Spark自带的集群模式(Standalone),Spark/Spark-ha集群搭建
2017-07-05 19:01
567 查看
1、Spark自带的集群模式
对于Spark自带的集群模式,Spark要先启动一个老大(Master),然后老大Master和各个小弟(Worker)进行通信,其中真正干活的是Worker下的Executor。关于提交任务的,需要有一个客户端,这个客户端叫做Driver.这个Driver首先和Master建立通信,然后Master负责资源分配,然后让Worker启动Executor,然后Executor和Driver进行通信。效果图如下: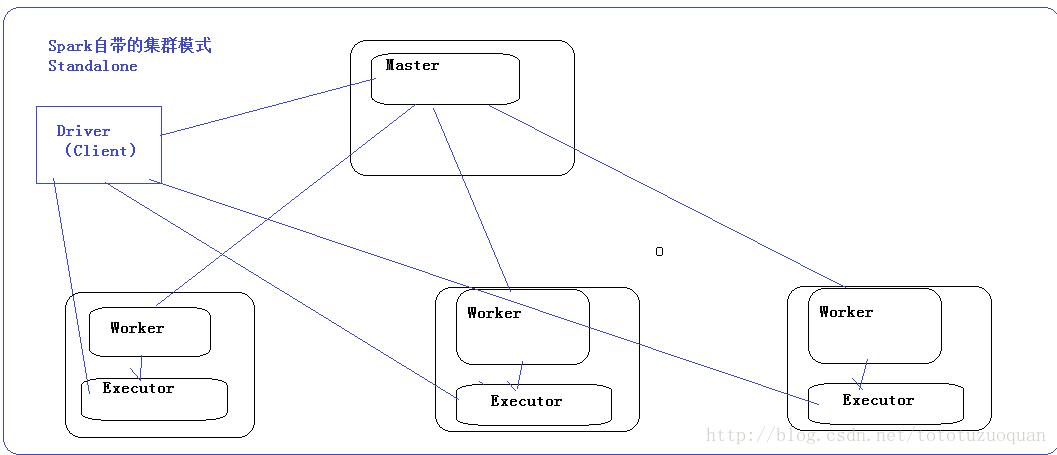
2、Spark集群搭建(先非HA—>再HA)
2.1. 机器准备
A:准备5台Linux服务器(hadoop1(Master),hadoop2(Master),hadoop3(worker),hadoop4(worker),hadoop5(worker))B:安装好/usr/local/jdk1.8.0_73
2.2. 下载Spark安装包
下载地址:http://spark.apache.org/downloads.html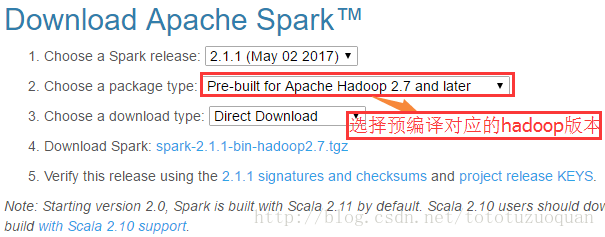
https://d3kbcqa49mib13.cloudfront.net/spark-2.1.1-bin-hadoop2.7.tgz
上传解压安装包
上传spark-2.1.1-bin-hadoop2.7.tgz安装包到Linux上的/home/tuzq/software

