“深度学习与实践” 笔记(一)
2019-04-24 13:43
41 查看
“深度学习与实践” 笔记 第一课
Python 基础Attention
列表与元组的定义与用法
- 列表类型使用中括号 [] ;
- 列表:经常修改
- 列表表示顺序
- 列表不能作为字典key
- 用法:定义数据集D
- 数据列表包含所有的训练样本元组:[(1.73, 3.86, 2.50), (2.56, 9.75, 3.21), …]
- 标签列表包含所有标签 :[1, 2, …]
- ====================================
- 元组使用 圆括号 ();
- 元组:不可改变
- 元组表示结构
- 作为字典key
- 用法:定义单个训练样本,例如(1.73, 3.86, 2.50)、(2.56, 9.75, 3.21) 等。
列表与元组的访问
- Attention:列表和元组的访问都使用中括号
- 索引访问:从0开始
- 分片访问:
myList[0:3:1] [起点元素索引: 终点元素索引: 跨度]
- 左闭右开:起点元素包含在结果中,终点元素不包含在结果中

- 负数索引:从后往前计数,最后一个元素索引为-1
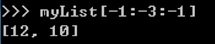
列表元素修改
- 元组元素不可修改,使用圆括号初始化的是元组。
- 列表修改时由于始终是左闭右开,就是说中括号右边的索引号并不会包括在修改范围内
- 列表在赋值修改时,使用逗号隔开,会替换掉中括号区间内的值,因此会发生元素数量的增减。
字典
- 元组作为字典key
- 字典保存带标签数据集, 使用大括号

- 大括号内元素使用“:”建立元组与标签的对应关系
- 字典使用元组(在字典中为键)的值进行索引、取值,添加删除
- 键不能直接修改,值可以
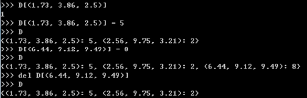
- 遍历字典:

字典类型的函数
D.keys()//输出所有的键
D.values()//输出所有的值
D.get((元组键)) //输出的是键的值
D.popitem()// 将后面的元组推出数据集
D.pop((元组键))// 输出对应的值,并出栈
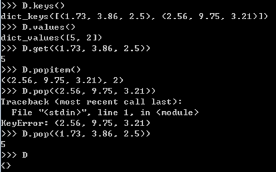
集合(Set):无序!不重复!的元素序列。
- 创建: 大括号! 或者 函数Set() 以及 列表
- 创建空集:只能用Set(), 大括号会创建空字典
- 作用:统计数据集类别数量
- 如图,使用set(列表) 可将列表中重复的合并,生成新集合
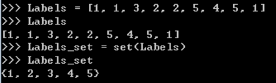
集合运算

集合操作
- 添加元素
s.add( x )
- 移除元素
s.remove( x )
- 计算集合元素个数
len(s)
- 清空集合
s.clear()
- 判断元素是否在集合中存在
x in s
- 通过将数据集标签列表转为集合,可获取类别数量等信息
Python 函数返回值
- Python 函数定义使用
def 函数名(参数,参数....)
与c++类似,但要注意缩进! - Python 函数仅支持返回一个值,但是可以通过返回元组的方式变相实现多个返回值
def sumReturn(start, end):
…
return result, start, end
a, b, c = sumReturn(1, 10)
_, _, d = sumReturn(1, 10)
e = sumReturn(1, 10)
#运 行结 果 如 下: ’
55
1
10
10
(55, 1, 10)
Python 库
导入模块的三种方式
import numpy
-a = numpy.array(…)
import numpy as np
-a = np.array(…)
from numpy import array
-a = array(…)
处理表格数据
- 1、导入模块
import pandas as pd
- 2、加载 csv 文件
df = pd.read_csv(”googlestock.csv”)
df 的数据类型:pandas.core.frame.DataFrame`
- 3、将 df 修改为按时间戳索引,以便后续处理:
- 4、预处理
- 5、数据转换: 将 DataFrame 数据转换为适合进行进一步数学运算的矩阵数据
- 对矩阵数据进行规范化等预处理
- 进行线性回归分析
数据转换
- 将列表数据转换成np.数组矩阵, 并划分为数据和标签。
X = np.array (df.drop['label'],1)

Scikit-learn

- 用于数据预处理
from sklearn import preprocessing
// 零均值化 单位方差化
x= preprocessing.scale(X)
x.mean(axis=0)
x.std(axis=0)

- 数据特征降维PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.explained_variance_ratio_

