Spark 2.4 之 standalone 集群搭建
2018-12-21 23:10
609 查看
本文参考官方文档: http://spark.apache.org/docs/latest/spark-standalone.html
1.预先搭建3台hadoop 的集群
| SERVER INFO | version |
|---|---|
| 192.168.1.10 | RHL6.8 & Hadoop 2.7.3 |
| 192.168.1.11 | RHL6.8 & Hadoop 2.7.3 |
| 192.168.1.12 | RHL6.8 & Hadoop 2.7.3 |
2. 在所有节点中安装spark
此处可以参考 https://blog.csdn.net/chenxu_0209/article/details/84948302
3. 配置各个节点之间的SSH key
生成RSA KEY
[spark@hadoop01 ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/spark/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/spark/.ssh/id_rsa. Your public key has been saved in /home/spark/.ssh/id_rsa.pub. The key fingerprint is: 65:34:15:20:57:35:cf:c7:bf:8b:1c:94:46:d4:7f:34 spark@hadoop01 The key's randomart image is: +--[ RSA 2048]----+ | . =++++ | | + .. E.| | o . .B| | o . . =| | S + o| | o .| | . . | | . o .| | o . | +-----------------+
将生成的RSA key 拷贝到 ~/.ssh/authorized_keys 保存到每个节点中
***注意authorized_keys这个文件不要手动创建 拷贝id_rsa.pub 即可[spark@hadoop01 .ssh]$ vi authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA1EYdPds/v/1Qh8w5tBlpUcWMJJVBlBTzZK3Q/OhqGERdKmUu+9qw29VRB9+wtYX1vPl+t02zIGIYfZ8IjCaO56g1xc34NRF7Xe+w1H3EU3k5jwzsuqS8/BDz56QCia7gIZKJJAO3Xf+U9oJcin1paSWg2FmnXFbuyNEXaPptYVyjpSUJeZZvB50gqA46VOD3h3O1fGZ+d7WZ6aK6OvTgJdMaz8m0H1yCcF5vz08jKuDpVdBZX01nL8cFDz711FifFwZTMnSG5QnimrQ3FfCcyQwkQJQSqJ76v2H+CbWW5goA77AeV9GAs0Lqkk76eOj5/A1is0Yl45y2EZey0YClww== spark@hadoop01 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAwKotX+y0FC4byiI9ItDR0jyjD/oPQHJpbTtFg4LUyGk0v9AaMo5b9hKWrX7nc989oKLz+lQYyoTEtJJ2zQ0JwNnVp1pBciQT92BIeRunvGuWnRKV19GZfLXy8xX8cTf+YYVSfkUtCxKrFgflVInRkNn2KeIsfTIg/dLVICkBEGXs0d0JfNgJBjA/dPV+1L3GAyOT0zJj62L3gE6a+1TcORmMQepHV5UZkW2RrF8rZxHULVoK3pcdHoMYQhhzJJBl+6ZcXRFKXAAElEKlcn6z7fGTqh1pvihuxYwUcjTZYDgNgdBwobZ/H5OP0ERoOgkbGaRCdq8pQBisNc6cj76oaw== spark@oggserver01 