图像语义分割模型——FCN(一)
简介
图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。
FCN论文地址:https://arxiv.org/pdf/1411.4038.pdf
一、FCN由来:
截止目前,CNN已经在图像分类分方面取得了巨大的成就,涌现出如VGG和Resnet等网络结构,并在ImageNet中取得了好成绩。CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:
- 较浅的卷积层感知域较小,学习到一些局部区域的特征;
- 较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。
这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。图像分类是图像级别的!
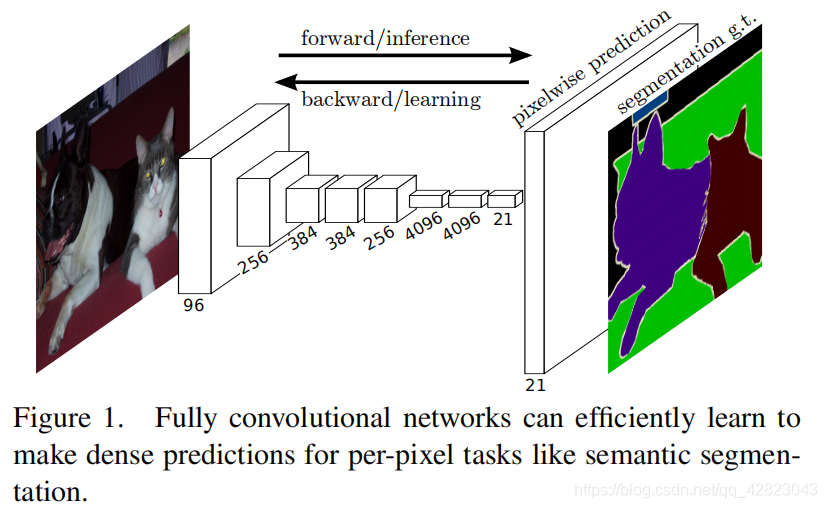
与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。**图像语义分割是像素级别的!**但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
针对这个问题,Jonathan Long等人提出了全卷积神经网络(Fully Convolutional Networks)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。
二、FCN原理:
FCN(Fully Convolutional Networks)全卷积,意思就是该网络中没有全链接层,全部用卷积层来代替了 ,全卷积化也是其他领域深度模型的一个趋势,除了分类网络最后必须保留一个全链接层用于分类外,其他领域都有去掉全链接层的趋势,如检测领域的R-FCN等。
论文主要思路是把CNN改为FCN,输入一幅图像后直接在输出端得到dense prediction,也就是每个像素所属的class,从而得到一个end-to-end的方法来实现image semantic segmentation。
首先我们已经有一个CNN模型,首先要把CNN的全连接层看成是卷积层,卷积模板大小就是输入的特征map的大小,也就是说把全连接网络看成是对整张输入map做卷积,全连接层分别有4096个66的卷积核,4096个11的卷积核,1000个11的卷积核,如下图:
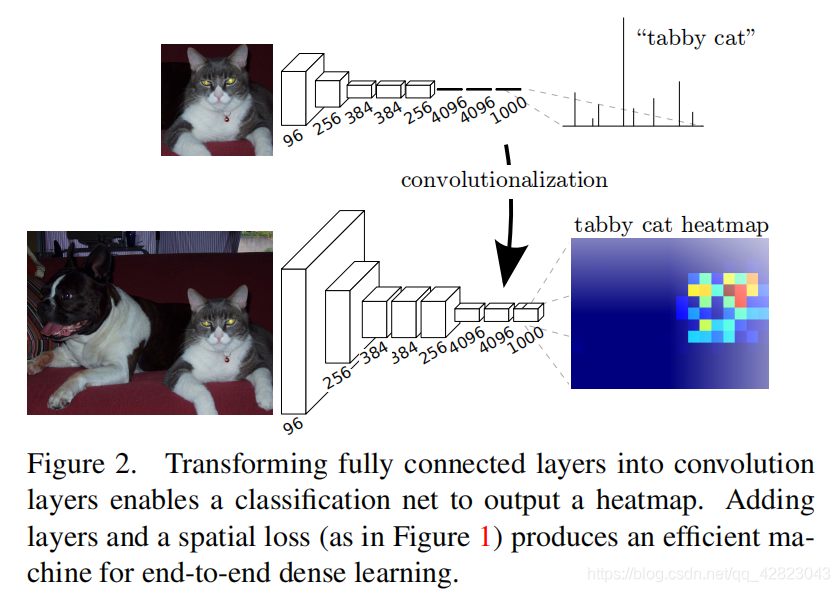
接下来就要对这1000个11卷积核的输出,做upsampling(上采样或反卷积),得到1000个原图大小(如32*32)的输出,这些输出合并后,得到上图所示的heatmap。
FCN的输入图片为什么可以是任意大小呢?
