NLP实践五:神经网络基础概念
目录
神经网络结构
1神经网络的输入输出
来自:神经网络算法推演
假如神经网络仅由“神经元”构成,以下即是这个“神经元”的图示:

这个“神经元”是一个以 x1,x2,x3\ \textstyle x_1, x_2, x_3 x1,x2,x3截距+1 为输入值的运算单元,其输出为:
hW,b(x)=f(WTx)=f(∑i=13Wixi+b) \textstyle h_{W,b}(x) = f(W^Tx) = f(\sum_{i=1}^3 W_{i}x_i +b)hW,b(x)=f(WTx)=f(∑i=13Wixi+b)
可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归.
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:

我们使用圆圈来表示神经网络的输入,标上“+1+1”的圆圈被称为”’偏置节点”’,也就是截距项。神经网络最左边的一层叫做”‘输入层”’,最右的一层叫做”‘输出层’”(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做”’隐藏层”’,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个”’输入单元”’(偏置单元不计在内),3个”’隐藏单元”’及一个”’输出单元”’。
我们用nln_lnl来表示网络的层数,本例中nl=3n_l=3nl=3 ,我们将第lll层记为LlL_lLl ,于是L1L1L1 是输入层,输出层是LnlL_{n_l}Lnl 。本例神经网络有参数(W,b)=(W(1),b(1),W(2),b(2))\textstyle (W,b) = (W^{(1)}, b^{(1)}, W^{(2)}, b^{(2)})(W,b)=(W(1),b(1),W(2),b(2)),其中Wij(l)\textstyle W^{(l)}_{ij}Wij(l)(下面的式子中用到)是第lll 层第jj 单元与第l+1l+1l+1 层第iii 单元之间的联接参数(其实就是连接线上的权重,注意标号顺序),bi(l)b^{(l)}_ibi(l)是第l+1l+1l+1层第iii单元的偏置项。因此在本例中W(1)∈ℜ3×3\textstyle W^{(1)} \in \Re^{3\times 3}W(1)∈ℜ3×3,W(2)∈ℜ1×3\textstyle W^{(2)} \in \Re^{1\times 3}W(2)∈ℜ1×3注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出+1+1。同时,我们用sls_lsl表示第lll 层的节点数(偏置单元不计在内)。
我们用ai(l)a^{(l)}_iai(l) 表示第ll 层第ii 单元的”’激活值”’(输出值)。当l=1l=1l=1 时,ai(1)=xi\textstyle a^{(1)}_i = x_iai(1)=xi,也就是第iii 个输入值(输入值的第iii个特征)。对于给定参数集合W,bW,bW,b,我们的神经网络就可以按照hW,b(x)\textstyle h_{W,b}(x)hW,b(x) 来计算输出结果。本例神经网络的计算步骤如下:
a1(2)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+b2(1))a3(2)=f(W31(1)x1+W32(1)x2+W33(1)x3+b3(1))hW,b(x)=a1(3)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
\begin{aligned}
a_1^{(2)} &= f(W_{11}^{(1)}x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1^{(1)}) \\
a_2^{(2)} &= f(W_{21}^{(1)}x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + b_2^{(1)}) \\
a_3^{(2)} &= f(W_{31}^{(1)}x_1 + W_{32}^{(1)} x_2 + W_{33}^{(1)} x_3 + b_3^{(1)}) \\
h_{W,b}(x) &= a_1^{(3)} = f(W_{11}^{(2)}a_1^{(2)} + W_{12}^{(2)} a_2^{(2)} + W_{13}^{(2)} a_3^{(2)} + b_1^{(2)})
\end{aligned}
a1(2)a2(2)a3(2)hW,b(x)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))=f(W21(1)x1+W22(1)x2+W23(1)x3+b2(1))=f(W31(1)x1+W32(1)x2+W33(1)x3+b3(1))=a1(3)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
我们用zi(l)z^{(l)}_izi(l) 表示第lll层第iii单元输入加权和(包括偏置单元),zi(2)=∑j=1nWij(1)xj+bi(1)\textstyle z_i^{(2)} = \sum_{j=1}^n W^{(1)}_{ij} x_j + b^{(1)}_izi(2)=∑j=1nWij(1)xj+bi(1),这样我们就可以得到一种更简洁的表示法。这里我们将激活函数f(⋅)f(⋅)f(⋅) 扩展为用向量(分量的形式)来表示,即z(2)=W(1)x+b(1)a(2)=f(z(2))z(3)=W(2)a(2)+b(2)hW,b(x)=a(3)=f(z(3))\begin{aligned} z^{(2)} &= W^{(1)} x + b^{(1)} \\ a^{(2)} &= f(z^{(2)}) \\ z^{(3)} &= W^{(2)} a^{(2)} + b^{(2)} \\ h_{W,b}(x) &= a^{(3)} = f(z^{(3)}) \end{aligned}z(2)a(2)z(3)hW,b(x)=W(1)x+b(1)=f(z(2))=W(2)a(2)+b(2)=a(3)=f(z(3))
我们将上面的计算步骤叫作”’前向传播”’。回想一下,之前我们用a(1)=x\textstyle a^{(1)} = xa(1)=x 表示输入层的激活值,那么给定第lll层的激活值a(l)\textstyle a^{(l)}a(l)
第l+1\textstyle l+1l+1 层的激活值a(l+1)\textstyle a^{(l+1)}a(l+1)就可以按照下面步骤计算得到:
z(l+1)=W(l)a(l)+b(l)a(l+1)=f(z(l+1))\begin{aligned} z^{(l+1)} &= W^{(l)} a^{(l)} + b^{(l)} \\ a^{(l+1)} &= f(z^{(l+1)}) \end{aligned}z(l+1)a(l+1)=W(l)a(l)+b(l)=f(z(l+1))
将参数矩阵化,使用矩阵-向量运算方式,我们就可以利用线性代数的优势对神经网络进行快速求解。
目前为止,我们讨论了一种神经网络,我们也可以构建另一种”’结构”’的神经网络(这里结构指的是神经元之间的联接模式),也就是包含多个隐藏层的神经网络。最常见的一个例子是nl\textstyle n_lnl层的神经网络,第1\textstyle 11 层是输入层,第nl\textstyle n_lnl层是输出层,中间的每个层l\textstyle ll与层l+1l+1l+1 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第L2\textstyle L_2L2 层的所有激活值,然后是第L3\textstyle L_3L3 层的激活值,以此类推,直到第Lnl\textstyle L_{n_l}Lnl层。这是一个”’前馈”’神经网络的例子,因为这种联接图没有闭环或回路。
神经网络也可以有多个输出单元。比如,下面的神经网络有两层隐藏层:L2\textstyle L_2L2及L3\textstyle L_3L3 ,输出层L4\textstyle L_4L4 有两个输出单元。
1 激活函数
激活函数的作用:就是将权值结果转化成分类结果。
为什么使用非线性的激活函数:
只通过线性变换,任意层的全连接神经网络和单层的神经网络模型的表达能力没有任何区别,而且它们都是线性模型。线性模型能够解决的问题是有限的,这就是线性模型最大的局限性。如果使用线性的激活函数,那么输入x跟输出y之间的关系为线性的,便可以不需要网络结构,直接使用线性组合便可以.只有在输出层极小可能使用线性激活函数,在隐含层都使用非线性激活函数.
来自(深度学习使用到的激活函数种类和优缺点解释)
常见三种激活函数:
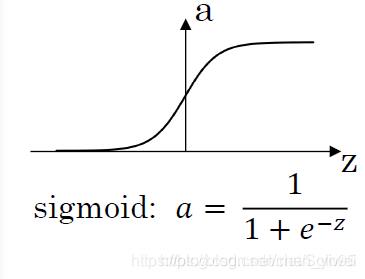
Sigmoid.
Sigmoid(也叫逻辑激活函数) 非线性激活函数的形式是,其图形如上图所示。之前我们说过,sigmoid函数输入一个实值的数,然后将其压缩到0~1的范围内。特别地,大的负数被映射成0,大的正数被映射成1。sigmoid function在历史上流行过一段时间因为它能够很好的表达“激活”的意思,未激活就是0,完全饱和的激活则是1。而现在sigmoid已经不怎么常用了,主要是因为它有两个缺点:
Sigmoids saturate and kill gradients. Sigmoid容易饱和,并且当输入非常大或者非常小的时候,神经元的梯度就接近于0了,从图中可以看出梯度的趋势。这就使得我们在反向传播算法中反向传播接近于0的梯度,导致最终权重基本没什么更新,我们就无法递归地学习到输入数据了。另外,你需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变的很难学习。
Sigmoid outputs are not zero-centered. Sigmoid 的输出不是0均值的,这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in ),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。
当然了,如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。

