HashMap 1.8 部分源码解读
HashMap 1.8 相比于 1.7 及之前, 将集合的结构变为:数组+链表+红黑树。 引入红黑树自然是为了提高查询效率。这里摘录部分源码进行分析:
- 开头注释
- 几个类常量属性
- 构造方法
- put, hash, get, remove方法
- 为什么capacity为2的次幂
1. 开头注释部分
我觉得还是可以读一下的,这一部分大致总结了一下HashMap
/** * Hash table based implementation of the <tt>Map</tt> interface. This * implementation provides all of the optional map operations, and permits * <tt>null</tt> values and the <tt>null</tt> key. (The <tt>HashMap</tt> * class is roughly equivalent to <tt>Hashtable</tt>, except that it is * unsynchronized and permits nulls.) This class makes no guarantees as to * the order of the map; in particular, it does not guarantee that the order * will remain constant over time. *
这一段提出 HashMap 实现了 Map 接口,提供了所有可选择的map操作,
并且允许values(多个)值为null,允许存在一个为null的key,
其与Hashtable相似,差别于:
- HashMap可以存放null值,而Hashtable不行;
- 同时,HashMap非线程同步,即非线程安全的,而Hashtable是线程安全的。
* <p>This implementation provides constant-time performance for the basic * operations (<tt>get</tt> and <tt>put</tt>), assuming the hash function * disperses the elements properly among the buckets. Iteration over * collection views requires time proportional to the "capacity" of the * <tt>HashMap</tt> instance (the number of buckets) plus its size (the number * of key-value mappings). Thus, it's very important not to set the initial * capacity too high (or the load factor too low) if iteration performance is * important.
- 当hash方法可以使使元素均匀分布在buckets(我认为指的是数组中的每一个位置)中时,HashMap的get和put操作,是常量时间的(时间复杂度O(1))。
- 对于HashMap集合的遍历,需要的时间和buckets数量(数组大小,capacity)以及 键值对数量 之和 成比例。
- 因此,如果对遍历的性能很看重的话,最好不要将初始的capacity设置的过大(或者将负载因子设置的过小)
- 负载因子用于决定何时需要对数组扩容,默认值为0.75
<p>An instance of <tt>HashMap</tt> has two parameters that affect its * performance: <i>initial capacity</i> and <i>load factor</i>. The * <i>capacity</i> is the number of buckets in the hash table, and the initial * capacity is simply the capacity at the time the hash table is created. The * <i>load factor</i> is a measure of how full the hash table is allowed to * get before its capacity is automatically increased. When the number of * entries in the hash table exceeds the product of the load factor and the * current capacity, the hash table is <i>rehashed</i> (that is, internal data * structures are rebuilt) so that the hash table has approximately twice the * number of buckets.
- 影响HashMap性能的两个实例变量分别为:initial capacity(初始容量) 以及 load factor(负载因子)
- 初始容量是指hash表创建时的容量。负载因子是指:当hash表的使用程度为多少时,对其容量进行扩充。
- 当entries(键值对)数量超过 load factor * capacity 时,对hash表进行扩容,也就是rehashed,将其扩容至二倍。
<p>As a general rule, the default load factor (.75) offers a good * tradeoff between time and space costs. Higher values decrease the * space overhead but increase the lookup cost (reflected in most of * the operations of the <tt>HashMap</tt> class, including * <tt>get</tt> and <tt>put</tt>). The expected number of entries in * the map and its load factor should be taken into account when * setting its initial capacity, so as to minimize the number of * rehash operations. If the initial capacity is greater than the * maximum number of entries divided by the load factor, no rehash * operations will ever occur.
- load factor 设置为默认值0.75时对时间和空间消耗达到一个平衡。较大的load factor会减少空间消耗但是会增加查找消耗。