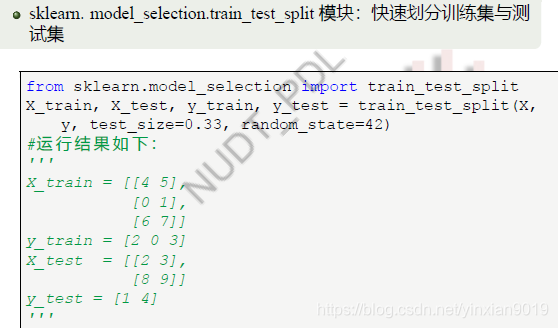
- sklearn.model_selection.train_test_split 模块:快速划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.33,random_state=42)
- sklearn.linear_model.LinearRegression 模块: 线性回归
-
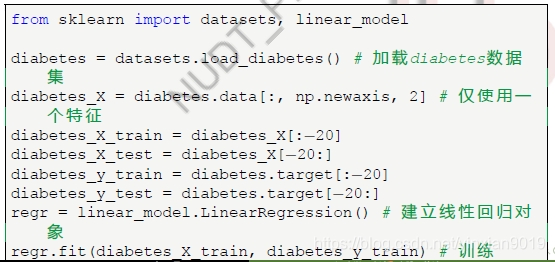
regr = linear_model.LinearRegression() # 建 立 线性 回 归 对象
regr.fit(diabetes_X_train, .diabetes_y_train)#训练
- 预处理
-

NumPy: python 科学计算的基础包
-
NumPy 数组的创建:向 array 中传入一个 list:
-
一维数组: np.array([1,2,3]) 二维数组: np.array([[1,2,3],[4,5,6]]) 随机数组: x = np.random.rand(10)
-
显示数组属性
a.shape , a. dtype
-
改变数组元素类型
a = a.astype('float64') -
改变数组尺寸
c = b.reshape(3, 4)
顺序调整。 -
将 reshape 的某个参数指定为-1 时,numpy 会根据实际数组元素个数自动替换-1 为具体的大小
c = b.reshape(-1, 4)
c = b.reshape(3, -1)
的结果将替换成与上条代码一致。 -
数组元素索引

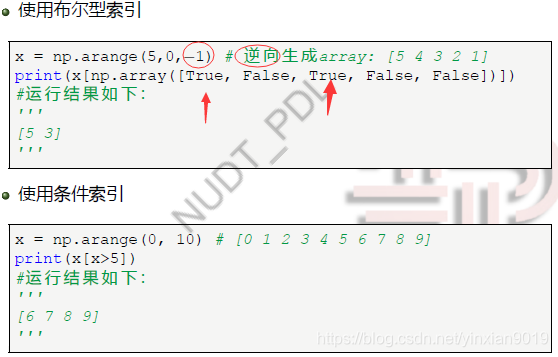
-
数组元素修改

-
多维数组索引切片
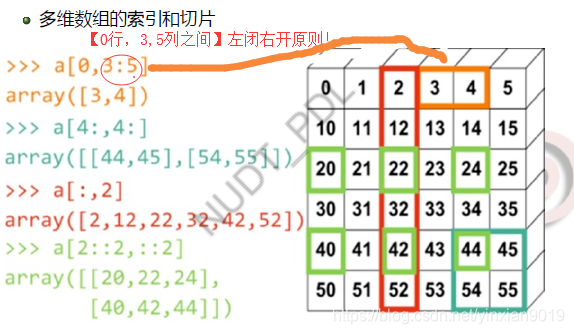
a[2: :2, ::2]冒号的第三个代表步长,空白代表直到行尾
-

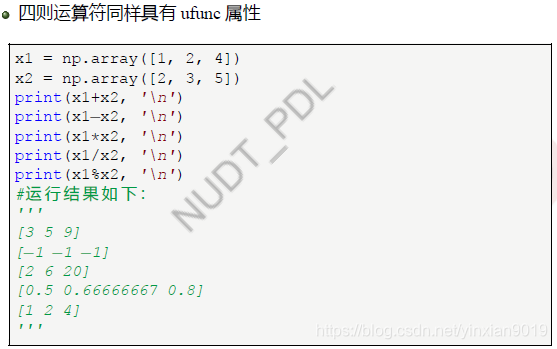
- ufunc操作
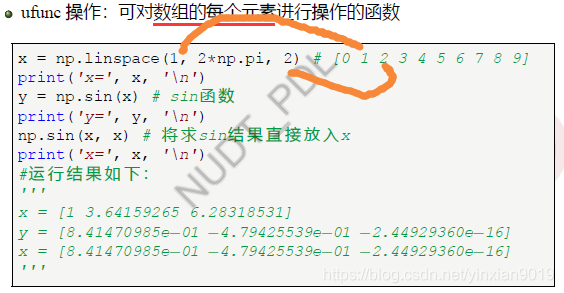
- 比较操作

- 矩阵乘法 对两个矩阵的形状有要求
np.dot(数组1,数组2)
- 文件存取

np.save ("a.npy",a)
c=np.load("a.npy")
np.savetxt("a.txt",a)
np.loadtxt(a.txt)
Matplotlib 数据可视化包
- matplotlib.image : 图像操作模块
- matplotlib.pyplpot:显示图像

