论文阅读:Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks
2017-12-05 22:40
567 查看
本文主要内容为论文《Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks》的学习笔记,内容和图片主要参考 该论文 。在这里我主要记录下自己觉得重要的内容以及一些相关的想法,希望能与大家多多交流~
在本文中我们将展示在大规模标记的数据上用CNN学习出的图像表示是如何有效地被迁移到其他视觉识别的任务中。我们设计了一种方法以至于能重新使用在Image net数据集上训练的层来计算PASCAL VOC数据集上图片的中层图像特征。我们的研究表明即使在两个数据集上图像的统计特征和任务是不同的,但是迁移学习显著提高了物体和动作的分类结果,优于目前在Pascal VOC 2007 and 2012数据集上最先进的结果。我们也展示了结果有希望能够实现目标和动作的定位。
卷积神经网络(CNN)是有着大量参数的大容量分类器,所以必须从训练样本学习。虽然CNN已经被称为在其他的视觉任务(包括通用对象识别中)效果超过超过特征识别,但是首先于标准目标识别数据集的相对较小的规模。
值得注意的是,许多成功的图像分类器使用了新认知机和卷积神经网络。量化及空间聚集局部描述子与这些通过前两层新认知机计算得到的相比较是浅层特征。所以浅层特征比早期的CNN要好,可能是因为CNN很难在较小的数据集上进行训练。然而大规模数据集的出现和GPU的出现使得CNN得到了跳跃性的发展(performance leap)和更大的进步(further improve)。
有人认为不同的计算机视觉数据集在图像统计特征上有显著的差异,如视角、背景信息,场景信息和其他因子。鉴于CNN“data hungry”的特点,如何使用有限的数据训练CNN是一个重要的问题。
到目前为止,文章所提出的问题主要有这几个。首先CNN的学习需要建立数以百万计的参数,并且需要大量已经标注好的图像;如果数据的数量不够将使得模型过拟合,效果变差,并且很有可能效果要差于传统的手工特征;其次不同的计算机视觉数据集在图像统计特征上有显著的差异,那我们在将来的每一个新的视觉识别任务中是否都需要收集一个百万级的图片数据集。归结起来就是,CNN在处理原始任务的时候需要大量的标注数据才能训练,如果新任务(可能与原始任务相同,比如说都是分类任务;也有可能与原始任务不同,一个分类一个识别)所具有的数据集与原始的数据集在统计上有显著的不同,并且数据量较小,这个时候应该如何使用CNN来完成新任务。
为了解决这个问题,我们提出了一种把在大规模数据集上CNN学习到的图像表示迁移到其他的有限训练集的视觉识别问题上。具体来讲,我们提出一种使用在Image net上训练的CNN的层来有效率地计算Pascal VOC图片集图像的中层表示。实验效果(物体及动作分类)的效果很好。结果表明迁移学习可能用于物体和动作的定位。
在迁移学习方面,以往的工作都是在标准的图像特征上进行训练,而本文提出的方法直接在源空间进行训练。有的方法与我们的十分相似,采用无监督伪任务训练CNN,但是我们采用在大规模有监督任务上训练CNN的卷积层并且解决了图像中物体尺寸和位置变换的问题。有些人与本文的研究方法相似,但是处理的问题是不同的。
在视觉目标分类方面,之前常用的方法有词包模型、密集SIFT、K均值等各种各样的方法。但是这些方法都无法表明他们是最好的方法,所以也就引起了人们对于中层特征和一半特征学习的兴趣。而我们的工作表明卷积层能够产生通用的中层图像表示,以至于它们能够迁移到新任务上。
在深度学习方面,最近兴起的多层神经网络的兴趣是有越老越多的学习中间表示的工作触发的,或者使用无监督的方法,或者使用更多的传统的监督学习的技术。
针对这个挑战我们设计一种结构,这种结构能够显著地重新绘制原任务与目标任务之间类的标签(见3.1部分)。其次,受滑动窗口检测可以明显地处理目标尺寸分布不同的问题的启发,发展训练和测试过程,针对在原任务和目标任务中的定位和背景混乱问题(见3.2和3.3)。
