NLP实践八:TextRNN和TextRCNN实现文本分类
2019-03-16 15:09
246 查看
TextRNN
TextRNN原理
这里的文本可以一个句子,文档(短文本,若干句子)或篇章(长文本),因此每段文本的长度都不尽相同。在对文本进行分类时,我们一般会指定一个固定的输入序列/文本长度:该长度可以是最长文本/序列的长度,此时其他所有文本/序列都要进行填充以达到该长度;该长度也可以是训练集中所有文本/序列长度的均值,此时对于过长的文本/序列需要进行截断,过短的文本则进行填充。总之,要使得训练集中所有的文本/序列长度相同,该长度除之前提到的设置外,也可以是其他任意合理的数值。在测试时,也需要对测试集中的文本/序列做同样的处理。
假设训练集中所有文本/序列的长度统一为n,我们需要对文本进行分词,并使用词嵌入得到每个词固定维度的向量表示。对于每一个输入文本/序列,我们可以在RNN的每一个时间步长上输入文本中一个单词的向量表示,计算当前时间步长上的隐藏状态,然后用于当前时间步骤的输出以及传递给下一个时间步长并和下一个单词的词向量一起作为RNN单元输入,然后再计算下一个时间步长上RNN的隐藏状态,以此重复…直到处理完输入文本中的每一个单词,由于输入文本的长度为n,所以要经历n个时间步长。
模型结构
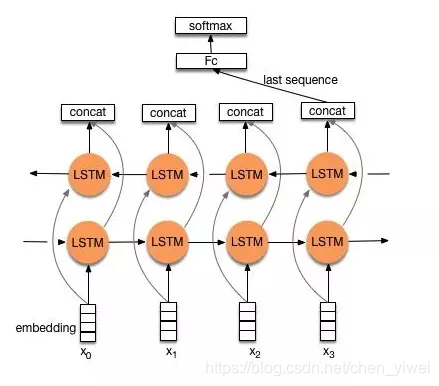
作为一个简单的例子,我使用双向LSTM作为THUcnews分类,附上模型定义与训练的代码,其他训练函数定义,与数据预处理清参考:训练函数与数据读取与数据预处理
模型定义:
class LSTM(torch.nn.Module): def __init__(self,word_embeddings): super(LSTM, self).__init__() self.embed_size = 200 self.label_num = 10 self.embed_dropout = 0.1 self.fc_dropout = 0.1 self.hidden_num = 1 self.hidden_size = 50 self.hidden_dropout = 0 self.bidirectional = True self.embeddings = nn.Embedding(len(word_embeddings),self.embed_size) self.embeddings.weight.data.copy_(torch.from_numpy(word_embeddings)) self.embeddings.weight.requires_grad = False self.lstm = nn.LSTM( self.embed_size, self.hidden_size, dropout=self.hidden_dropout, num_layers=self.hidden_num, batch_first=True, bidirectional=True ) self.embed_dropout = nn.Dropout(self.embed_dropout) self.fc_dropout = nn.Dropout(self.fc_dropout) self.linear1 = nn.Linear(self.hidden_size * 2, self.label_num) self.softmax =nn.Softmax() def forward(self, input): x = self.embeddings(input) x = self.embed_dropout(x) batch_size = len(input) _,(lstm_out,_)= self.lstm(x) lstm_out = lstm_out.permute(1,0,2) lstm_out=lstm_out.contiguous().view(batch_size,-1) out = self.linear1(lstm_out) out = self.fc_dropout(out) out = self.softmax(out) return out
训练代码:
import os os.environ['CUDA_VISIBLE_DEVICES']='0' t.cuda.set_device(0) LSTMmodel = LSTM(embed_weight) criterion = nn.CrossEntropyLoss() optimizer = optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, LSTMmodel.parameters()), lr=0.001) train(train_loader, val_loader, LSTMmodel, 'cuda', criterion, optimizer, num_epochs=20)
TextRCNN
TextRCNN原理

为啥叫做 RCNN:一般的 CNN 网络,都是卷积层 + 池化层。这里是将卷积层换成了双向 RNN,所以结果是,两向 RNN + 池化层。就有那么点 RCNN 的味道。
模型结构
模型定义:
class BiLSTM(nn.Module): def __init__(self, word_embeddings): super(BiLSTM, self).__init__() self.embed_size = 200 self.label_num = 10 self.embed_dropout = 0.1 self.fc_dropout = 0.1 self.hidden_num = 2 self.hidden_size = 50 self.hidden_dropout = 0 self.bidirectional = True self.embeddings = nn.Embedding(len(word_embeddings),self.embed_size) self.embeddings.weight.data.copy_(torch.from_numpy(word_embeddings)) self.embeddings.weight.requires_grad = False self.lstm = nn.LSTM( self.embed_size, self.hidden_size, dropout=self.hidden_dropout, num_layers=self.hidden_num, batch_first=True, bidirectional=self.bidirectional ) self.embed_dropout = nn.Dropout(self.embed_dropout) self.fc_dropout = nn.Dropout(self.fc_dropout) self.linear1 = nn.Linear(self.hidden_size * 2, self.hidden_size // 2) self.linear2 = nn.Linear(self.hidden_size // 2, self.label_num) def forward(self, input): out = self.embeddings(input) out = self.embed_dropout(out) out, _ = self.lstm(out) out = torch.transpose(out, 1, 2) out = torch.tanh(out) out = F.max_pool1d(out, out.size(2)) out = out.squeeze(2) out = self.fc_dropout(out) out = self.linear1(F.relu(out)) output = self.linear2(F.relu(out)) return output
训练:
import os os.environ['CUDA_VISIBLE_DEVICES']='0' t.cuda.set_device(0) BiLSTMmodel = BiLSTM(embed_weight) criterion = nn.CrossEntropyLoss() optimizer = optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, BiLSTMmodel.parameters()), lr=0.001) train(train_loader, val_loader, BiLSTMmodel, 'cuda', criterion, optimizer, num_epochs=20)

相关文章推荐
- 【NLP】TensorFlow实现CNN用于文本分类(译)
- 【NLP】TensorFlow实现CNN用于中文文本分类
- nlp(一)用tgrocery实现文本分类
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
- 【机器学习PAI实践七】文本分析算法实现新闻自动分类
- Yoon Kim的textCNN讲解,以及tensorflow实现,CNN文本分类
- CNN中文文本分类-基于TensorFlow实现
- CNN tensorflow text classification CNN文本分类的例子
- 字符级卷积神经网络(Char-CNN)实现文本分类--模型介绍与TensorFlow实现
- 卷积神经网络(CNN)在TensorFlow文本分类中的应用Implementing a CNN for Text Classification in TensorFlow
- TensorFlow使用CNN实现中文文本分类
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
- 在TensorFlow中实现文本分类的CNN
- NLP实践九:Attention原理与文本分类代码实践
- 详解文本分类之多通道CNN的理论与实践
- 文本分类需要CNN? No!fastText完美解决你的需求(前篇)
- 卷积神经网络在NLP领域的实践:文本分类[转]
- cnn、rnn实现中文文本分类(基于tensorflow)
- 详解文本分类之DeepCNN的理论与实践