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA1O9CfvVCXkE+5dQvsEuRfDvSf1h9xUQhk+LOMLS1BlKdxNmwhbcCb2E06ADjtOwSzldwFnZUxKnFIOyK5vJivKSzGlcOzVByEG58DNtfxqNQTSCxRsphAl8ZZA4sF1K5tYrFYca7iSJbJmdgw95Rmixty94tn8BJT8h2oePmnYgoARythj5BLmf2D6sXXGJuDLrjE9VabgPRUfpJOIr42XsdsnNZsbxLxiMP54xgXr4kpqdhjGvKOq61vbFLmIU3Wpbt+4IPONLolK5YdcM8mvS+JpQKTGslM0dkkqhAEBlizAr58OKQp0dmI9iTiFj82xRsrgP3lY1mlxaO45R4iw== spark@oggserver02
测试 ssh
[spark@hadoop01 .ssh]$ ssh oggserver01 date Fri Dec 21 05:15:04 PST 2018 [spark@hadoop01 .ssh]$ ssh oggserver02 date Fri Dec 21 05:15:06 PST 2018
4. 修改$SPARK_HOME/conf/spark-env.sh
配置master和worker 节点信息SPARK_MASTER_HOST=hadoop01 SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=2 SPARK_WORKER_MEMORY=512m SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 SPARK_WORKER_INSTANCE=1配置slave 节点列表
[spark@hadoop01 conf]$ mv slaves.template slaves.sh [spark@hadoop01 conf]$ vi slaves.sh oggserver01 oggserver02
5. 启动master 节点
[spark@hadoop01 sbin]$ ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /home/spark/spark-2.4.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-hadoop01.out
此时可以通过web界面访问: http://hadoop01:8080/
注意此时worker 列表为0 ,因为尚未启动worker
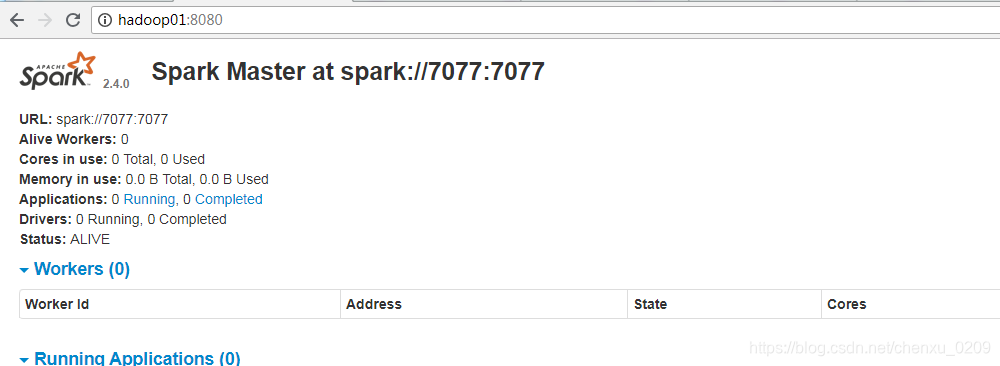
6. 启动slave 节点
[spark@oggserver01 sbin]$ ./start-slave.sh spark://hadoop01:7077 starting org.apache.spark.deploy.worker.Worker, logging to /home/spark/spark-2.4.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-oggserver01.out [spark@oggserver02 sbin]$ ./start-slave.sh spark://hadoop01:7077 starting org.apache.spark.deploy.worker.Worker, logging to /home/spark/spark-2.4.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-oggserver02.out
此时可以通过web界面查看worker 节点列表
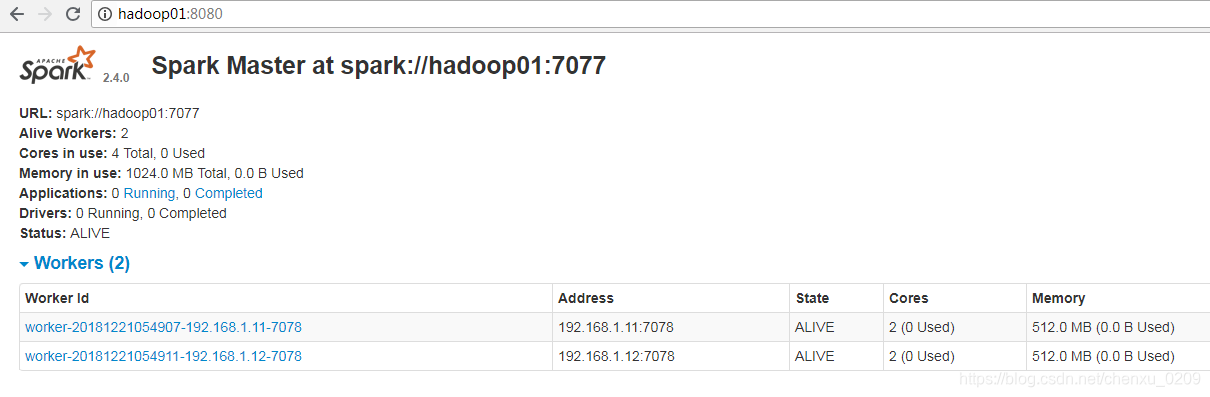
6. SPARK-SHELL 连接standalone cluster