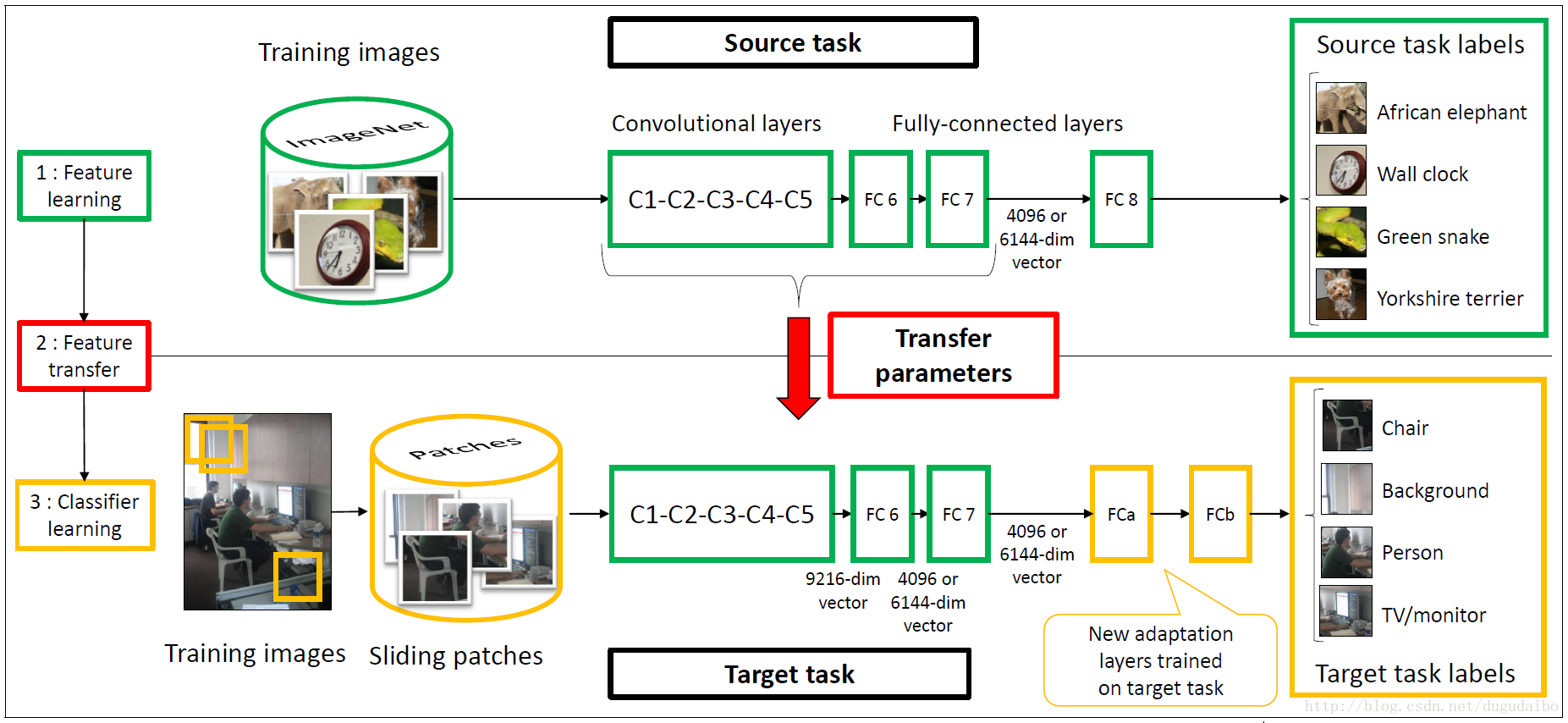
再上图中可以看到,绿色部分代表的是原任务,红色部分代表迁移部分,黄色部分代表目标任务部分。我们可以看出迁移过去的包括绿色的网络框架和预训练得到的权重文件。其中原任务采用的是 Krizhevsky 的网络结构。在目标任务中去掉了全连接层Fc8,添加了全连接层FCa、FCb。
值得注意的是,Y7 (Fc7的输出值)是一个潜在的所有输入像素的复杂非线性函数,能够捕获中层目标部分和高层配置部分。
C1−FC7 层的参数是首先在原任务中训练得到的,在迁移学习的过程中迁移到目标任务中并且保持不变。只有新加的两层全连接层在目标任务中进行训练。

我们利用滑动窗口的方法从每幅图像中从每一张图像中提取大概500个方形的块,通过在相邻斑块之间至少有50%重叠的规则间隔的网格上采样八种不同的尺度。更确切地说,我们使用宽度为 s=min(w,h)/λ像素的方形块,其中 w和h 是分别代表图像的长和宽,并且 lambda∈1,1.2,1.6,2,2.4,2.8,3.2,3.6,4每一个块被重新缩放到 224×224 来形成网络的固定输入。但是注意到这实际上是9个数。其中尺度的变化是因为在目标任务中待识别的物体又大有小,为了使得较小的物体在子图象块仍然可以有较大的占比,所以才有尺度的变换。
采样的图像块包含一个或者多个目标,背景或者只包含部分的目标。为了标注训练图像块,我们测量了图像块P中的边界框与标注物体的真实边界框B的重叠部分,如下图所示
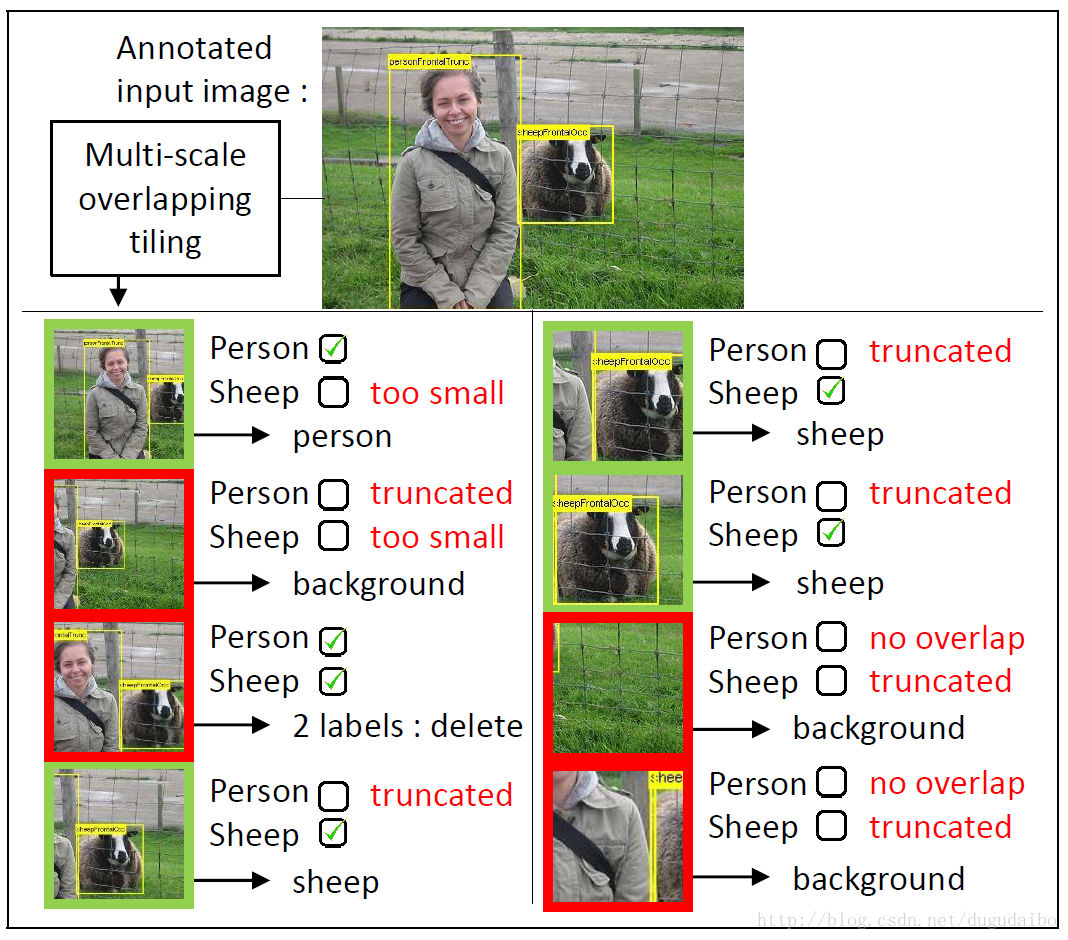
判断与类别 O 相关的块 B0 是否是否可以被贴上这一类的标签,要看起是否满足同时满足以下几个条件
(1)B0 充分地覆盖了图像块 P,|P∩Bo|≥0.2|P|;
(2)图像块 P 包含很大一部分的图像块 B0 ,|P∩Bo|≥0.6|Bo|;
(3)图像块中没有包含超过一个物体(指的是同时满足上面两个要求的物体)。
值得注意的是,经过上述过程处理之后的图像与原任务中的图像是十分相似的,主要的目标都在图像的中央。所以处理数据集捕获偏置(a dataset capture bias)以及反例数据偏置(negative data bias)就是通过滑动窗口的方法对子图象进行重新标注。
通过上述方法之后会产生大量的标注为背景的子图象,这就会引起数据集的不均衡分布,本文采用的方法是随机地从训练集的背景块中采样10% 的训练数据。
我们采用如下的求和公式求出在图像中物体 Cn 的总体得分
score(Cn)=1MΣMi=1y(Cn|Pi)k
其中 y(Cn|Pi)k 是在图像块 Pi 中类 Cn 在网络中的输出值,M是图像中图像块的数量,k 是一个大于1的常数。较高的 k 值关注得分最高的 图像块而弱化得分较低或者中等图像块的贡献。本文实验得 k=5 为最有情况。
值得注意的是,图像块的得分可以通过在全图像的充分采样值下计算大的卷积来更效率地计算。这将通过更低的计算代价获得更密集的图像块覆盖。实际上就是通过在全部图像进行卷积来替代通过滑动窗口提取子图象。这部分的原理可以参考我的博客《卷积神经网络入门详解》的“2.4.2 将全连接层转化成卷积层”的最后部分。但需要注意的是这样的操作只能在测试的时候进行,因为在训练的过程中是需要对取得的图像块进行标注的,但是使用卷积代替滑动窗口没有办法解决标签问题的。
Training convolutional networks.
预训练过程,采用 Krizhevsky 等的代码和参数,但是没有改变 RGB 的强度,初始学习率为0.01.训练知道指标稳定,学习率除以10 ,重复上次,一共这样做了三次。
Image classification on ImageNet
使用了100类的图像,共120万张图像(PRE1000C)。训练结果稍微逊色于最好情况,可能是因为没有改变颜色通道的强度。