- 当设置初始capacity时需要考虑entries数量以及load factor,以最小化rehash操作的次数。
- 当 初始 capacity > entries数量/load factor,扩容就不会发生。
<p>If many mappings are to be stored in a <tt>HashMap</tt>
* instance, creating it with a sufficiently large capacity will allow
* the mappings to be stored more efficiently than letting it perform
* automatic rehashing as needed to grow the table. Note that using
* many keys with the same {@code hashCode()} is a sure way to slow
* down performance of any hash table. To ameliorate impact, when keys
* are {@link Comparable}, this class may use comparison order among
* keys to help break ties.
如果需要将很多键值对存进HashMap,建议创建一个capacity足够大的map,而不是让其通过rehash来扩容。
- 注意:使用很多具有相同hashCode值的keys必然会降低hash表的性能。当keys实现了Comparable接口时,可以使用keys之间的比较顺序来减小影响(这句不太明白)
/* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a hash map concurrently, and at least one of
* the threads modifies the map structurally, it <i>must</i> be
* synchronized externally. (A structural modification is any operation
* that adds or deletes one or more mappings; merely changing the value
* associated with a key that an instance already contains is not a
* structural modification.) This is typically accomplished by
* synchronizing on some object that naturally encapsulates the map.
*If no such object exists, the map should be "wrapped" using the
* {@link Collections#synchronizedMap Collections.synchronizedMap}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the map:<pre>
* Map m = Collections.synchronizedMap(new HashMap(...));</pre>*/
- HashMap是非线程同步的。若多个线程同时访问一个HashMap对象,且至少有一个线程修改了map结构(结构改变是指添加或删除一个或多个键值对,而不是仅仅改变了已经存在的key与value的关系),就必须要进行外部同步,一般通过对一些封装map的对象进行同步来实现(我认为就是使用一些线程安全之类的手段如Sychronized关键字之类的)
- 若没有这种对象存在,map应该使用Collections.sychronizedMap()方法进行包装。这一过程最好在创建时完成,以避免对map的突然非同步访问。使用示例:
Map m = Collections.synchronizedMap(new HashMap(…));
* <p>The iterators returned by all of this class's "collection view methods"
* are <i>fail-fast</i>: if the map is structurally modified at any time after
* the iterator is created, in any way except through the iterator's own
* <tt>remove</tt> method, the iterator will throw a
* {@link ConcurrentModificationException}. Thus, i
4000
n the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than risking
* arbitrary, non-deterministic behavior at an undetermined time in the
* future.
HashMap的迭代器是具有 fail-fast 特性的:若迭代器创建后的任意时刻,map结构被修改,除了迭代器自身的remove方法, 均会抛出ConcurrentModificationException异常。因此,在面临并发修改时,iterator会立马失败,以避免冒任何风险。
<p>Note that the fail-fast behavior of an iterator cannot be guaranteed * as it is, generally speaking, impossible to make any hard guarantees in the * presence of unsynchronized concurrent modification. Fail-fast iterators * throw <tt>ConcurrentModificationException</tt> on a best-effort basis. * Therefore, it would be wrong to write a program that depended on this * exception for its correctness: <i>the fail-fast behavior of iterators * should be used only to detect bugs.</i>
- 注:iterator的fail-fast 行为是不能被保证的,因为,通常,在发生非同步并发修改时做出任何硬性保障是不可能的。Fail-fast 迭代器只能尽最大的努力抛出ConcurrentModificationException异常。
- 因此,依赖该异常编写程序确定其正确性是不对的:fail-fast行为应被用于检测bugs。
下面开始代码部分
2. 几个类常量属性:

DEFAULT_INITIAL_CAPACITY: 默认初始容量,值为2的4次方,必须为2的幂次方(最后解释)。
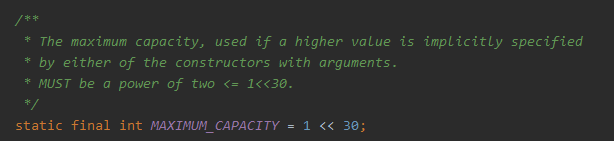
MAXIMUM_CAPACITY: 最大容量, 2的30次方,同时也要求是2的次幂。
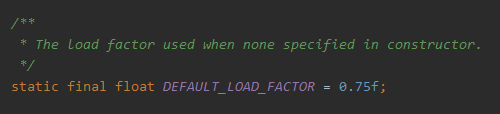
DEFAULT_LOAD_FACTOR:默认负载因子,为0.75

TREEIFY_THRESHOLD:将链表转化为树的阈值,当链表的长度达到8时转换为红黑树。
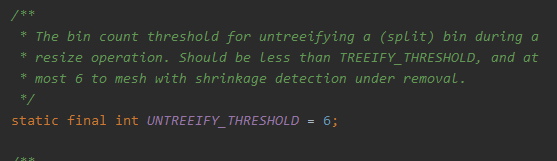
UNTREEIFY_THRESHOLD:当树中节点数小于等于6时,将其转换为链表。(之前看到有人说这个和TREEIFY_THRESHOLD之间差2的原因是:防止树形化和链表化的操作太频繁,我觉有点道理)
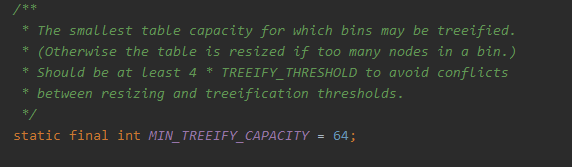
MIN_TREEIFY_CAPACITY:capacity 大于等于 这个值(64)时,才可以进行树形化,小于该值时,可能出现一个bucket 里的节点过多,此时应该将capacity重新设置,而不是进行树形化。
