train_y = digits.target[:-n_test] test_X = digits.data[-n_test:, :] y_true = digits.target[-n_test:] # 选择SVM模型 from sklearn import svm svm_model = svm.SVC(gamma=0.001, C=100.) # 训练模型 svm_model.fit(train_X, train_y)
运行:
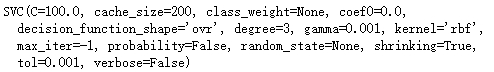
# 选择LR模型 from sklearn.linear_model import LogisticRegression lr_model = LogisticRegression() # 训练模型 lr_model.fit(train_X, train_y)
运行:

测试模型:
y_pred_svm = svm_model.predict(test_X)
y_pred_lr = lr_model.predict(test_X)
# 查看结果
from sklearn.metrics import accuracy_score
print('SVM结果:', accuracy_score(y_true, y_pred_svm))
print('LR结果:', accuracy_score(y_true, y_pred_lr))
运行:

保存模型
import pickle
#保存模型
with open('svm_model.pkl', 'wb') as f:
pickle.dump(svm_model, f)
加载模型预测
import numpy as np
# 重新加载模型进行预测
with open('svm_model.pkl', 'rb') as f:
model = pickle.load(f)
random_samples_index = np.random.randint(0, 1796, 5)
random_samples = digits.data[random_samples_index, :]
random_targets = digits.target[random_samples_index]
random_predict = model.predict(random_samples)
print(random_predict)
print(random_targets)
运行:


相关文章推荐
- Python数据分析:scikit-learn基础(二)
- python3.6中安装numpy,pandas,scipy,scikit_learn,matplotlib等数据分析工具
- Python数据分析与机器学习-scikit-learn模型建立与评估
- 尝试向分析类转型1--scikit-learn(机器学习) 和 Weka(数据挖掘)
- 利用python进行数据分析-NumPy基础2
- 利用python进入数据分析之Numpy基础知识
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
- 【scikit-learn】04:sklearn库下进行文本数据分析
- Python数据挖掘入门与实践(二)——用scikit-learn估计器分类
- 用python进行数据分析笔记1--基础知识篇
- python data analysis | python数据预处理(基于scikit-learn模块)
- 利用Python进行数据分析 pandas基础: 处理缺失数据
- Python 数据分析包:pandas 基础
- python数据分析基础4_参考博文
- 大数据实战课程第一季Python基础和网络爬虫数据分析
- 利用Python进行数据分析(14) pandas基础: 数据转换
- PythonStock(17):使用scikit-learn进行股票分析
- Python玩转数据分析学习笔记-01基础
- 利用 Python 进行数据分析(四)NumPy 基础:ndarray 简单介绍
- 利用Python进行数据分析(13) pandas基础: 数据重塑/轴向旋转