Image classification on Pascal VOC 2007
我们使用我们的中层特征迁移策略于Pascal VOC 2007的目标分类任务上。实验结果如表格1所示

我们提出的迁移学习技术(PRE1000C)与之前冠军的结果有了显著的提高。
Image classification on Pascal VOC 2012
我们提出的方法在Pascal VOC 2012与最好的结果有一定的差距,并且仍在5个结果中超过了它。然后作者为了证明自己的效果比较好,使用没有预训练的网络直接进行训练和分类,发现正确率比自己提出的迁移学习的效果要差,证明了迁移学习确实提高了结果。

Transfer learning and source/target class overlap
class overlap是指类的重叠,比如说 Image Net 中的500种狗在 Pascal VOC 统称为狗。为了探究这种重叠带来的影响,有随机地在 Image Net 中 22000 个类中随机选取了1000个类进行训练,得到PRE1000R。实验表明整体的表现有轻微的下降,这说明在源任务与目标任务中列的重叠对于迁移学习有着积极的影响。然而,多给出的表现只有微小的下降表明了我们的迁移学习过程对于源和目标类的改变具有鲁棒性。因为在这次试验中训练图像的数量是PRE1000C的 0.25,这也有可能是导致表现下降的一个原因。
进一步实验,增加了用于预训练图像的类别,在 Image Net 中又选取了512类图像。并对应的修改了全连接层的结构。预训练,在 Image Net 分类top5_error正确率为21.8%,注意这是要低于之前的 18% 的。用这样的预训练网络进行迁移学习,我们得到的结果超过当年的最佳结果,并且在新添加的类获得了较大的提升(具体将就是在 Image Net 中 选取了furniture这一大类),那么在目标任务中sofa,chair, table的正确率就得到了提高。通过比较PRE-1000R, PRE-1000C 和 PRE-1512,我们可以得出结论,源任务中图像的数量和种类对于目标任务中的表现具有着决定性的作用。因此使用更大的源任务可以提高迁移学习的性能。
这里实际上还隐含着两个结论。首先预训练集上的正确率与预训练集中图像的种类这两者中,图像的种类对于迁移学习在目标任务中的影响更大;其次某种图像在原任务中出现过,那么它在目标任务中的正确率就会更高。
Varying the number of adaptation layers
在保持输出层不变,在输出层的前一层增加一层隐层和去掉一层隐层都会使得图像分类的正确率下降。
Object localization
动作识别是一种在微小程度上的识别,使用表现最好的PRE-1512作为迁移学习的方法。由于在测试时已知执行动作的人的包围框,每个测试和测试都使用单个正方形块进行,每个示例集中在人在边框中间。提取图像块的程序可能需要通过镜像像素来放大原始图像。实验结果如表3中的 PRE-1512 行
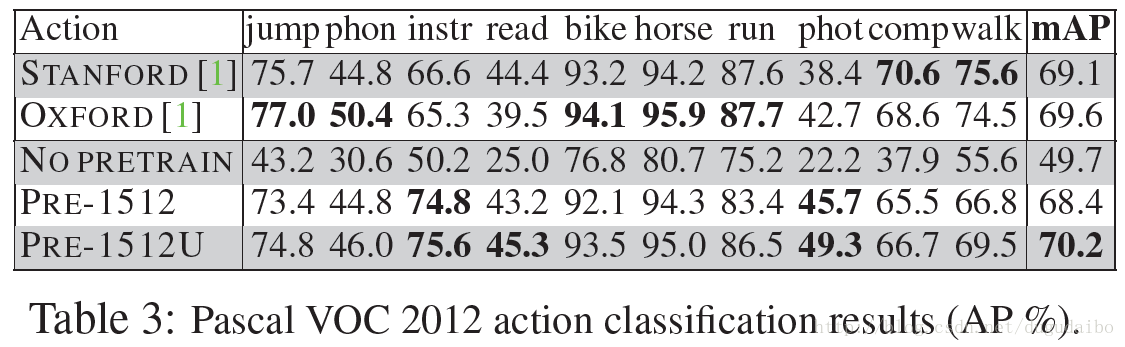
与没有预训练的基线相比 PRE-1512 的实验结果明显提高了很多。具体来讲我们在playing instrument 和taking photo 两个类上获得了最佳的效果。
受到了某一篇文献的启发,作者重新训练 FC6、FC7、FCa、FCb 四个层,之前是不重新训练 FC6、FC7 两层的,发现实验结果提高了。并且与之前类似,可以确定图像中动作的位置。
Failure modes
在下图中,排名最高的假阳性与目标类中的采样十分相近。
解决这些错误可能需要高水平的景物解释。我们的方法也可能无法识别空间共有对象(如一个人在椅子上),因为有多个对象的块在训练的过程中已经被排除在外了。这个问题可以通过改变训练目标来解决,以允许每个样本有多个标签。由于当前实现中的子图象块的稀疏采样,非常小或非常大的对象的识别也可能失败。正如第3.3节所提到的,这个问题可以通过更有效的基于卷积神经网络的滑动窗口实现来解决。
