Kafka集群安装配置,kafka后台运行的方式,Kafka配置文件中的参数说明
2019-04-24 12:17
537 查看
首先给大家分享一个巨牛巨牛的人工智能教程,是我无意中发现的。教程不仅零基础,通俗易懂,而且非常风趣幽默,还时不时有内涵段子,像看小说一样,哈哈~我正在学习中,觉得太牛了,所以分享给大家!点这里可以跳转到教程
1、Kafka集群部署
1.1集群部署的基本流程
下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
1.2集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
关闭防火墙
chkconfig iptables off && setenforce 0
- 1
groupadd kafka && useradd kafka && usermod -a -G kafka kafka
- 1
mkdir -p /home/tuzq/software/kafkamkdir -p /home/tuzq/software/kafka/serverschmod 755 -R /home/tuzq/software/kafka
- 1
- 2
- 3
su kafka (本次实验,笔者使用root用户,即模拟在root下的安装。实际生产环境安装时请在指定用户下安装)
1.3 Kafka集群部署
1.3.1、下载安装包
http://kafka.apache.org/downloads.html
在linux中使用wget命令下载
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz
- 1
tar -zxvf /home/tuzq/software/kafka_2.11-0.9.0.1.tgz -C /home/tuzq/software/kafka/servers/cd /home/tuzq/software/kafka/servers/ln -s kafka_2.11-0.9.0.1 kafka
- 1
- 2
- 3
vim /etc/profile在文件的最底部写上:#set kafka envexport KAFKA_HOME=/home/tuzq/software/kafka/servers/kafkaexport PATH=$PATH:$KAFKA_HOME/bin
- 1
- 2
- 3
- 4
- 5
source /etc/profile
- 1
1.3.3、修改配置文件
[root@hadoop1 kafka]# cp /home/tuzq/software/kafka/servers/kafka/config/server.properties/home/tuzq/software/kafka/servers/kafka/config/server.properties.bak[root@hadoop1 kafka]# vim /home/tuzq/software/kafka/servers/kafka/config/server.properties
- 1
- 2
- 3
#broker的全局唯一编号,不能重复broker.id=0##用来监听链接的端口,producer或consumer将在此端口建立连接port=9092# 处理网络请求的线程数量num.network.threads=3# 用来处理磁盘IO的现成数量num.io.threads=8# 接受套接字的缓冲区大小socket.send.buffer.bytes=102400#接受套接字的缓冲区大小socket.receive.buffer.bytes=102400# 请求套接字的缓冲区的大小socket.request.max.bytes=104857600# kafka运行日志存放的路径log.dirs=/home/tuzq/software/kafka/servers/logs/kafka# topic在当前broker上的分片个数num.partitions=2# 