AWS Athena 分析日志
2019-01-02 11:43
3435 查看
AWS里面可以用Athena来分析S3里面保存的日志,他把日志转换成数据库表的格式,这样就可以通过sql语句进行查询了。这个功能和在windows服务器上用logparser来分析Exchange或者IIS的日志很相似。
下面做个演示,通过Cloudtrail记录管理日志,然后通过Athena来查询日志内容。
首先选择CloudTrail, CloudTrail 是一个日志记录的服务,他和cloudwatch的区别在于这个服务更多是侧重于审计,他的内容都是关于什么时候,什么账号,从什么IP上进行了什么操作。

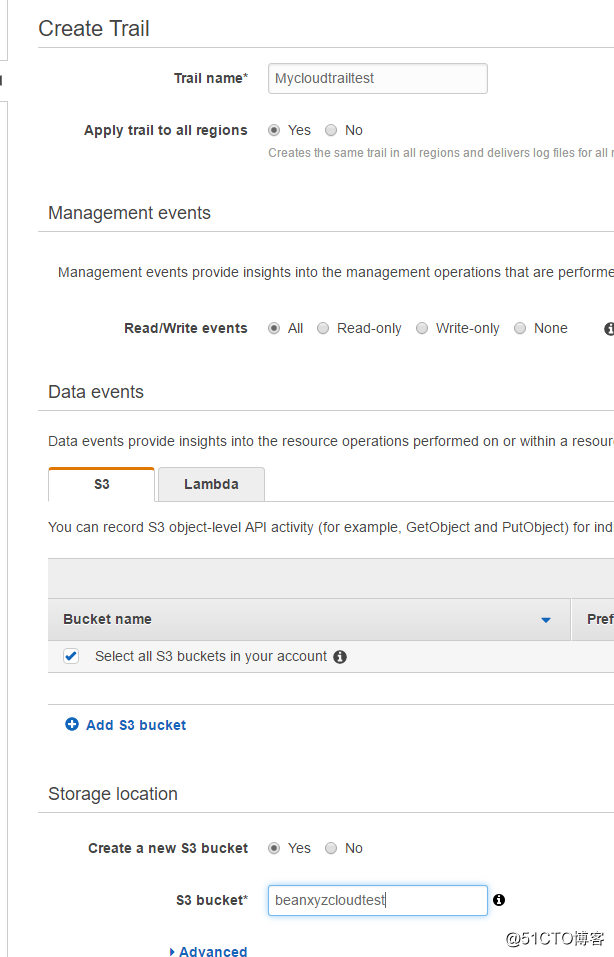
点击 Create Trail

取个名字, 创建一个新的S3 bucket来保存日志
创建好之后可以看见他自动已经在记录最新的日志了

然后选择 Athena

跳过向导,直接进入查询器的编辑器,这里是编辑SQL语句的地方。这里我直接创建一个的数据库

下面来创建一个表,从指定的S3 Bucket里面获取数据。
我们可以通过向导创建,但是比较繁琐

比较容易的是通过脚本创建,注意最后一行S3存储桶的地址
CREATE EXTERNAL TABLE cloudtrail_logs ( eventversion STRING, useridentity STRUCT< type:STRING, principalid:STRING, arn:STRING, accountid:STRING, invokedby:STRING, accesskeyid:STRING, userName:STRING, sessioncontext:STRUCT< attributes:STRUCT< mfaauthenticated:STRING, creationdate:STRING>, sessionissuer:STRUCT< type:STRING, principalId:STRING, arn:STRING, accountId:STRING, userName:STRING>>>, eventtime STRING, eventsource STRING, eventname STRING, awsregion STRING, sourceipaddress STRING, useragent STRING, errorcode STRING, errormessage STRING, requestparameters STRING, responseelements STRING, additionaleventdata STRING, requestid STRING, eventid STRING, resources ARRAY<STRUCT< ARN:STRING, accountId:STRING, type:STRING>>, eventtype STRING, apiversion STRING, readonly STRING, recipientaccountid STRING, serviceeventdetails STRING, sharedeventid STRING, vpcendpointid STRING ) ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://mycloudtrailbucket-faye/AWSLogs/757250003982/';

创建表成功的样子

下面我们可以进行一个简单的查询,结果如下。


相关文章推荐
- UltraEdit很强大的日志分析工具
- 日志分析系统 --- AWStats
- 如何分析安卓系统日志
- nginx日志简单分析工具
- 基于C++高性能、跨平台日志模块的分析与实现
- (1)Storm实时日志分析实战--项目准备
- MySQL日志种类分析
- ELK日志分析平台的搭建
- offline日志分析(1)
- 用Grafana为Elasticsearch做日志分析
- LS1021ATWR开发板启动日志分析
- RHEL 5基础篇—分析系统日志
- 发现一款日志分析工具AWStats,能取代网站统计程序
- 海量Web日志分析 用Hadoop提取KPI统计指标
- squid日志分析软件sarg的安装和使用
- MySQL系列之三:慢查询日志及分析
- 纯java语言分析网站后台日志IP排序处理
- 安装日志分析工具awstats
- iOS获取用户设备崩溃日志并分析