目标任务:对Pascal VOC的目标和动作分类;期望所设计的网络能够目标种类和或者背景(如果在图像中不存在某一种类)的分数。
所面临的问题:
(1)目标任务中的数据集太小,而神经网络的参数过多会导致过拟合;
(2)目标任务的数据集中的图像的统计特征(目标的种类、特有的视角和成像条件等)与原任务不同。具体来讲有标签偏置(label bias),如在原任务中的金毛,泰迪等在目标任务中都对应狗;还有数据集捕获偏置(a dataset capture bias),如目标的大小,尺寸和相互遮挡模式等;以及反例数据偏置(negative data bias),如在背景中包含许多其他目标。
(3)滑动窗口采样的过程中,采样的图像块包含一个或者多个目标,背景或者只包含部分的目标。
(4)通过上述方法之后会产生大量的标注为背景的子图象,这就会引起数据集的不均衡分布
提出的解决方法:
(1)用在原任务中学习到的CNN层进行迁移学习
(2)采用滑动窗口、变化采样尺寸的方法采样图像并进行重新标注
(3)对采样后的窗口重新标注
(4)随机地从训练集的背景块中采样10% 的训练数据
文章的相关结论:
(1)卷积层能够产生通用的中层图像表示,以至于它们能够迁移到新任务上;卷积神经网络提供学习丰富的,可迁移到大量视觉识别任务中的中层图像特征
(2)Y7 (Fc7的输出值)是一个潜在的所有输入像素的复杂非线性函数,能够捕获中层目标部分和高层配置部分;
(3)在源任务与目标任务中列的重叠对于迁移学习有着积极的影响
(4)迁移学习过程对于源和目标类的改变具有鲁棒性
(5)源任务中图像的数量和种类对于目标任务中的表现具有着决定性的作用。首先预训练集上的正确率与预训练集中图像的种类这两者中,图像的种类对于迁移学习在目标任务中的影响更大;其次某种图像在原任务中出现过,那么它在目标任务中的正确率就会更高。
(6)在保持输出层不变,在输出层的前一层增加一层隐层和去掉一层隐层都会使得图像分类的正确率下降
目前该方法的局限性:
无法识别本身十分相近的目标,无法识别多目标,非常小或非常大的对象的识别也可能失败。
补充信息:
[1]Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
[1]来源:http://www.jianshu.com/p/9990284bc4d5(简书)
0. 摘要翻译
卷积神经网络在大规模视觉识别挑战(ILSVRC2012)的图像分类任务上最近表现杰出。CNN的成功主要归功于它能够学习大量的中层图像,这点恰好与其他图像分类器中的手工设计的特征相反。然而,CNN的学习需要建立数以百万计的参数,并且需要大量已经标注好的图像。这种特性目前阻止了CNN在有限训练集问题上的应用。在本文中我们将展示在大规模标记的数据上用CNN学习出的图像表示是如何有效地被迁移到其他视觉识别的任务中。我们设计了一种方法以至于能重新使用在Image net数据集上训练的层来计算PASCAL VOC数据集上图片的中层图像特征。我们的研究表明即使在两个数据集上图像的统计特征和任务是不同的,但是迁移学习显著提高了物体和动作的分类结果,优于目前在Pascal VOC 2007 and 2012数据集上最先进的结果。我们也展示了结果有希望能够实现目标和动作的定位。
1. Introduction
文章首先介绍了在目标识别(Object recognition)领域有许多紧张,这些有方法方面的进展,如STIFT,HOG,词包模型和可变形模型等。另一个推进目标识别发展的是大规模数据集的出现,如Caltech256、Pascal VOC、ImageNet。虽然卷积神经网络之前(值得应该是2014年)用的不多,在视觉识别任务中已经有很长的一段历史了。接下来文章简单的从感知机降到了CNN的大规模应用。卷积神经网络(CNN)是有着大量参数的大容量分类器,所以必须从训练样本学习。虽然CNN已经被称为在其他的视觉任务(包括通用对象识别中)效果超过超过特征识别,但是首先于标准目标识别数据集的相对较小的规模。