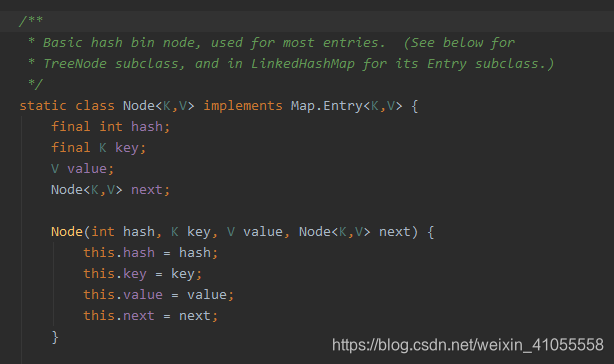
一个静态内部类,用于链表及红黑树。
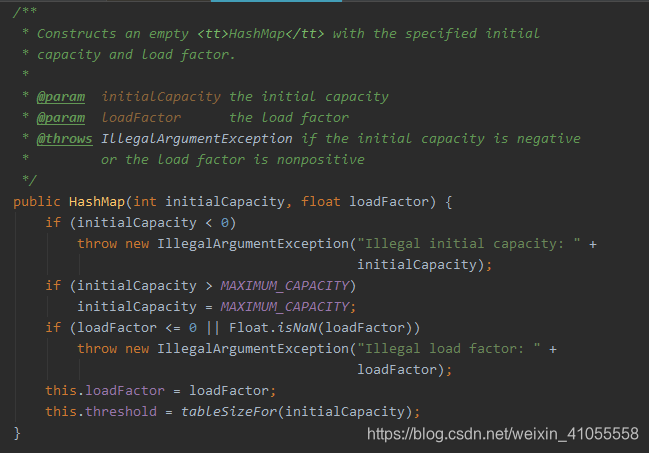
3. HashMap的构造方法:有4个
- 含有初始容量initialCapacity和负载因子loadFactor两个参数的构造方法,这里就不解释代码了
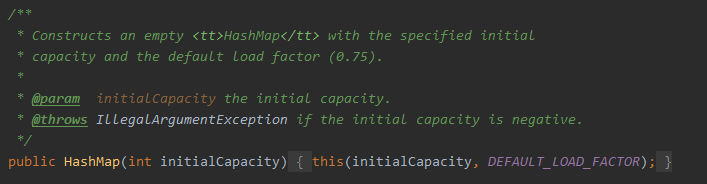
- 只有初始容量一个参数的构造方法,这里调用了上一个构造方法,负载因子设置为默认值0.75
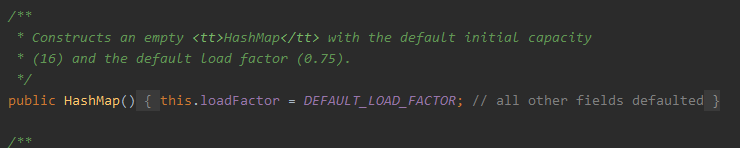
- 无参构造方法(常用)
- 含有一个Map类型参数的构造方法,将一个map复制给新的hash map。
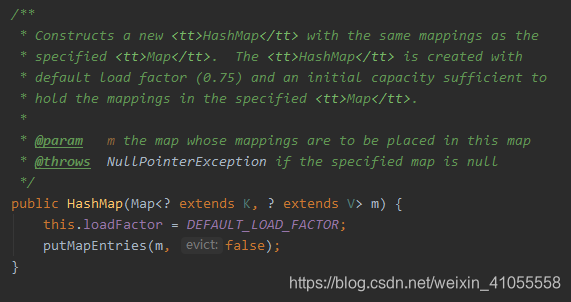
4. put, hash, get, remove 方法 - put()方法:向HashMap对象中添加键值对,可以看到其调用了hash()方法计算key的hash值,并调用了putVal()方法。
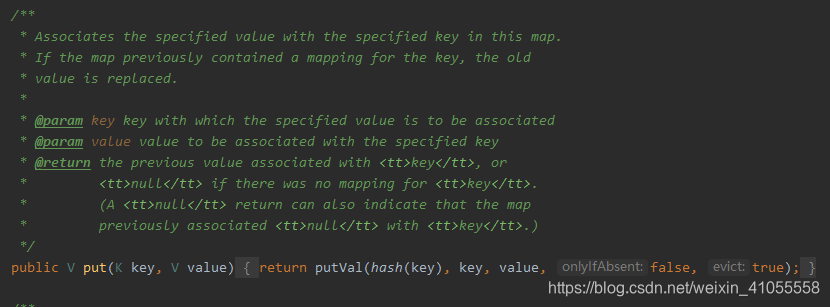