首先我们知道一个确定的CNN网络结构之所以要固定输入图片大小,是因为全连接层权值数固定,而该权值数和feature map大小有关。
而FCN在CNN的基础上把1000个结点的全连接层改为含有1000个1×1卷积核的卷积层,经过这一层,还是得到二维的feature map,同样我们也不关心这个feature map大小。到了反卷积层,注意,反卷积层也是卷积层,不关心input大小,滑窗卷积后输出output。最后,经过反卷积的处理再根据采样系数回到原图大小,从而得到像素级预测。
dense prediction:
这里通过upsampling得到dense prediction,作者研究过3种方案:
- shift-and-stitch:
简单的来讲shift and stitch的做法其实就是:
设降采样因子是f , 通过 shift pixels (平移像素)的方式,产生ff个version 的 input ,输入网络后相应地产生ff个output, 然后 stitch所有 output 就实现了 dense prediciton。
举一个简单的例子来直观地说明:
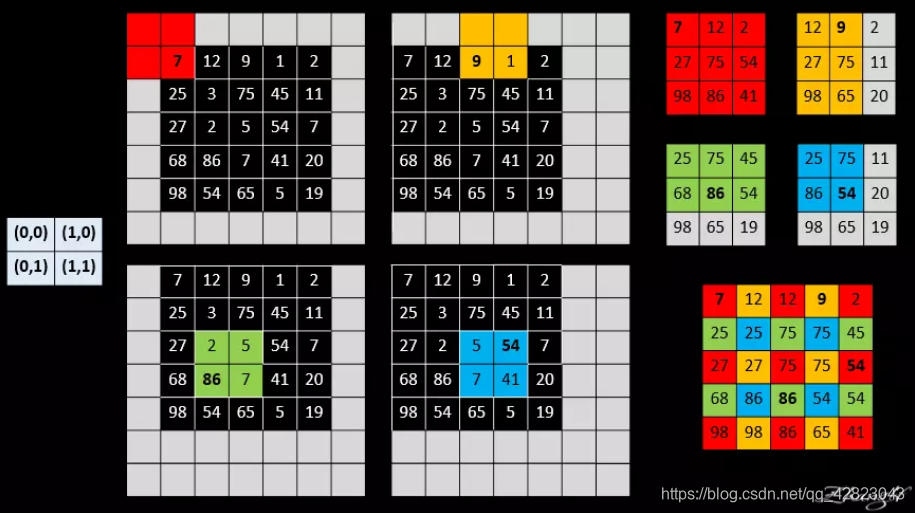
具体理解shift-and-stitch可以参考https://www.jianshu.com/p/e534e2be5d7d。 - filter rarefaction:
就是放大CNN网络中的subsampling层的filter的尺寸,得到新的filter:
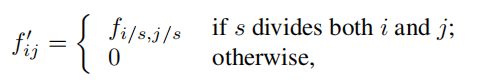
其中s是subsampling的滑动步长,这个新filter的滑动步长要设为1,这样的话,subsampling就没有缩小图像尺寸,最后可以得到dense prediction。 - upsampling:
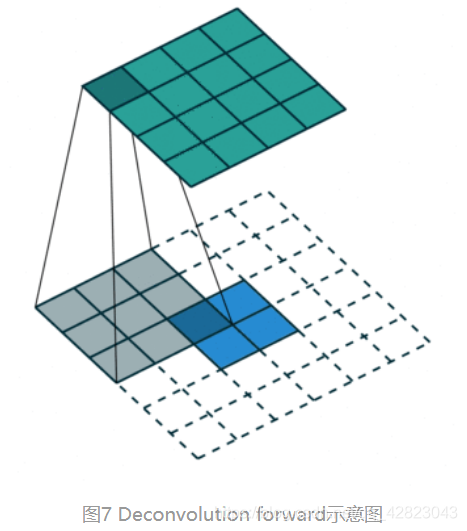
这里上采样(upsampling)的操作可以看成是反卷积(deconvolutional),卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。
对于第一种方法,虽然receptive fileds没有变小,但是由于原图被划分成f*f的区域输入网络,使得filters无法感受更精细的信息。
对于第二种方法, 下采样的功能被减弱,使得更细节的信息能被filter看到,但是receptive fileds会相对变小,可能会损失全局信息,且会对卷积层引入更多运算。
所以作者采用了第三种方法。
fusion prediction:
以上是对CNN的结果做处理,得到了dense prediction,而作者在试验中发现,得到的分割结果比较粗糙,所以考虑加入更多前层的细节信息,也就是把倒数第几层的输出和最后的输出做一个fusion,实际上也就是加和:
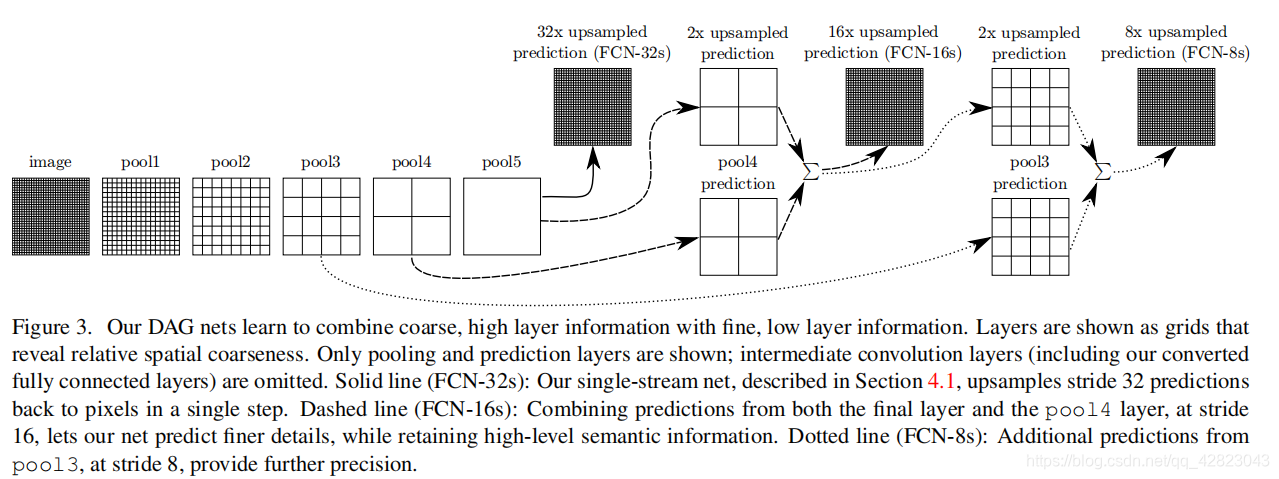
这里用的是VGG为例,pool1到pool5是五个最大池化层,因此图中的pool5层的大小是原图image的1/32,最粗糙的做法就是直接把pool5层进行步长为32的上采样(逆卷积),一步得到跟原图一样大小的概率图(fcn-32s)。但是这样做会丢失掉很多浅层的特征,尤其是浅层特征往往包含跟多的位置信息,所以我们需要把浅层的特征加上来,作者这里做法很简单,就是直接“加”上来,求和操作,也就完成了跳跃融合。也就是先将pool5层进行步长为2的上采样,然后加上pool4层的特征(这里pool4层后面跟了一个改变维度的卷积层,卷积核初始化为0),之后再进行一次步长为16的上采样得到原图大小的概率图即可(fcn-16s)。另外fcn-8s也是同样的做法,至于后面为什么没有fcn-4s、fcn-2s,我认为是因为太浅层的特征实际上不具有泛化性,加上了也没什么用,反而会使效果变差,所以作者也没继续下去了。
三、优点:
- 训练一个end-to-end的FCN模型,利用卷积神经网络的很强的学习能力,得到较准确的结果,以前的基于CNN的方法都是要对输入或者输出做一些处理,才能得到最终结果。
- 直接使用现有的CNN网络,如AlexNet, VGG16, GoogLeNet,只需在末尾加上upsampling,参数的学习还是利用CNN本身的反向传播原理。
- 不限制输入图片的尺寸,不要求图片集中所有图片都是同样尺寸,只需在最后upsampling时按原图被subsampling的比例缩放回来,最后都会输出一张与原图大小一致的dense prediction map。

- 全卷积神经网络 图像语义分割实验:FCN数据集制作,网络模型定义,网络训练(提供数据集和模型文件,以供参考)
- 全卷积神经网络 图像语义分割实验:FCN数据集制作,网络模型定义,网络训练(提供数据集和模型文件,以供参考)
- 图像语义分割之FCN和CRF
- 图像语义分割之FCN和CRF
- 图像语义分割之FCN和CRF
- 使用FCN做图像语义分割
- 图像语义分割之FCN和CRF
- 图像语义分割,全卷积网络FCN和条件随机场CRF、马尔可夫随机场MRF
- 图像语义分割之FCN和CRF
- Google最新语义图像分割模型DeepLab-v3+
- 深度学习(二十一)基于FCN的图像语义分割-CVPR 2015-未完待续
- Tensorflow实现图像分割——FCN模型
- 图像语义分割之FCN和CRF
- 图像语义分割之FCN和CRF
- 图像语义分割(1)- FCN
- 「Deep Learning」语义图像分割模型:DeepLab系统及其发展
- caffe随记(九)---利用FCN和已有的model进行图像语义分割
- FCN语义分割初探——使用训练好的模型进行分割
- FCN/MRF图像语义分割与马克尔夫随机场
- 使用FCN做图像语义分割(实践篇)