1st day 初级算法梳理
1st day 初级算法梳理
任务一
线性回归算法梳理
学习内容
- 机器学习的一些概念
有监督、无监督、泛化能力、过拟合欠拟合(方差和偏差以及各自解决办法)、交叉验证
1.1 有监督:
Supervised learning is the Data mining task of inferring a function from labeled training data.(重点 labeled training data)
The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an
input object (typically a vector) and a desired output value (also called thesupervisory signal.
训练数据由一组训练实例组成。在监督学习中,每一个例子都是一对由一个输入对象(通常是一个向量)和一个期望的输出值(也被称为监督信号)。
有监督学习算法分析训练数据,并产生一个推断的功能,它可以用于映射新的例子。一个最佳的方案将允许该算法正确地在标签不可见的情况下确定类标签。
With supervised learning, a model is given a set of labeled training data.
The model learns to make predictions based on this training data, so the more training data the model has
access to, the better it gets at making predictions. With training data, the outcome is already known.
The predictions from the model and known outcomes are compared, and the model’s parameters are changed until
the two align. The point of training is to develop the model’s ability to successfully generalize.
1.2 无监督:
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。
很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
Unsupervised learning is a term used for Hebbian learning, associated to learning without a teacher,
also known as self-organization and a method of modelling the probability density of inputs.
The cluster analysis as a branch of machine learning that groups the data that has not been labelled,
classified or categorized. Instead of responding to feedback, cluster analysis identifies commonalities
in the data and reacts based on the presence or absence of such commonalities in each new piece of data.
1.3 泛化能力
泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。 学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,
经过训练的网络也能给出合适的输出,该能力称为泛化能力。
泛化能力(generalization ability)是指一个机器学习算法对于没有见过的样本的识别能力。我们也叫做举一反三的能力,或者叫做学以致用的能力。
Generalization refers to your model’s ability to adapt properly to new, previously unseen data, drawn from the same
distribution as the one used to create the model.
1.4.1 过拟合:模型泛化能力很差
我们训练一个机器学习算法也是如此,通过感性的告诉机器一个加上一个等于两个,之后算法通过自己的学习,推广计算多位数的加减法,多位数的加减法是无穷多个的,如果机器在不断的测试中都能够算对,那么我们认为机器已经总结出了加法的内部规律并且能够学以致用,如果说机器只会计算你给机器看过的比如3+3=6,而不会计算没有教过的8+9=17,那么我们认为机器只是死记硬背,并没有学以致用的能力,也就是说泛化能力非常的低,同时我们也把这种现象叫做这个算法过拟合(over-fitting)了。(过拟合是一种分类器会发生的现象,而泛化能力可以理解为对分类器的一种性能的评价)
过拟合通常可以理解为,模型的复杂度要高于实际的问题,所以就会导致模型死记硬背的记住,而没有理解背后的规律。就比如说人脑要比唐诗复杂得多,即使不理解内容,我们也能背下来,但是理解了内容和写法对于我们理解记忆其他唐诗有好处,如果死记硬背那么就仅仅记住了而已。
作者:Liu-Kevin
来源:CSDN
Overfitting is a modeling error which occurs when a function is too closely fit to a limited set of data points. Overfitting the model generally takes the form of making an overly complex model to explain idiosyncrasies in the data under study. In reality, the data often studied has some degree of error or random noise within it. Thus attempting to make the model conform too closely to slightly inaccurate data can infect the model with substantial errors and reduceits predictive power.
Reason:
造成原因主要有以下几种:
1 训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2 训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
3 模型过于复杂。模型太复杂,已经能够死记硬背记录下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
Solution:
1)重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小
3)采用正则化方法。正则化方法包括L0正则、L1正则和L2正则,而正则一般是在目标函数之后加上对于的范数。但是在机器学习中一般使用L2正则,下面看具体的原因。
L0范数是指向量中非0的元素的个数。L1范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)。两者都可以实现稀疏性,既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。所以大家才把目光和万千宠爱转于L1范数。
作者:will_duan
来源:CSDN
原文:https://www.geek-share.com/detail/2689571260.html
版权声明:本文为博主原创文章,转载请附上博文链接!