值得注意的是,许多成功的图像分类器使用了新认知机和卷积神经网络。量化及空间聚集局部描述子与这些通过前两层新认知机计算得到的相比较是浅层特征。所以浅层特征比早期的CNN要好,可能是因为CNN很难在较小的数据集上进行训练。然而大规模数据集的出现和GPU的出现使得CNN得到了跳跃性的发展(performance leap)和更大的进步(further improve)。
有人认为不同的计算机视觉数据集在图像统计特征上有显著的差异,如视角、背景信息,场景信息和其他因子。鉴于CNN“data hungry”的特点,如何使用有限的数据训练CNN是一个重要的问题。
到目前为止,文章所提出的问题主要有这几个。首先CNN的学习需要建立数以百万计的参数,并且需要大量已经标注好的图像;如果数据的数量不够将使得模型过拟合,效果变差,并且很有可能效果要差于传统的手工特征;其次不同的计算机视觉数据集在图像统计特征上有显著的差异,那我们在将来的每一个新的视觉识别任务中是否都需要收集一个百万级的图片数据集。归结起来就是,CNN在处理原始任务的时候需要大量的标注数据才能训练,如果新任务(可能与原始任务相同,比如说都是分类任务;也有可能与原始任务不同,一个分类一个识别)所具有的数据集与原始的数据集在统计上有显著的不同,并且数据量较小,这个时候应该如何使用CNN来完成新任务。
为了解决这个问题,我们提出了一种把在大规模数据集上CNN学习到的图像表示迁移到其他的有限训练集的视觉识别问题上。具体来讲,我们提出一种使用在Image net上训练的CNN的层来有效率地计算Pascal VOC图片集图像的中层表示。实验效果(物体及动作分类)的效果很好。结果表明迁移学习可能用于物体和动作的定位。
2. Related Work
迁移学习、图像分类和深度学习三个方面的相关工作。在迁移学习方面,以往的工作都是在标准的图像特征上进行训练,而本文提出的方法直接在源空间进行训练。有的方法与我们的十分相似,采用无监督伪任务训练CNN,但是我们采用在大规模有监督任务上训练CNN的卷积层并且解决了图像中物体尺寸和位置变换的问题。有些人与本文的研究方法相似,但是处理的问题是不同的。
在视觉目标分类方面,之前常用的方法有词包模型、密集SIFT、K均值等各种各样的方法。但是这些方法都无法表明他们是最好的方法,所以也就引起了人们对于中层特征和一半特征学习的兴趣。而我们的工作表明卷积层能够产生通用的中层图像表示,以至于它们能够迁移到新任务上。
在深度学习方面,最近兴起的多层神经网络的兴趣是有越老越多的学习中间表示的工作触发的,或者使用无监督的方法,或者使用更多的传统的监督学习的技术。
3. Transferring CNN weights
本文所使用的神经网络具有6000万个参数,使用几千张图片进行计算是存在问题的。本文的关键思想在于CNN的中间层能够作为中级图像表示通用提取器,这个提取器能够在原任务(这里是Image Net)中预训练然后重新应用与其他目标任务上(这里是Pascal VOC的目标和动作识别) 。然而进行迁移学习也是困难的,因为在原任务和目标任务中图像的标签和分布(目标的种类、特有的视角和成像条件等)也是非常不同的。针对这个挑战我们设计一种结构,这种结构能够显著地重新绘制原任务与目标任务之间类的标签(见3.1部分)。其次,受滑动窗口检测可以明显地处理目标尺寸分布不同的问题的启发,发展训练和测试过程,针对在原任务和目标任务中的定位和背景混乱问题(见3.2和3.3)。
3.1. Network architecture
所搭建的网络结构如下图所示再上图中可以看到,绿色部分代表的是原任务,红色部分代表迁移部分,黄色部分代表目标任务部分。我们可以看出迁移过去的包括绿色的网络框架和预训练得到的权重文件。其中原任务采用的是 Krizhevsky 的网络结构。在目标任务中去掉了全连接层Fc8,添加了全连接层FCa、FCb。