- hash()方法,将key.hashCode()结果的高16位及低16为进行了异或。
注释中给出了原因,最后使用hash值确定该key的key-value对应的数组位置时,会使用 hash&(n-1)。 如果直接使用两个key的hashCode()进行操作,很容易发生hash冲突,将高低位异或会减少这种事情的发生。
如:假设两个key: key1,key2
,其hashCode()值如下
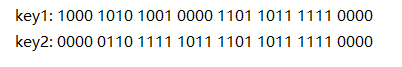
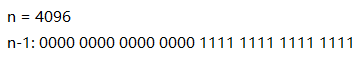
虽然key1 != kye2
, 但是key1& (n-1) == key2 & (n-1)


但是hash操作后:hash(key1)
变为:

hash(key2)
:

hash(key1) & (n-1)
:

hash(key2) & (n-1)
:

明显结果不同了,这样就减少了hash冲突。
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
put大致步骤如下:
首先需要确保数组是存在的 之后,确定数组索引hash & (n-1)位置上是否为null,即判断是否要放入的key的位置上有hash冲突。 若数组该位置为空,生成一个含有key-value信息的Node,放入数组该位置。 不为空: 若该头节点key与要插入的key相同,则不用新生成Node,直接对该节点进行修改即可 若不同: 若头节点为树节点,则调用putTreeVal方法进行操作 若头节点为链表节点,遍历链表; 若链表中无该key,则生成一个Node 若有,直接对该节点进行修改即可 完成上述操作后: ++modCount(修改次数) 同时需要判断是否需要扩容。
- get方法:
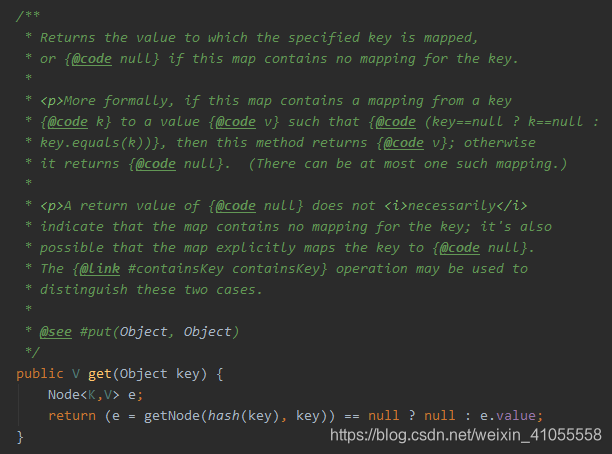
其调用getNode()
方法:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
get 方法大致步骤:
需要确定数组存在,不为空且key对应的索引位中不为空 若数组中的头节点Node的key与key相同,直接返回该节点即可 头节点key与key不同: 若头节点为树节点,则调用getTreeNode方法,在树中查询 头节点为链表节点,遍历链表,存在key的节点则返回该节点 完成上述操作,若没有key的节点,则返回null.
- remove 方法
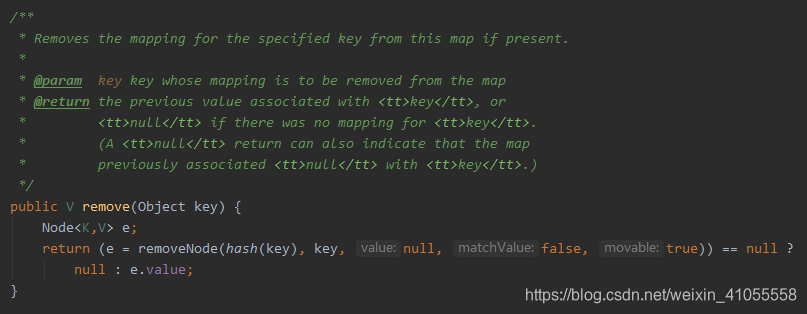
调用了removeNode方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
removeNode方法步骤:
确定数组存在不为空且(hash & n-1)处有Node: 首先要找到key的节点: 若头节点key为key:node = p 否则: 若头节点为树节点:调用getTreeNode方法 头节点为链表节点:遍历链表找key的Node 找到节点,若matchValue为true需要确定value值也相同(但是matchValue默认值为false,因此这里不用考虑value值) 若节点为树节点:调用removeTreeNode方法 为头节点:删除头节点 为链表节点:删除该节点
最后说一下为什么capacity,即数组容量为2的次幂?
原因很简单:保证hash & (capacity-1)可以落在 0~capacity-1上。

- jdk 1.8 hashmap源码解读(详细)(上)
- HashMap源码解读(JDK1.8)
- JDK1.8源码(三)——java.util.HashMap
- HashMap源码解读
- (转载)Java中HashMap底层实现原理(JDK1.8)源码分析
- HashMap源码解读
- Java HashMap 核心源码解读
- jdk1.8 HashMap源码分析(put函数)
- 源码分析系列1:HashMap源码分析(基于JDK1.8)
- WeakHashMap源码探讨(基于JDK1.8)
- 学习JDK1.8集合源码之--HashMap
- HashMap 源码详细分析(JDK1.8)
- JDK源码之解读hashMap 的put和get方法的实现原理
- Java拾遗:002 - HashMap源码解读
- HashMap源码解读
- (JDK1.8)HashMap源码分析之常量
- HashMap源码分析(基于JDK1.8)
- Java源码分析:关于 HashMap 1.8 的重大更新
- HashMap源码解析(JDK1.8)