Tanh.
Tanh和Sigmoid是有异曲同工之妙的,它的图形如上图右所示,不同的是它把实值得输入压缩到-1~1的范围,因此它基本是0均值的,也就解决了上述Sigmoid缺点中的第二个,所以实际中tanh会比sigmoid更常用。但是它还是存在梯度饱和的问题。Tanh是sigmoid的变形,

ReLU.
近年来,ReLU 变的越来越受欢迎。它的数学表达式是: f(x)=max(0,x)。很显然,从上图左可以看出,输入信号
<0时,输出为0,>0时,输出等于输入。ReLU的优缺点如下:
优点1:Krizhevsky et al. 发现使用 ReLU 得到的SGD的收敛速度会比 sigmoid/tanh 快很多(如上图右)。有人说这是因为它是linear,而且梯度不会饱和
优点2:相比于 sigmoid/tanh需要计算指数等,计算复杂度高,ReLU 只需要一个阈值就可以得到激活值。
缺点1: ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都坏死了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
3代码实现
pytorch代码实现请参考:
FortiLeiZhang的CS231N作业

- 深度神经网络概述:从基本概念到实际模型和硬件基础
- 深度学习基础(五):循环神经网络概念、结构及原理实现
- 神经网络相关之基础概念的讲解
- NLP实践八:循环神经网络(RNN)
- 神经网络基础概念
- 深度学习-基础概念:神经元(Neurons)、Sigmoid 函数与神经网络基本结构
- 神经网络之基础概念理解1
- 人工神经网络基础概念、原理知识(补)
- 【深度学习 论文综述】深度神经网络全面概述:从基本概念到实际模型和硬件基础
- 人工智能,机器学习,神经网络,深度学习之基础概念
- 神经网络基础概念
- 负载均衡原理与实践详解 第三篇 服务器负载均衡的基本概念-网络基础
- 负载均衡原理与实践详解 第三篇 服务器负载均衡的基本概念-网络基础
- 《神经网络和深度学习》之神经网络基础(第二周)课后作业——Python与Numpy基础知识
- 深度学习实践系列(3)- 使用Keras搭建notMNIST的神经网络
- 深度学习算法实践7---前向神经网络算法原理
- 吴恩达 DeepLearning 神经网络基础 第一课第三周编程题目及作业
- Deep Learning Specialization课程笔记——神经网络编程基础
- 黑马程序员_java高级篇网络编程基础概念Day7
- [置顶] 基于DL的计算机视觉(9)--神经网络之动手实践