解压安装包到指定位置
[root@hadoop1 software] cd /home/tuzq/software [root@hadoop1 software] tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /home/tuzq/software [root@hadoop1 software]# cd spark-2.1.1-bin-hadoop2.7 [root@hadoop1 spark-2.1.1-bin-hadoop2.7]# ls bin conf data examples jars LICENSE licenses NOTICE python R README.md RELEASE sbin yarn [root@hadoop1 spark-2.1.1-bin-hadoop2.7]#
2.3. 配置Spark
进入到Spark安装目录cd /home/tuzq/software/spark-2.1.1-bin-hadoop2.7
进入conf目录并重命名并修改spark-env.sh.template文件
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# cd conf/ [root@hadoop1 conf]# pwd /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/conf [root@hadoop1 conf]# mv spark-env.sh.template spark-env.sh [root@hadoop1 conf]# vim spark-env.sh
在该配置文件中添加如下配置
export JAVA_HOME=/usr/local/jdk1.8.0_73 export SPARK_MASTER_IP=hadoop1 export SPARK_MASTER_PORT=7077
保存退出
重命名并修改slaves.template文件
mv slaves.template slaves vi slaves
在该文件中添加子节点所在的位置(Worker节点)
hadoop3
hadoop4
hadoop5
保存退出
配置环境变量:
vim /etc/profile #set spark env export SPARK_HOME=/home/tuzq/software/spark-2.1.1-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin source /etc/profile
将配置好的Spark拷贝到其他节点上
cd /home/tuzq/software scp -r spark-2.1.1-bin-hadoop2.7 root@hadoop2:$PWD scp -r spark-2.1.1-bin-hadoop2.7 root@hadoop3:$PWD scp -r spark-2.1.1-bin-hadoop2.7 root@hadoop4:$PWD scp -r spark-2.1.1-bin-hadoop2.7 root@hadoop5:$PWD
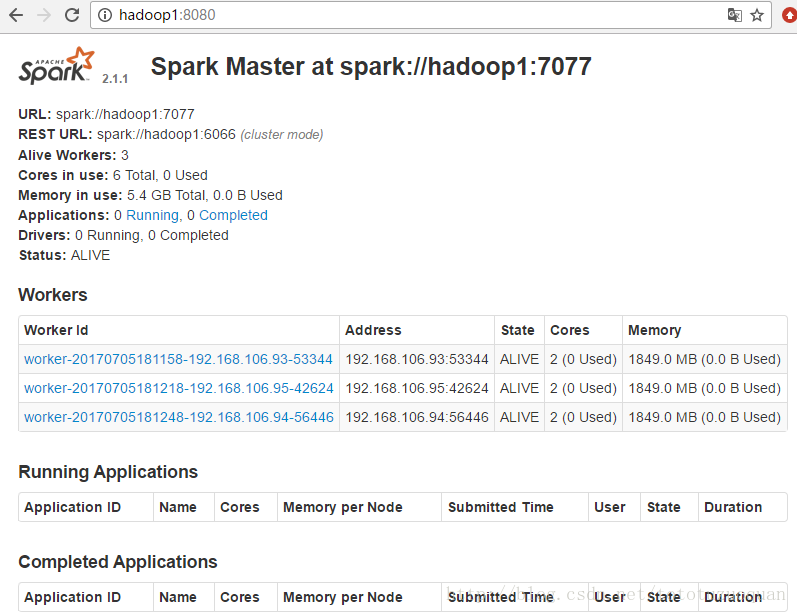
Spark集群配置完毕,目前是1个Master,3个Work,在hadoop1上启动Spark集群
/home/tuzq/software/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
运行结果:

如果想停止,就用:
/home/tuzq/software/spark-2.1.1-bin-hadoop2.7/sbin/stop-all.sh
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://hadoop1:8080/
2.4.Spark-Ha集群配置
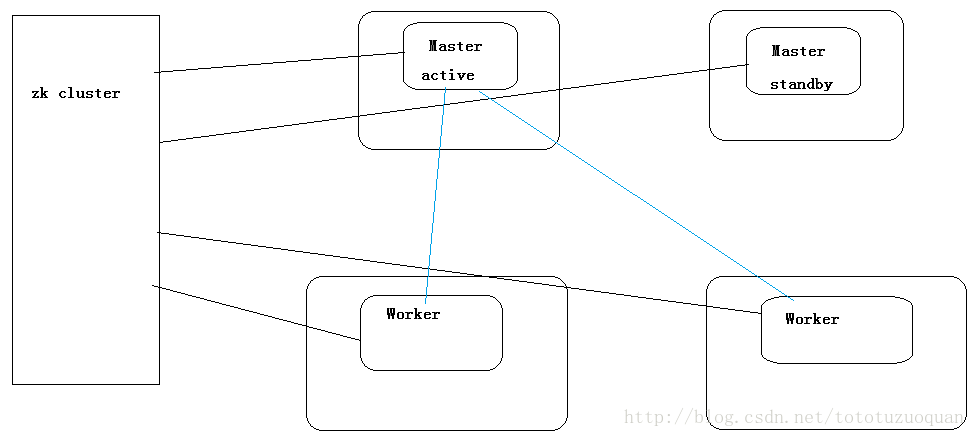
到此为止,Spark集群安装完毕,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单:Spark集群规划:hadoop1,hadoop2是Master;hadoop3,hadoop4,hadoop5是Worker
安装配置zk集群,并启动zk集群(hadoop11,hadoop12,hadoop13)
停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS=”-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop11,hadoop12,hadoop13 -Dspark.deploy.zookeeper.dir=/spark”
效果如下:

将修改的配置同步到hadoop2,hadoop3,hadoop4,hadoop5这些机器上
[root@hadoop1 conf]# pwd /home/tuzq/software/spark-2.1.1-bin-hadoop2.7/conf [root@hadoop1 conf]# scp -r * root@hadoop2:$PWD [root@hadoop1 conf]# scp -r * root@hadoop3:$PWD [root@hadoop1 conf]# scp -r * root@hadoop4:$PWD [root@hadoop1 conf]# scp -r * root@hadoop5:$PWD
1. 在hadoop1节点上修改slaves配置文件内容指定worker节点(本篇博客上hadoop3,hadoop4,hadoop5为worker,hadoop1和hadoop2 master)
2. 在hadoop1上执行sbin/start-all.sh脚本,然后在hadoop2上执行sbin/start-master.sh启动第二个Master(注意在启动之前先停止启动了的单集群)
[root@hadoop2 ~]# cd $SPARK_HOME [root@hadoop2 spark-2.1.1-bin-hadoop2.7]# sbin/start-all.sh

