总结陈丹琦博士论文(一):NEURAL READING COMPREHENSION AND BEYOND
陈丹琦博士论文阅读笔记第一部分
第一章:简介
1.1 motivation
1.2 thesis outline
1.3 contributions
1.1 motivation
通过一篇简短的故事短文介绍了机器学习在阅读理解中需要做的事情和阅读理解对于评价一个模型有效性的地位。
(1) part of speech tagging 词性标注
(2) named entity recognition 命名实体识别
(3) syntactic parsing 句法分析
(4) coreference resolution 指代消除
最后指出研究的两个主要内容:
open-domain question answering
开放性问题回答
conversational question answering
对话问答
1.2 thesis outline
介绍了全文的写作安排,两大部分内容,并对每一章的内容进行介绍
神经阅读理解:基础
第二章:历史回顾和发展现状,阅读理解和一般问答题目的区别和定义。
第三章:从基于特征的分类器到基于神经网络的阅读理解模型进行介绍,讲解了作者在2016和2017年做的工作
第四章:探讨未来的工作和现存的一些重要问题。
神经阅读理解:应用
第五章:开放性问题回答应用。介绍了如何将高性能阅读理解系统和信息挖掘技术结合建立一个open-domain question answering systems,命名这个系统为DRQA。
第六章:对话系统,理解一段文本并且能够回答一系列出现在文本中的问题。介绍CoQA(Conversational QuestionAnswering systems),
第七章:总结全文
1.3 Contributions
- 首次在神经阅读理解进行研究,并且提出广为人知的STANFORD ATTENTIVE READER 模型
- 挖掘深层次神经阅读理解学到的内容,理解神经模型和现有基于特征模型的差异。
- 提出DRQA系统
- 提出CoQA系统
神经阅读理解:基础
第二章:神经阅读理解的回顾
2.1 历史
首先列举从上世纪70年代到如今的基于特征的阅读理解模型的发展,以及存在的一些数据集,然后从2015年作为转折点,描述了深度学习下的阅读理解模型以及提出的新数据集(如THE STANFORD QUESTION ANSWERING DATASET (SQUAD)),并且指出端到端的深度模型的优越性能。SQUAD数据集又不够复杂,后续又出现很多其他的数据集,如TRIVIAQA (Joshi et al., 2017), RACE (Lai et al., 2017), QANGAROO (Welbl et al., 2018), NARRATIVEQA (Kocisk ˇ y et al. ` , 2018), MULTIRC (Khashabi et al.,2018), SQuAD 2.0 (Rajpurkar et al., 2018), HOTPOTQA (Yang et al., 2018) 等。
2.2 定义任务
四种文体形式和评价标准
完型风格(cloze style):accuracy
多项选择(multiple choice):accuracy
跨度预测(span prediction)(抽取式问答):Exact Match、F1Score
自由回答(free-form answer):No Consensus(BLEU,Meteor,ROUGE)
2.3 阅读理解 vs. 问答
有区别有联系
问答:
要有足够多的资源去理解去回答。
如何去找到并且识别出相关的资源,如何从不同的碎片资源中整合出答案,研究人们经常问哪些问题
阅读理解:
要求对于一段文字要足够的理解,而不要求对于段落外的其他知识。
2.4 数据集和模型
阅读理解的成功归结于两点:large-scale reading comprehension datasets(大规模的数据集) and end-toend neural reading comprehension models(端到端的深度模型)

第三章 神经阅读理解模型
在3.1介绍基于特征的模型,是根据作者在16年的一篇文章展开,这也使得我们可以更好地比较两种方法的差异。在3.2在SQUAD数据集上进行基于神经网络的模型介绍,从基本模块构建到顶层设计详细阐述。在3.3,对比更多数据集进行神经方法优化,并且对误差进行分析总结:包括哪些因素对模型性能有很大的影响,以及基于特征的模型和神经模型的对比。在3.4对最新的神经阅读理解做一个总结。
3.1 先前工作:基于特征的模型
基于特征的模型主要是找到一个特征向量,然后用常规的机器学习分类算法进行分析,但是寻找这个向量依旧是一个艰难的过程。作者在表格中列举了所找的特征:

3.2 A Neural Approach: The Stanford Attentive Reader(一种神经网络方法)
3.2.1 预备阶段
首先需要用低维向量表示单词。
词嵌入方法:
WORD2VEC (Mikolov et al., 2013),
GLOVE (Pennington et al., 2014)
FASTTEXT (Bojanowski et al., 2017)
Recurrent neural networks
RNN:RNN,LSTM,GRU,常用双向RNN
Attention mechanism
一般的RNN都是采取最后一刻hnh_nhn来预测,但是注意力机制将h1,...hnh_1,...h_nh1
24000
,...hn都用来进行预测。具体的形式:

3.2.2 The model
首先是整个模型的图:

问题编码:
词嵌入+注意力机制(BiLSTM)
段落编码:
(词嵌入+三个手工特征+ExactMatch特征+aligh特征)+注意力机制(BiLSTM)
跨度答案预测:
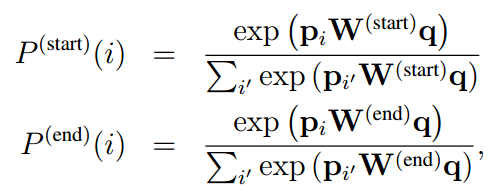
最小化交叉熵:
L=−∑logP(start)(astart)−∑logP(end)(aend)L=-\sum logP^{(start)}(a_{start})-\sum logP^{(end)}(a_{end})L=−∑logP(start)(astart)−∑logP(end)(aend)
Cloze style预测
αi=exp(piWq)∑i′exp(pi′Wq)\alpha_i=\frac{exp(p_iWq)}{\sum_{i'} exp(p_{i'}Wq)}αi=∑i′exp(pi′Wq)exp(piWq)
o=∑αipio=\sum \alpha_ip_io=∑αipi
输出o可以用来预测缺失主体
P(Y=e∣p,q)=exp(We(a)o)∑e′∈ϵexp(We′(a)o)P(Y=e|p,q)=\frac{exp(W_e^{(a)}o)}{\sum_{e'\in \epsilon}exp(W_{e'}^{(a)}o)}P(Y=e∣p,q)=∑e′∈ϵexp(We′(a)o)exp(We(a)o)
multiple choice
P(Y=i∣p,q)=exp(aiWe(a)o)∑i′=1,...,kexp(ai′We′(a)o)P(Y=i|p,q)=\frac{exp(a_iW_e^{(a)}o)}{\sum_{i'=1,...,k}exp(a_{i'}W_{e'}^{(a)}o)}P(Y=i∣p,q)=∑i′=1,...,kexp(ai′We′(a)o)exp(aiWe(a)o)
Free-form answer
多加一个LSTM的序列预测:
P(a∣p,q)=P(a∣o)=∏j=1laP(aj∣a<j,o)P(a|p,q)=P(a|o)=\prod_{j=1}^{l_a}P(a_j|a_{<j},o)P(a∣p,q)=P(a∣o)=j=1∏laP(aj∣a<j,o)
L=−logP(a∣p,q)=−log∑j=1laP(aj∣a<j,o)L=-logP(a|p,q)=-log\sum_{j=1}^{l_a}P(a_j|a_{<j},o)L=−logP(a∣p,q)=−logj=1∑laP(aj∣a<j,o)
一次预测出一个单词,直到结尾字符预测出来。
3.3 实验
在CNN/DAILY MAIL和 SQUAD阅读理解数据集上评估模型。
其中的一些实验细节:
stacked BiLSTMs
Dropout
Handling word embeddings
Model specifications
实验结果的分类以及一些baselines:
CNN/DAILY MAIL

SQUAD

然后做了一些消除某些特征带来影响的实验:

总结分析模型学习到了什么?
Exact match:准确匹配
Sentence-level paraphrasing:文本中蕴含有问题
Partial clue :碎片信息推出答案
Multiple sentences:多个句子推导出正确答案
Coreference errors :指代错误
Ambiguous or hard:模糊不清

3.4 最新研究进展
从四个方面进行讲述:
3.4.1 word representions
首先说明FASTTEXT\color{blue}FASTTEXTFASTTEXT相比GLOVE\color{blue}GLOVEGLOVE词嵌入给模型带来了提升。但是现在的另外两个方法也有很大的优点:
Characterembeddings\color{blue}Character embeddingsCharacterembeddings
用字符级别的嵌入方式来表征单词,然后现在常用的是将每个单词用一串字符向量表示,然后用卷积神经网络和滤波器对一串字符向量卷积,

再用最大池化:f=maxi{fi}f=max_i\left\{f_i\right\}f=maxi{fi}
可以采用多个的滤波器得到每个单词的表征Ec(x)E_c(x)Ec(x)
Contextualizedwordembeddings(ELMo)\color{blue}Contextualized word embeddings(ELMo)Contextualizedwordembeddings(ELMo)
不像传统的词嵌入方法是一个单词类型映射一个向量,这种新的方式将单词的向量表示为整个句子的函数,这样的表示会更好的表达单词意思(一是词语用法在语义和语法上的复杂特点;二是随着语言环境的改变,这些用法也应该随之改变)
给定一系列单词 (x1,x2,...,xn)(x_1, x_2,...,x_n)(x1,x2,...,xn),运行一个L层的前向LSTM建立序列的模型概率:
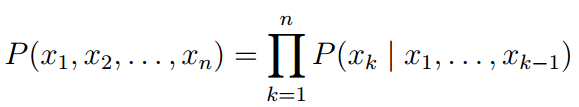
只有顶层的LSTM h→k(L)\overrightarrow{h}_k^{(L)}hk(L)用来预测下一个表征xk+1x_{k+1}xk+1,同样的另一个L层的LSTM 反向建立序列并且 h←k(L)\overleftarrow{h}_k^{(L)}hk(L)用来预测得到下一个表征xk−1x_{k-1}xk−1整个的训练目标就是最大化似然函数:
在这里插入图片描述
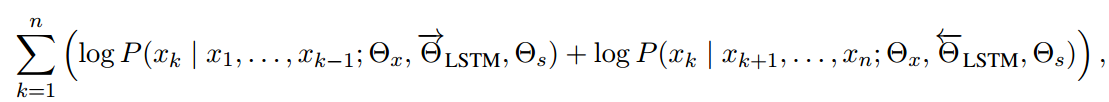
最后的上下文词向量嵌入通过一个线性结合所有的BiLSTm层还有输入的词向量,乘上一个γ\gammaγ
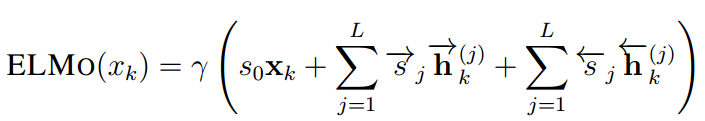
随后的有很多上下文嵌入词向量的模型和发现,包括有人发现这种方法不仅仅在阅读理解中有很大的模型提升,并且在很多的语言模型中还有很大的潜力和研究价值
3.4.2 Attention Mechanisms
首先一张表格简单说明注意力机制的研究情况:

Bidirectional attention
与作者在17年文章中的注意力机制提取特征用法相类似,只不过作者的是passage-to-question attention,与他们的方向是不同的。
Self-attention over passage
自注意力机制,用文中的公式一目了然:

3.4.3 Alternatives to LSTMs
RNN不能很好的解决长时间记忆问题,LSTM的提出很好的解决了这个问题。但是,LSTM:很难优化,因为存在的梯度消失问题;并且可扩展性差,训练慢,无法进行深度层次的训练。最引人注目的是谷歌的 TRANSFORMER\color{blue}TRANSFORMERTRANSFORMER模型,运用残差网络和注意力机制可以训练的更快。QANET\color{blue}QANETQANET (Yu et al., 2018) model采用多层卷积,自注意力机制和全连接层取得了好的性能。以及改进的SIMPLE RECURRENT UNITSRU\color{blue}SRUSRULei et al. (2018) ,简化了循环却保持了模型的能力。
3.4.4 others
主要是数据增强,这在机器学习和深度学习中是一种常用的方式,而且一般都会对模型带来性能的提升
下边是上述一些方法带来提升的比较:

第四章:The Future of Reading Comprehension(未来的发展趋势)
首先在之前的章节中已经描述了神经阅读理解模型在阅读理解问题中的成功应用以及他们的一些关键点。尽管已经有了很大的进步,但是距离人工阅读理解还是存在有一定的差距。
在4.1主要是提出一些现存模型预测错误的例子,说明这些模型虽然能够在一般的应用上取得高性能,但是却仍然在很多简单的的小问题上出现预测错误;在4.2和4.3分别讲述数据集和模型对于阅读理解问题的影响和存在的不足以及需要深入研究的方向;在4.4回顾本领域几个重要的研究问题。
4.1 Is SQuAD Solved Yet?
通过一些例子说明这些模型存在问题,会犯一些人们基本不会犯的错误,并且推测是这些模型仍然缺乏对文本主体和事件之间的内在结构的理解。
Jia and Liang (2017)等在文本末尾添加一些分散注意力的句子或者一些存在语法问题的句子会导致模型性能骤降。这说明目前的模型严重依赖于文章和问题之间的词汇线索,并且,模型对于对抗性样本存在鲁棒性差等缺点。
总的来说,尽管现在的模型在如SQUAD数据集上有了很高的性能,但是这些模型依旧停留在对文本浅层次结构信息的理解上,在对于深层次结构的理解上还是会犯很多简单的错误。在下边的章节上会从建立更全面的数据集和更有效的模型进行描述。
4.2 Future Work: Datasets
SQUAD存在的问题:
- 问答的问题是根据一段文章提出的,两者存在很多重叠的单词
- 问答的问题是文本短距离的跨度预测
- 大部分的问答问题都是通过单个句子来预测,基本不需要多段文字推理
后边陆陆续续又提出了很多更具挑战性的数据集:
TriviaQA (Joshi et al., 2017).这个数据集的关键思想是先收集问题/答案对,然后构建相应的段落
RACE (Lai et al., 2017). 用人类的标准化测试评估机器阅读理解能力,专家设定问题和答案。
NarrativeQA (Kocisk ˇ y et al. ` , 2018)根据书或电影的情节摘要进行提问回答。这个数据集由于答案缺乏一致性,很难评估
SQuAD 2.0 (Rajpurkar et al., 2018)增加了很多负样本例子
HotpotQA (Yang et al., 2018).这个数据集构造的问答问题需要分析多个支持文档来回答
4.3 Future Work: Models
现在的工作基本就是将数据集分为训练/验证集/测试集,然后目标就是使测试集的准确率越来越高。但是除此之外还有很多其他的重要因素被忽略了:
4.3.1 Desiderata
除了准确率,还有很多其他性能需要考虑:
· Speed and Scalability.
如用SRU (Lei et al., 2018)或者TRANSFER(Vaswani
et al., 2017)替换LSTMs
训练能够自动跳过无关文本的模型Yu et al. (2017) and Seo et al.
(2018).
选择多GPU或高性能硬件。 Coleman et al. (2017)
· Robustness.
在训练过程添加更多的对抗样本
在多数据集上做迁移学习和多任务学习
打破标准的监督学习方法,为提高鲁棒性考虑创造更好的模型评价方法
· Interpretability.
最简单的方法是要求模型学会从文档中提取文档的片段作为预测证据
更复杂的方法是,这些模型可以生成理论依据。
最后,需要考虑的另一个重要方面是,我们要用什么样的训练集来达到这种级别的可解释性
4.3.2 Structures and Modules
结构信息将有很大的作用:

那么需要注意的是:如何将这些结构信息加入到序列模型?用现成的语言工具包还是建立结构模型作为一个隐变量?
另外一个现存模型的缺失是模块化,阅读理解是很复杂多样的,需要各种各样的推理能力。这种模块化的思想是(Andreas et al., 2016) 提出NEURAL MODULE NETWORKS (NMN)。但是这种做法目前是在视觉问答领域或者小的数据集问答问题中进行研究,对于大规模语料阅读理解问题还面临巨大的挑战。
4.4 Research Questions
在最后一节中,我们讨论了这一领域的几个中心研究问题,这些问题仍然是开放的问题,有待于未来的回答
4.4.1 How to Measure Progress?
一方面,我们认为用人类的标准化测试来评价机器阅读理解系统性能是一个很好的策略。另一方面,我们认为最好将许多阅读理解数据集集成为一个测试集,以便在将来进行评估,而不是仅仅对单个数据集进行测试。更重要的是,我们需要更好地理解现有的数据集。
Sugawara et al. (2017)提出将阅读理解技能划分为prerequisite skills 和 readability
prerequisite skills:object tracking, mathematical reasoning, coreference resolution, logical reasoning, analogy,causal relation, spatiotemporal relation, ellipsis, bridging, elaboration, meta-knowledge,schematic clause relation and punctuation.(目标跟踪,数学推理,共指消解,逻辑推理,类比,因果关系,时空关系,省略,桥接,详细阐述,元知识,原理关系示意和标点符号。)
readability:文本的易处理性,语言特征和人类可读性测量。
4.4.2 Representations vs. Architecture: Which is More Important?

上述图中,左边的模型是:只是用无标签文本预训练得到顶层的词嵌入向量,其他参数从有限的训练数据集中学习。第二类模型非常简单,将问题和一段文本整合为一个序列,整个模型的参数通过预训练得到,后续其他参数只需要根据训练集进行微调即可。


4.4.3 How Many Training Examples Are Needed?
一方面,数据集越大越有帮助,另一方面,预训练模型(Radford et al., 2018; Devlin et al.,2018) 可以帮助我们减少对于大规模数据集的依赖性。未来希望在无监督学习和迁移学习上进行更多的研究。

- 【一起读ACL论文】Attention-over-Attention Neural Networks for Reading Comprehension
- 论文《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》总结
- Attention-over-Attention Neural Networks for Reading Comprehension论文笔记
- RNN资源博客 Recurrent Neural Network的经典论文、代码、课件、博士论文和应用汇总
- #Paper Reading# Lifelong Machine Learning for Topic Modeling and Beyond
- Feed Forward and Backward Run in Deep Convolution Neural Network 论文阅读笔记
- Neural Architecture Search with Reinforcement Learning论文总结
- 论文《Convolutional Neural Networks for Sentence Classification》总结
- 【论文阅读】Neural Machine Translation By Jointly Learning To Align and Translate
- Neural Networks and Deep Learning总结
- 论文笔记《A Survey of Model Compression and Acceleration for Deep Neural Networks》
- 论文《Inside-Outside Net: Detecting Objects in Context with skip pooling and Recurrent Neural Networks》
- RNN资源博客 Recurrent Neural Network的经典论文、代码、课件、博士论文和应用汇总
- 论文阅读 | An Artificial Neural Network-based Stock Trading System Using Technical Analysis and Big Data
- 论文阅读:Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H
- 论文笔记之Label-Free Supervision of Neural Networks with Physics and Domain Knowledge
- NMT十篇必读论文(四)Neural Machine Translation by Jointly Learning to Align and Translate
- 论文记录-Deep Compression:Compressing DeepNeural Networks With Pruning, Trained Quantization And Huffman