They are three types of regularization technique to overcome overfitting.
a) L1 regularization (also called Lasso regularization / panelization.)
b) L2 regularization (also called Ridege regularization/ penalization.)
c) Elastic net
知乎:1. regularization:L2用的最多,L1也有用的。
2. dropout:一大利器。3. early stop:结合cross validation使用。4. cross validation:当数据量较小的时候,应该是用来减轻 overfitting 最好的方式了吧。
作者:小华仔
链接:https://www.zhihu.com/question/26898675/answer/151101888
1.4.2欠拟合(high-bias)
欠拟合(under-fitting)是和过拟合相对的现象,可以说是模型的复杂度较低,没法很好的学习到数据背后的规律。就好像开普勒在总结天体运行规律之前,他的老师第谷记录了很多的运行数据,但是都没法用数据去解释天体运行的规律并预测,这就是在天体运行数据上,人们一直处于欠拟合的状态,只知道记录过的过去是这样运行的,但是不知道道理是什么。
作者:Liu-Kevin
Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying trend of the data.Intuitively, underfitting occurs when the model or the algorithm does not fit the data well enough. Specifically, underfitting occurs if the model or algorithm shows low variance but high bias.
#Solution:
尝试减少特征的数量(该方法适用于****过拟合现象时,解决高方差);
尝试获得更多的特征(该方法适用于欠拟合现象时,解决高偏差);
尝试增加多项式特征(该方法适用于欠拟合现象时,解决高偏差);
尝试减小正则化程度λ(该方法适用于欠拟合现象时,解决高偏差);
尝试增加正则化程度λ(该方法适用于过拟合现象时,解决高方差);
作者:nightwish夜愿
链接:https://www.jianshu.com/p/9b6b0d6d3bd0
来源:简书
#Question: what is the difference between variance and bias?
#Variance:就是方差
In probability theory and statistics, variance is the expectation of the squared deviation of a random variable
from its mean. Informally, it measures how far a set of (random) numbers are spread out from their average value.
#bias:Bias refers to the tendency of a measurement process to over- or under-estimate the value of a population parameter.
拓展:不收敛一般是形容一些基于梯度下降算法的模型,收敛是指这个算法有能力找到局部的或者全局的最小值,比如找到使得预测的标签和真实的标签最相近的值,也就是二者距离的最小值),从而得到一个问题的最优解。如果说一个机器学习算法的效果和瞎蒙的差不多那么基本就可以说这个算法没有收敛,也就是根本没有去学习。
作者:Liu-Kevin
这个图很好
https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76
 1.5 交叉验证 cross-validation
1.5 交叉验证 cross-validation
https://zhuanlan.zhihu.com/p/24825503
交叉验证(Cross Validation)是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(training set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。常见的交叉验证方法如下:
作者:holybin
原文:https://blog.csdn.net/holybin/article/details/27185659
2.线性回归的原理
因为我们对于一个数据集,不明确其之间的关系,所以需要构造一个函数,进行拟合数据,拟合后便可以实现取任意点进行值的预测。所以这里我们采用线性的函数进行拟合,和求解这个线性函数的参数的过程,以及将参数最优化就是线性回归算法在干的事情。

3. 线性回归损失函数、代价函数、目标函数
**3.1损失函数:**说白了,就是求每个点到我们求解的这条直线的距离差的总和。因为不是所有点都在直线上,所有你要衡量这条直线是不是最好的拟合函数,你需要对每个点,求到这条直线的距离,然后将所有的距离相加,得到的距离总和,使得总和最小的直线就是最好的拟合直线。而我们损失函数所用的是平
1bb8b
方差误差求和。现在我们需要根据给定的X求解W的值,这里采用最小二乘法。何为最小二乘法,其实很简单。我们有很多的给定点,这时候我们需要找出一条线去拟合它,那么我先假设这个线的方程,然后把数据点代入假设的方程得到观测值,求使得实际值与观测值相减的平方和最小的参数。对变量求偏导联立便可求。

3.2 代价函数
Loss Function 是定义在单个样本上的,算的是一个样本的误差。
Cost Function 是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
Object Function(目标函数 )定义为:Cost Function + 正则化项。
作者:别拽我红领巾
链接:https://www.zhihu.com/question/52398145/answer/302108715
3.3 目标函数
In order to find the optimal solution, we need some way of measuring the quality of any solution. This is done via what is known as an objective function, with “objective” used in the sense of a goal. This function, taking data and model parameters as arguments, can be evaluated to return a number. Any given problem contains some parameters which can be changed; our goal is to find values for these parameters which either maximize or minimize this number.