- 数据可视化demo
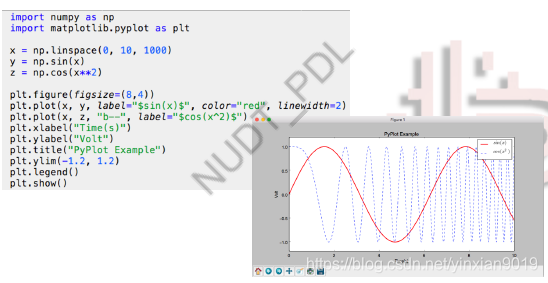

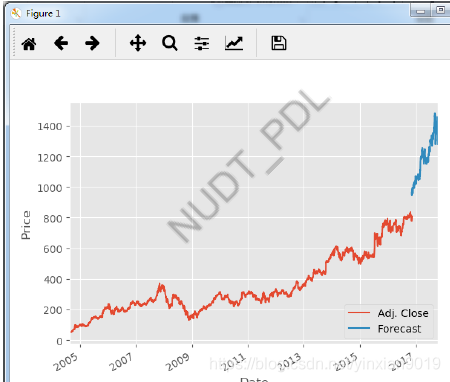
Scipy 库
- 通常作为matlab 与python 之间的桥梁。
- 加载mat文件
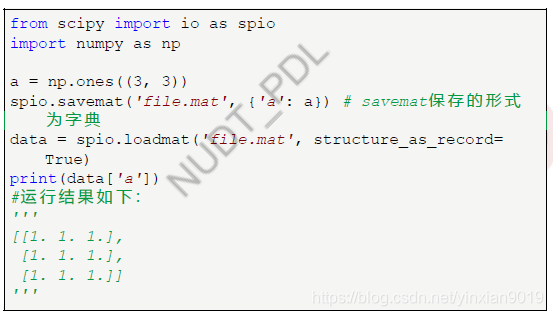

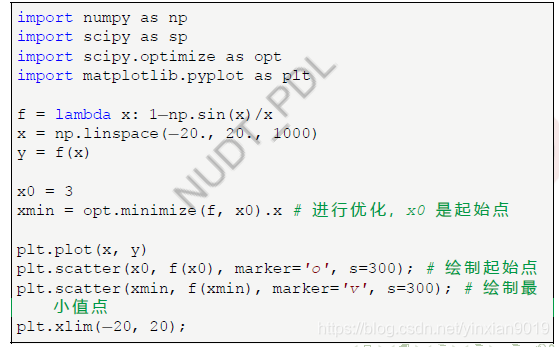
- 优化和拟合
Homework 1:
题目:
设计python程序,首先安装并导入opencv库:
例如:conda install opencv
import cv2
然后使用cv2.imread()读取任意彩色图片为numpy矩阵,然后进行以下操作:
(1) 将图片的三个通道顺序进行改变,由RGB变为BRG,并用imshow()或者matplotlib中的有关函数显示图片
(2) 利用Numpy给改变通道顺序的图片中指定位置打上红框,其中红框左上角和右下角坐标定义方式为:假设学号为12069028,则左上角坐标为(12, 06), 右下角坐标为(12+90, 06+28). (不可使用opencv中自带的画框工具)
(3) 利用cv2.imwrite()函数保存加上红框的图片。
进阶题目:
假设有函数y = cos(ax + b), 其中a为学号前两位,b为学号最后两位。首先从此函数中以相同步长(点与点之间在x轴上距离相同),在0<(ax+b)<2pi范围内,采样出2000个点,然后利用采样的2000个点作为特征点进行三次函数拟合。请提交拟合的三次函数以
1b024
及对应的图样(包括采样点及函数曲线)。
注意:基本作业为所有人必做。进阶作业选作,不计入总分。

相关文章推荐
- 《解析卷积神经网络—深度学习实践手册》学习笔记
- DeepLearning.ai笔记:(2-1)-- 深度学习的实践层面(Practical aspects of Deep Learning)
- 深度学习实践笔记(不断更新)
- “深度学习与实践” 笔记(二)
- 《21个项目玩转深度学习--基于tensorflow的实践详解》代码实现和笔记(一)
- TensorFlow深度学习笔记 逻辑回归 实践篇
- 深度学习实践笔记1——BP神经网
- TensorFlow 深度学习笔记 逻辑回归 实践篇
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-1)-- 深度学习的实践方面
- 深度学习笔记之使用Faster-Rcnn进行目标检测 (实践篇)
- TensorFlow深度学习笔记 循环神经网络实践
- 深度学习实践笔记2——分析BP
- 深度学习实践Tensorflow搭建卷积神经网络图像识别笔记
- 深度学习笔记之使用Faster-Rcnn进行目标检测 (实践篇)
- TensorFlow深度学习笔记 循环神经网络实践
- 深度学习笔记二:单层感知器学习与实践
- Google深度学习笔记 逻辑回归 实践篇
- [深度学习论文笔记][PAMI 17]A Comprehensive Study on Cross-View Gait Based Human Identification wit
- Deep Learning(深度学习)学习笔记整理系列之(八)
- Andrew NG 深度学习课程笔记:神经网络、有监督学习与深度学习