值得注意的是,Y7 (Fc7的输出值)是一个潜在的所有输入像素的复杂非线性函数,能够捕获中层目标部分和高层配置部分。
C1−FC7 层的参数是首先在原任务中训练得到的,在迁移学习的过程中迁移到目标任务中并且保持不变。只有新加的两层全连接层在目标任务中进行训练。
3.2. Network training
首先在原任务上进行预训练。但是如下图所示,在原任务(ImageNet)与目标任务(Pascal VOC)中,在两类任务中,目标的位置、大小、相互遮挡模式,这个问题也被称为数据集捕获偏置(a dataset capture bias)。另外在目标任务中的背景中可能包含许多其他目标,这个也被称为反例数据偏置(negative data bias)。为了克服这两个问题,我们受启发于滑动窗口检测的训练方法训练添加的层。我们利用滑动窗口的方法从每幅图像中从每一张图像中提取大概500个方形的块,通过在相邻斑块之间至少有50%重叠的规则间隔的网格上采样八种不同的尺度。更确切地说,我们使用宽度为 s=min(w,h)/λ像素的方形块,其中 w和h 是分别代表图像的长和宽,并且 lambda∈1,1.2,1.6,2,2.4,2.8,3.2,3.6,4每一个块被重新缩放到 224×224 来形成网络的固定输入。但是注意到这实际上是9个数。其中尺度的变化是因为在目标任务中待识别的物体又大有小,为了使得较小的物体在子图象块仍然可以有较大的占比,所以才有尺度的变换。
采样的图像块包含一个或者多个目标,背景或者只包含部分的目标。为了标注训练图像块,我们测量了图像块P中的边界框与标注物体的真实边界框B的重叠部分,如下图所示
判断与类别 O 相关的块 B0 是否是否可以被贴上这一类的标签,要看起是否满足同时满足以下几个条件
(1)B0 充分地覆盖了图像块 P,|P∩Bo|≥0.2|P|;
(2)图像块 P 包含很大一部分的图像块 B0 ,|P∩Bo|≥0.6|Bo|;
(3)图像块中没有包含超过一个物体(指的是同时满足上面两个要求的物体)。
值得注意的是,经过上述过程处理之后的图像与原任务中的图像是十分相似的,主要的目标都在图像的中央。所以处理数据集捕获偏置(a dataset capture bias)以及反例数据偏置(negative data bias)就是通过滑动窗口的方法对子图象进行重新标注。
通过上述方法之后会产生大量的标注为背景的子图象,这就会引起数据集的不均衡分布,本文采用的方法是随机地从训练集的背景块中采样10% 的训练数据。
3.3. Classification
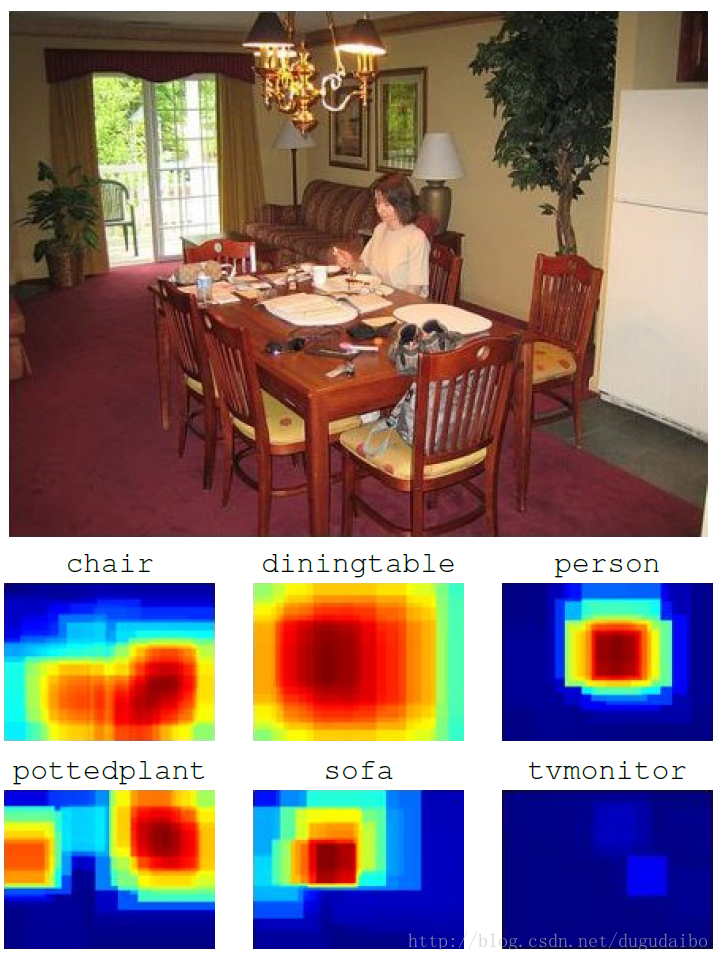
在测试阶段,我们采用网络对从测试图像中提取的多尺度的500张图像使用训练的网络。每一个子图象得分的可视化如下图所示我们采用如下的求和公式求出在图像中物体 Cn 的总体得分
score(Cn)=1MΣMi=1y(Cn|Pi)k
其中 y(Cn|Pi)k 是在图像块 Pi 中类 Cn 在网络中的输出值,M是图像中图像块的数量,k 是一个大于1的常数。较高的 k 值关注得分最高的 图像块而弱化得分较低或者中等图像块的贡献。本文实验得 k=5 为最有情况。
值得注意的是,图像块的得分可以通过在全图像的充分采样值下计算大的卷积来更效率地计算。这将通过更低的计算代价获得更密集的图像块覆盖。实际上就是通过在全部图像进行卷积来替代通过滑动窗口提取子图象。这部分的原理可以参考我的博客《卷积神经网络入门详解》的“2.4.2 将全连接层转化成卷积层”的最后部分。但需要注意的是这样的操作只能在测试的时候进行,因为在训练的过程中是需要对取得的图像块进行标注的,但是使用卷积代替滑动窗口没有办法解决标签问题的。
4. Experiments
主要内容为:训练的细节、预训练在原任务的分类结果、迁移学习在目标任务的实验结果、通过目标的类别来研究实验结果对源和目标任务重叠的依赖性,最后是迁移学习在静止图像的识别任务实验。Training convolutional networks.