用来恢复和清理data下数据的线程数量num.recovery.threads.per.data.dir=1# segment文件保留的最长时间,超时将被删除log.retention.hours=168#滚动生成新的segment文件的最大时间log.roll.hours=168# 日志文件中每个segment的大小,默认为1Glog.segment.bytes=1073741824# 周期性检查文件的时间,这里是300秒,即5分钟log.retention.check.interval.ms=300000##日志清理是否打开log.cleaner.enable=true#broker需要使用zookeeper保存meta数据zookeeper.connect=hadoop11:2181,hadoop12:2181,hadoop13:2181# zookeeper链接超时时间zookeeper.connection.timeout.ms=6000# partition buffer中,消息的条数达到阈值,将触发flush到磁盘log.flush.interval.messages=10000# 消息buffer的时间,达到阈值,将触发flush到磁盘log.flush.interval.ms=3000#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除delete.topic.enable=true#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092 unsuccessful 错误! (如果是hadoop2机器,下面配置成hadoop2)host.name=hadoop1#外网访问配置(如果是hadoop2的,下面是192.168.106.92)advertised.host.name=192.168.106.91
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 6 1d810 1
- 62
- 63
- 64
- 65
1.3.4、分发安装包
将包分发到hadoop2和hadoop3上[root@hadoop1 software]# pwd/home/tuzq/software[root@hadoop1 software]# scp -r kafka root@hadoop2:$PWD[root@hadoop1 software]# scp -r kafka root@hadoop3:$PWD
- 1
- 2
- 3
- 4
[root@hadoop2 software]# cd /home/tuzq/software/kafka/servers/[root@hadoop2 servers]# lskafka kafka_2.11-0.9.0.1[root@hadoop2 servers]# rm -rf kafka[root@hadoop2 servers]# ln -s kafka_2.11-0.9.0.1 kafka[root@hadoop2 servers]#
- 1
- 2
- 3
- 4
- 5
- 6
[root@hadoop3 servers]# cd /home/tuzq/software/kafka/servers/[root@hadoop3 servers]# lskafka kafka_2.11-0.9.0.1[root@hadoop3 servers]# rm -rf kafka[root@hadoop3 servers]# lskafka_2.11-0.9.0.1[root@hadoop3 servers]# ln -s kafka_2.11-0.9.0.1 kafka[root@hadoop3 servers]# lskafka kafka_2.11-0.9.0.1[root@hadoop3 servers]#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