(from:http://kronosapiens.github.io/blog/2017/03/28/objective-functions-in-machine-learning.html)
3.4 风险函数

4. 优化方法(梯度下降法、牛顿法、拟牛顿法等)
4.1梯度下降法
Gradient descent is a first-order iterative optimization algorithm for finding the minimum of a function. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient (or approximate gradient) of the function at the current point. If, instead, one takes steps proportional to the positive of the gradient, one approaches a local maximum of that function; the procedure is then known as gradient ascent.
(from wikipedia)
简单来讲,凸优化问题是指只存在一个最优解的优化问题,即任何一个局部最优解即为全局最优解
非凸优化是指在解空间中存在多个局部最优解,而全局最优解是其中的某一个局部最优解
4.2牛顿法与拟牛顿法(看不懂)
牛顿法也是机器学习中用的比较多的一种优化算法。牛顿法的基本思想是利用迭代点处的一阶导数(梯度)和二阶导数(Hessen矩阵)对目标函数进行二次函数近似,然后把二次模型的极小点作为新的迭代点,并不断重复这一过程,直至求得满足精度的近似极小值。牛顿法的速度相当快,而且能高度逼近最优值。牛顿法分为基本的牛顿法和全局牛顿法。
(作者:zhiyong_will 来源:CSDN )
拟牛顿法:
5、线性回归的评估指标
A. R-Squared
B. Adjusted R-Squared
C. F Statistics
D. RMSE / MSE / MAE
答案:ABCD
解析:R-Squared 和 Adjusted R-Squared 都可以用来评估线性回归模型。
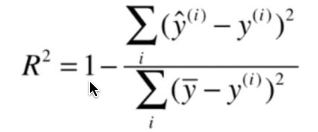
F Statistics 是指在零假设成立的情况下,符合F分布的统计量,多用于计量统计学中。
RMSE 指的是均方根误差:
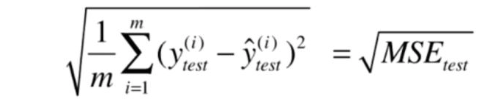
MSE 指的是均方误差:
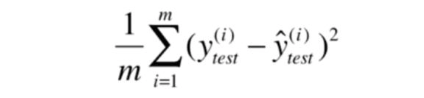
MAE 指的是评价绝对误差:
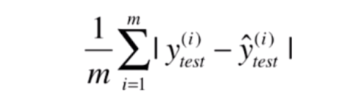
(作者:张荣华_CSDN 来源:CSDN 原文:https://blog.csdn.net/zrh_CSDN/article/details/81190221 )
6、sklearn参数详解
参数含义:
1.fit_intercept:布尔值,指定是否需要计算线性回归中的截距,即b值。如果为False,
那么不计算b值。
2.normalize:布尔值。如果为False,那么训练样本会进行归一化处理。
3.copy_X:布尔值。如果为True,会复制一份训练数据。
4.n_jobs:一个整数。任务并行时指定的CPU数量。如果取值为-1则使用所有可用的CPU。
5.coef_:权重向量
6.intercept_:截距b值
 作者:随遇而安_小强 来源:CSDN 原文:https://www.geek-share.com/detail/2741778471.html
作者:随遇而安_小强 来源:CSDN 原文:https://www.geek-share.com/detail/2741778471.html
!

- 初级算法梳理——线性回归
- 机器学习—线性回归—初级算法梳理01
- 初级算法梳理
- Datawhale-初级算法梳理-Day2-逻辑回归算法梳理
- 初级算法梳理 任务一 线性回归算法梳理
- 初级算法梳理(Day1)
- 初级算法梳理任务2打卡
- Datawhale 初级算法梳理 - 线性回归算法梳理
- Datawhale-初级算法梳理-Day1-线性回归算法梳理
- 机器学习初级算法梳理一
- 第六期-初级算法梳理-任务一 线性回归算法梳理
- 机器学习初级算法梳理二
- 『算法学习笔记』1st day. 顺序结构程序设计
- 逻辑回归算法梳理
- 算法入门——初级队列
- 【数据结构和算法】Day 13
- 梳理OpenCV各立体匹配算法的分类和理论基础(更新中)
- (算法)初级排序算法
- 算法第四版学习笔记之初级排序算法
- (转)求质数算法的N种境界[1] - 试除法和初级筛法