预训练过程,采用 Krizhevsky 等的代码和参数,但是没有改变 RGB 的强度,初始学习率为0.01.训练知道指标稳定,学习率除以10 ,重复上次,一共这样做了三次。
Image classification on ImageNet
使用了100类的图像,共120万张图像(PRE1000C)。训练结果稍微逊色于最好情况,可能是因为没有改变颜色通道的强度。
Image classification on Pascal VOC 2007
我们使用我们的中层特征迁移策略于Pascal VOC 2007的目标分类任务上。实验结果如表格1所示
我们提出的迁移学习技术(PRE1000C)与之前冠军的结果有了显著的提高。
Image classification on Pascal VOC 2012
我们提出的方法在Pascal VOC 2012与最好的结果有一定的差距,并且仍在5个结果中超过了它。然后作者为了证明自己的效果比较好,使用没有预训练的网络直接进行训练和分类,发现正确率比自己提出的迁移学习的效果要差,证明了迁移学习确实提高了结果。
Transfer learning and source/target class overlap
class overlap是指类的重叠,比如说 Image Net 中的500种狗在 Pascal VOC 统称为狗。为了探究这种重叠带来的影响,有随机地在 Image Net 中 22000 个类中随机选取了1000个类进行训练,得到PRE1000R。实验表明整体的表现有轻微的下降,这说明在源任务与目标任务中列的重叠对于迁移学习有着积极的影响。然而,多给出的表现只有微小的下降表明了我们的迁移学习过程对于源和目标类的改变具有鲁棒性。因为在这次试验中训练图像的数量是PRE1000C的 0.25,这也有可能是导致表现下降的一个原因。
进一步实验,增加了用于预训练图像的类别,在 Image Net 中又选取了512类图像。并对应的修改了全连接层的结构。预训练,在 Image Net 分类top5_error正确率为21.8%,注意这是要低于之前的 18% 的。用这样的预训练网络进行迁移学习,我们得到的结果超过当年的最佳结果,并且在新添加的类获得了较大的提升(具体将就是在 Image Net 中 选取了furniture这一大类),那么在目标任务中sofa,chair, table的正确率就得到了提高。通过比较PRE-1000R, PRE-1000C 和 PRE-1512,我们可以得出结论,源任务中图像的数量和种类对于目标任务中的表现具有着决定性的作用。因此使用更大的源任务可以提高迁移学习的性能。
这里实际上还隐含着两个结论。首先预训练集上的正确率与预训练集中图像的种类这两者中,图像的种类对于迁移学习在目标任务中的影响更大;其次某种图像在原任务中出现过,那么它在目标任务中的正确率就会更高。
Varying the number of adaptation layers
在保持输出层不变,在输出层的前一层增加一层隐层和去掉一层隐层都会使得图像分类的正确率下降。
Object localization
动作识别是一种在微小程度上的识别,使用表现最好的PRE-1512作为迁移学习的方法。由于在测试时已知执行动作的人的包围框,每个测试和测试都使用单个正方形块进行,每个示例集中在人在边框中间。提取图像块的程序可能需要通过镜像像素来放大原始图像。实验结果如表3中的 PRE-1512 行
与没有预训练的基线相比 PRE-1512 的实验结果明显提高了很多。具体来讲我们在playing instrument 和taking photo 两个类上获得了最佳的效果。
受到了某一篇文献的启发,作者重新训练 FC6、FC7、FCa、FCb 四个层,之前是不重新训练 FC6、FC7 两层的,发现实验结果提高了。并且与之前类似,可以确定图像中动作的位置。
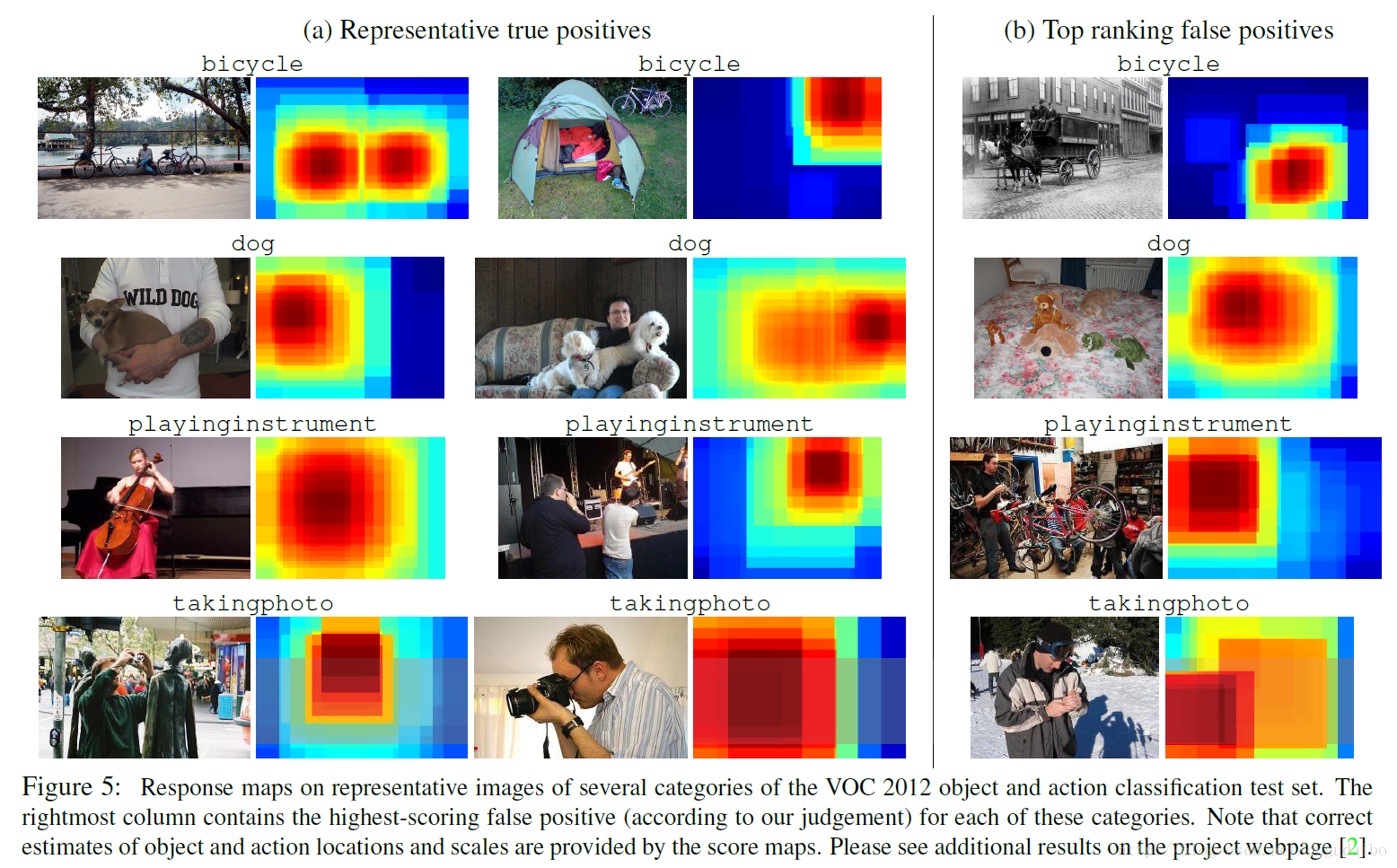
Failure modes
在下图中,排名最高的假阳性与目标类中的采样十分相近。
解决这些错误可能需要高水平的景物解释。我们的方法也可能无法识别空间共有对象(如一个人在椅子上),因为有多个对象的块在训练的过程中已经被排除在外了。这个问题可以通过改变训练目标来解决,以允许每个样本有多个标签。由于当前实现中的子图象块的稀疏采样,非常小或非常大的对象的识别也可能失败。正如第3.3节所提到的,这个问题可以通过更有效的基于卷积神经网络的滑动窗口实现来解决。
5. Conclusion
在较小的数据集中仅仅使用简单的迁移学习就可以获得最好的效果,如本文中仅仅使用了 Image Net 的12% 的数据就在两项任务重获得了最佳的结果。这篇文章也表现了通过在 Image Net 上训练CNN 提取出的中层特征具有较高的潜力。本文也在一定程度上证明了卷积神经网络提供学习丰富的,可迁移到大量视觉识别任务中的中层图像特征的方法。6. 全文总结
原任务:对ImageNet上的图像进行分类;目标任务:对Pascal VOC的目标和动作分类;期望所设计的网络能够目标种类和或者背景(如果在图像中不存在某一种类)的分数。
所面临的问题:
(1)目标任务中的数据集太小,而神经网络的参数过多会导致过拟合;