[spark@hadoop01 bin]$ ./spark-shell --master spark://hadoop01:7077 2018-12-21 05:55:51 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://hadoop01:4040 Spark context available as 'sc' (master = spark://hadoop01:7077, app id = app-20181221055610-0000). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144) Type in expressions to have them evaluated. Type :help for more information. scala>
编写测试程序
scala> val rdd = sc.textFile("/user/hadoop/worddir/word.txt");
rdd: org.apache.spark.rdd.RDD[String] = /user/hadoop/worddir/word.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> val tupleRDD = rdd.flatMap(line => {line.split(" ")
| .toList.map(word => (word.trim,1))
| });
tupleRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[2] at flatMap at <console>:25
scala> val resultRDD :org.apache.spark.rdd.RDD[(String,Int)] =tupleRDD.reduceByKey((a,b)=> a + b);
resultRDD: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[3] at reduceByKey at <console>:25
scala> resultRDD.foreach(elm => println(elm._1+"="+elm._2));
图形界面观察输出
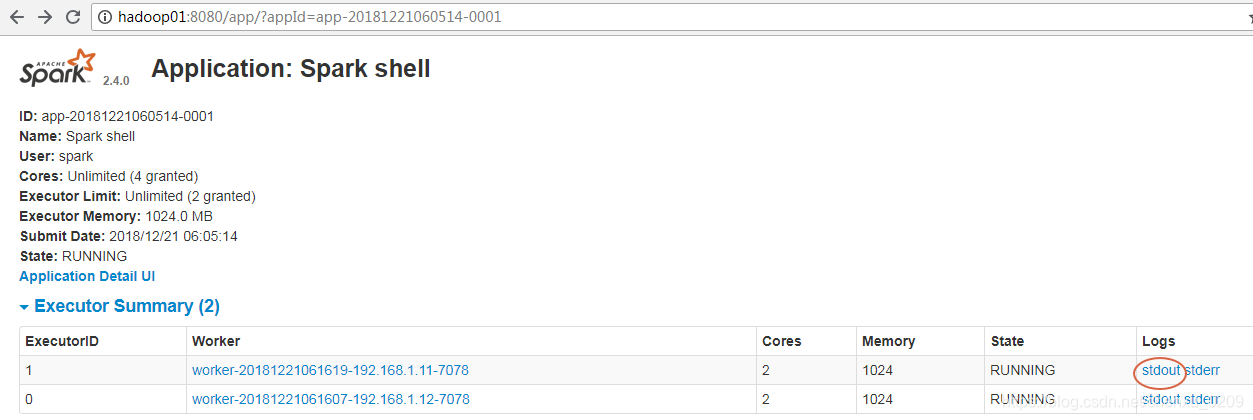
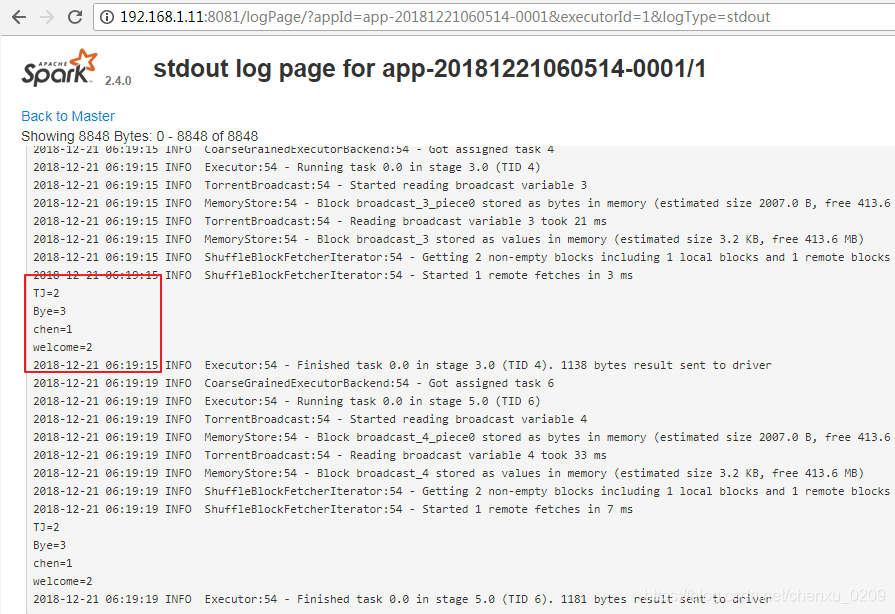
如果遇到错误
Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2018-12-21 06:04:49 WARN TaskSchedulerImpl:66 - Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
修改worker的内存 512m-> 1g

相关文章推荐
- spark1.3.0-hadoop2.4集群环境搭建(Standalone)
- Spark集群搭建_Standalone
- spark2.2.0搭建standalone集群环境
- Spark1.6.1集群环境搭建——Standalone模式HA
- Spark 集群搭建从零开始之3 Spark Standalone集群安装、配置与测试
- Spark自带的集群模式(Standalone),Spark/Spark-ha集群搭建
- spark集群搭建,standalone
- Spark1.2.1集群环境搭建——Standalone模式
- (一) 从零开始搭建Spark Standalone集群环境搭建
- spark2.0.2基于hadoop2.4搭建分布式集群
- Spark学习之(二)Spark 集群环境搭建(standalone)
- spark1.6.0+Hadoop2.6.0+Scala-2.11.7 搭建分布式集群
- 搭建Spark的单机版集群
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
- (二)win7下用Intelij IDEA 远程调试spark standalone 集群
- Apache Spark介绍及集群搭建
- Spark修炼之道(进阶篇)——Spark入门到精通:第一节 Spark 1.5.0集群搭建
- Spark集群搭建
- Spark集群基于Zookeeper的HA搭建部署
- hadoop2.4集群的搭建