vim /etc/profile在文件的最底部写上:#set kafka envexport KAFKA_HOME=/home/tuzq/software/kafka/servers/kafkaexport PATH=$PATH:$KAFKA_HOME/bin
- 1
- 2
- 3
- 4
- 5
source /etc/profile
- 1
1.3.5、再次修改配置文件(重要)
依次修改各服务器上配置文件的的broker.id,分别是0,1,2不得重复。1.3.6、启动集群(注意在三台服务器上都要执行下面的命令)
依次在各节点上启动kafka
cd $KAFKA_HOME
bin/kafka-server-start.sh config/server.properties
让kafka后台运行:
[root@hadoop1 kafka]# bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &[1] 9412[root@hadoop1 kafka]# jps4624 DataNode4241 DFSZKFailoverController9475 Jps9412 Kafka5093 NodeManager3981 JournalNode4974 ResourceManager4095 NameNode[root@hadoop1 kafka]#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
停止kafka的命令:
[root@hadoop1 kafka]# bin/kafka-server-stop.sh config/server.properties
- 1
kafka-broker配置文件
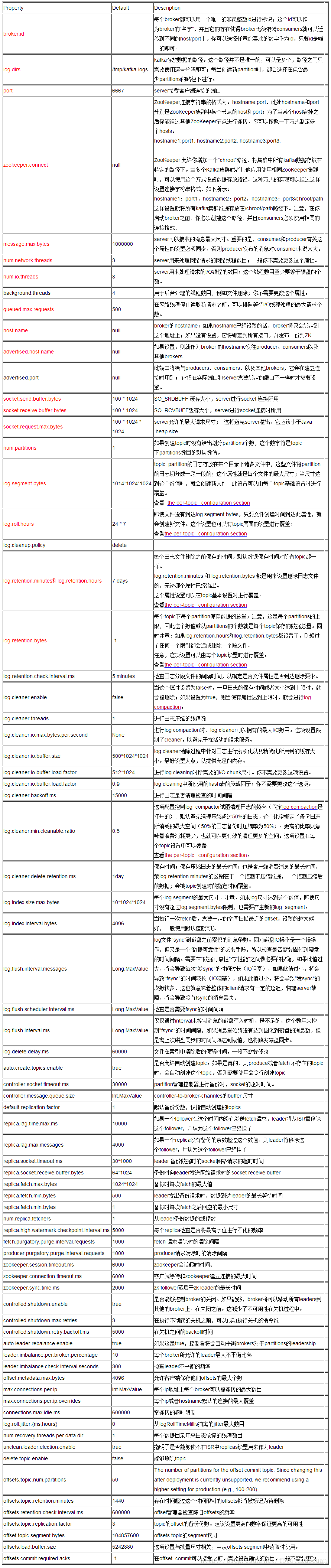
kafka-producer配置文件

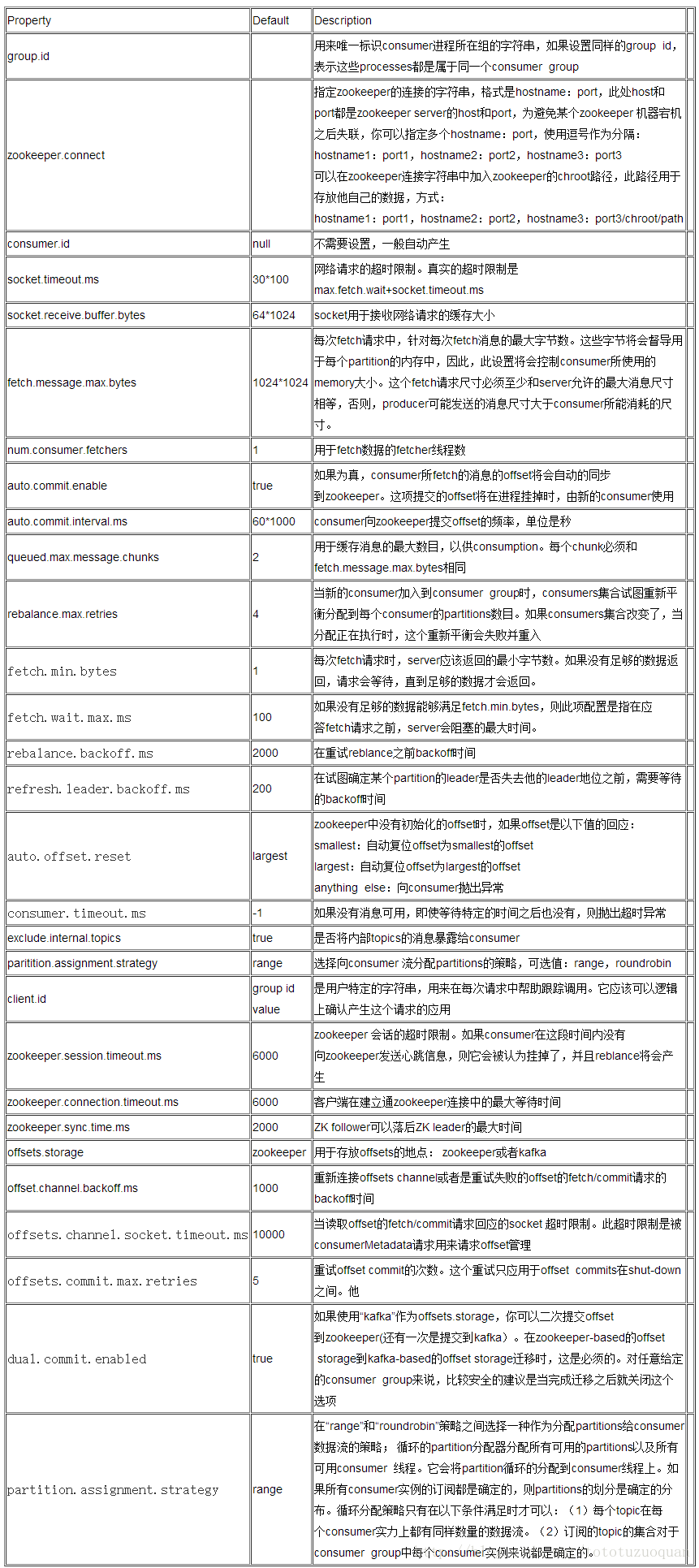
kafka-consumer配置文件

相关文章推荐
- Kafka集群安装配置,kafka后台运行的方式,Kafka配置文件中的参数说明
- kafka的集群安装及配置文件说明
- Kafka的安装和使用以及配置文件的说明
- Redis集群_5.redis.conf 配置文件参数说明
- nginx(Window下安装 & 配置文件参数说明 & 实例)
- kafka中server.properties配置文件参数说明
- Hadoop-2.8.0集群搭建、hadoop源码编译和安装、host配置、ssh免密登录、hadoop配置文件中的参数配置参数总结、hadoop集群测试,安装过程中的常见错误
- redis 主从配置实例、配置文件说明、及备份方式,php redis 扩展安装
- Redis(Windows安装方法与Java调用实例 & 配置文件参数说明 & Java使用Redis所用Jar包 & Redis与Memcached区别 & redis-cli.exe命令及示例)
- 集群管理——caffe多片gpu nccl配置,按照官方链接文档进行操作安装成功,需要提前将下文提到的3个文件下下来,make install方式不行
- Redis集群_6.Sentinel.conf 配置文件参数说明
- Zookeeper的安装部署,zookeeper参数配置说明,集群搭建,查看集群状态
- Hadoop1.x安装配置文件及参数说明
- 转:一次.NET Web应用程序安装包的制作经历:Sql数据库安装的3种方式 配置IIS及Web.Config文件
- CXF配置,ant文件说明及运行,运行cxf中带的项目
- iBatis 的配置文件中参数的说明
- 反射的应用,读取properties配置文件中的数据(普通InputStream方式,类加载方式),再调用运行
- ifcfg-ethx配置文件参数说明
- Hadoop配置文件参数说明
- 无盘集群的安装配置——内核切根文件系统篇