(2)目标任务的数据集中的图像的统计特征(目标的种类、特有的视角和成像条件等)与原任务不同。具体来讲有标签偏置(label bias),如在原任务中的金毛,泰迪等在目标任务中都对应狗;还有数据集捕获偏置(a dataset capture bias),如目标的大小,尺寸和相互遮挡模式等;以及反例数据偏置(negative data bias),如在背景中包含许多其他目标。
(3)滑动窗口采样的过程中,采样的图像块包含一个或者多个目标,背景或者只包含部分的目标。
(4)通过上述方法之后会产生大量的标注为背景的子图象,这就会引起数据集的不均衡分布
提出的解决方法:
(1)用在原任务中学习到的CNN层进行迁移学习
(2)采用滑动窗口、变化采样尺寸的方法采样图像并进行重新标注
(3)对采样后的窗口重新标注
(4)随机地从训练集的背景块中采样10% 的训练数据
文章的相关结论:
(1)卷积层能够产生通用的中层图像表示,以至于它们能够迁移到新任务上;卷积神经网络提供学习丰富的,可迁移到大量视觉识别任务中的中层图像特征
(2)Y7 (Fc7的输出值)是一个潜在的所有输入像素的复杂非线性函数,能够捕获中层目标部分和高层配置部分;
(3)在源任务与目标任务中列的重叠对于迁移学习有着积极的影响
(4)迁移学习过程对于源和目标类的改变具有鲁棒性
(5)源任务中图像的数量和种类对于目标任务中的表现具有着决定性的作用。首先预训练集上的正确率与预训练集中图像的种类这两者中,图像的种类对于迁移学习在目标任务中的影响更大;其次某种图像在原任务中出现过,那么它在目标任务中的正确率就会更高。
(6)在保持输出层不变,在输出层的前一层增加一层隐层和去掉一层隐层都会使得图像分类的正确率下降
目前该方法的局限性:
无法识别本身十分相近的目标,无法识别多目标,非常小或非常大的对象的识别也可能失败。
补充信息:
[1]Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
[1]来源:http://www.jianshu.com/p/9990284bc4d5(简书)

相关文章推荐
- Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks
- learning and transferring mid-level image representations using convolutional neural networks
- Learning_and_Transferring_Mid-Level_Image_Representations_using_Convolutional_Neural_Networks
- Learning and Transferring Mid-Level Image Representations(泛读)
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H
- [论文阅读]Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks
- 论文阅读:Joint Learning of Single-image and Cross-image Representations for Person Re-identification
- 论文总结 - Image Style Transfer Using Convolutional Neural Networks
- 论文阅读(1)——ImageNet Classification with Deep Convolutional Neural Networks
- 论文阅读ImageNet Classification with Deep Convolutional Neural Networks &Going Deeper with Convolutions
- 《image Style Transfer Using Convolutional Neural Networks》论文笔记
- 论文学习:Learning to Compare Image Patches via Convolutional Neural Networks
- CVPR2017论文阅读:Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis
- Adaptive Deconvolutional Networks for Mid and High Level Feature Learning(阅读)
- 【论文阅读】Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huff
- Image Scaling using Deep Convolutional Neural Networks
- 论文阅读《Edge Detection Using Convolutional Neural Network》
- 论文阅读之Compressing Deep Convolutional Networks using Vector Quantization
- [深度学习论文笔记][Image Classification] ImageNet Classification with Deep Convolutional Neural Networks
- 经典计算机视觉论文笔记——《ImageNet Classification with Deep Convolutional Neural Networks》