机器学习100天-K邻近法 [KNN算法思想 + KNeighborsClassifier]
2019-01-18 15:33
183 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/STILLxjy/article/details/86540944
K-NN算法计算过程:

上述过程(1)(2)(3)在寻找k个最近点时,采用了暴力搜索的思想。
也可以采取其他算法寻找处最近的k个点,如:BallTree, KDTree等。
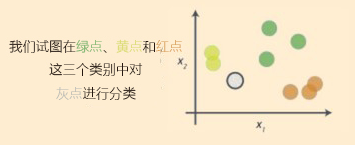
计算流程事例:
(1)
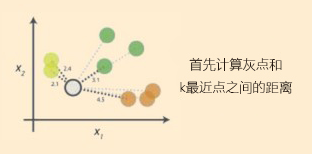
(2)
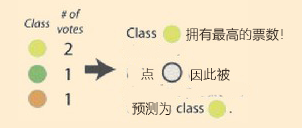
(3)

(4)
sklearn.neighbors.KNeighborsClassifier 参数说明:
官方API:https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n_jobs=None, **kwargs)[source]
n_neighbors: 选择最邻近点的数目k
weights: 邻近点的计算权重值,uniform代表各个点权重值相等
algorithm: 寻找最邻近点使用的算法
leaf_size: 传递给BallTree或kTree的叶子大小,这会影响构造和查询的速度,以及存储树所需的内存。
p: Minkowski度量的指数参数。p = 1 代表使用曼哈顿距离 (l1),p = 2 代表使用欧几里得距离(l2),
metric: 距离度量,点之间距离的计算方法。
metric_params: 额外的关键字度量函数。
n_jobs: 为邻近点搜索运行的并行作业数。
K-NN实现:
1:到入库
2:加载.csv文件数据
3:将数据分为 训练集和测试集
4:将数据标准化
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:,[2,3]].values
Y = dataset.iloc[:,4].values
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.25, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
5:定义 KNeighborsClassifier 模型,并载入训练数据进行训练
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2) classifier.fit(X_train, Y_train)
6:测试 测试集
y_pred = classifier.predict(X_test)
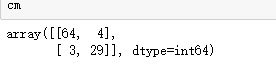
7:使用混淆矩阵,观测预测效果(有关混淆矩阵的介绍可以看上一篇有关逻辑回归中的详细讲解)
from sklearn.metrics import confusion_matrix cm = confusion_matrix(Y_test,y_pred)
KNN:


相关文章推荐
- 机器学习之KNN算法思想及其实现
- 机器学习——分类算法1:k-近邻 (KNN) 思想和代码
- 机器学习集成算法:XGBoost思想
- 机器学习之KNN 算法
- 机器学习中的KNN算法
- 【机器学习 3】KNN算法实现梳理- Be based on“约会对象”、“手写识别”
- 机器学习十大算法的每个算法的核心思想、工作原理、适用情况及优缺点
- 机器学习实战第二章——KNN算法(源码解析)
- 用Python开始机器学习(4:KNN分类算法)
- 【机器学习】使用Scikit-Learn库实现K-近邻(KNN)算法
- 机器学习专题(一)——KNN算法的python实现
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法
- 机器学习:KNN算法
- 机器学习十大算法的核心思想、工作原理、适用 情况及优缺点
- 机器学习具体算法系列之最近邻居法(KNN算法)
- 机器学习十大算法的核心思想、工作原理、适用 情况及优缺点
- 机器学习十大算法的每个算法的核心思想、工作原理、适用情况及优缺点
- 机器学习:kNN近邻算法
- 机器学习集成算法:XGBoost思想
- Python机器学习实战笔记之KNN算法