[root@hadoop2 ~]# cd $SPARK_HOME [root@hadoop2 spark-2.1.1-bin-hadoop2.7]# sbin/start-master.sh

3、接着访问http://hadoop1:8080/:
效果如下:
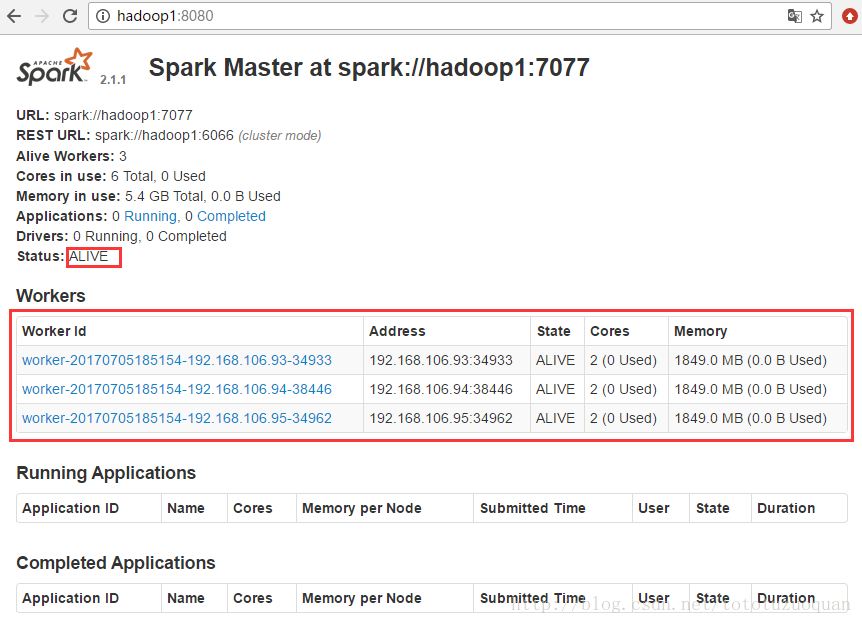
上面的状态是:ALIVE状态
接着访问http://hadoop2:8080/:
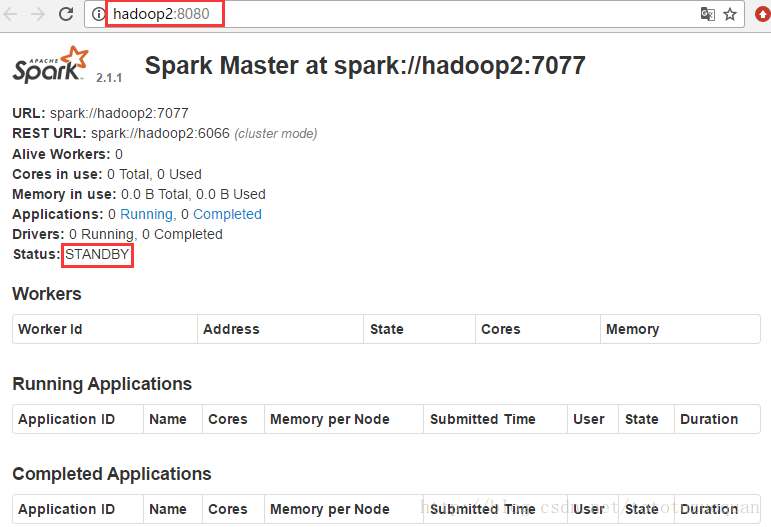
上面的状态是:STANDBY状态,通过上面的这些现象可以知道Spark集群已经搭建成功

相关文章推荐
- Spark1.6.1集群环境搭建——Standalone模式HA
- Spark1.2.1集群环境搭建——Standalone模式
- Spark集群基于Zookeeper的HA搭建部署笔记
- 搭建高可用的redis集群,避免standalone模式带给你的苦难
- 搭建Spark集群(独立模式)
- Spark集群搭建+基于zookeeper的高可用HA
- 关于Spark下的第二种模式——standalone搭建
- spark集群搭建,standalone
- Spark集群基于Zookeeper的HA搭建部署
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
- Spark集群中HA环境搭建
- Spark集群独立模式HA
- zeppelin 无法连接一个已有的standalone模式的spark集群
- 在spark开发环境中使用Standalone模式调试集群运行
- Spark新手入门——3.Spark集群(standalone模式)安装
- 深入理解Spark 2.1 Core (八):Standalone模式容错及HA的原理与源码分析
- SequoiaDB分布式数据库集群模式搭建Spark
- Spark集群搭建_Standalone
- Spark集群基于Zookeeper的HA搭建部署
- spark-0.8.0源码剖析--standalone模式集群并行和单机并行