python爬虫----urllib、requests、re、os模块实现爬取图片
2018-12-05 17:01
766 查看
python提供了很多关于爬虫的库比如说urllib、requests,也有一些框架比如说scrapy。所以用python来实现爬虫是一件很方便快捷的事情。接下来让我们看看如何爬取网页上的各种图片。
环境:python3.7
使用模块:urllib,requests,os,re
我们试爬的网站是百度贴吧,第一种方法是直接使用urllib模块和正则表达式来获得html信息和获取图片:
#第一种方法urllib.request+os+re
import urllib.request
import os
import random
import re
def url_open(url):
req=urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36')
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
return html
def find_imgs(url,html):
p=r'<img class="BDE_Image" src="(.+\.jpg)"'#findall方法中如果有子组,那么返回的就是这个子组
imglist=re.findall(p,html)#用正则匹配自己想要的图片地址信息并提取出来
'''
for each in imglist:
print(each)
'''
for each in imglist:
filename=each.split("/")[-1]
urllib.request.urlretrieve(each,filename,None)#urlretrieve函数将URL表示的网络对象复制到本地文件
def save_imgs(folder,img_addrs):
pass
def download_img(folder='new_img'):
os.mkdir(folder)#mkdir是生成一个文件夹
os.chdir(folder)#chdir的目的是切换工作目录到指定文件夹
url="https://tieba.baidu.com/p/5483070492"
find_imgs(url,url_open(url))
if __name__=='__main__':
download_img()
这里是第二种方法,在这里我们使用requests模块来获取html信息,用urllib来将某个地址(url)的网络对象保存在本地。在获取网页html信息中,requests模块会更加方便快捷。
import urllib.request
import requests
import os
import random
import re
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
def url_open(url):
#!!!注意这里发生了变化,使用requests模块之后更加方便快捷
html=requests.post(url,headers=headers).text#post和get都可以
return html
def find_imgs(url,html):
p=r'<img class="BDE_Image" src="(.+\.jpg)"'#findall方法中如果有子组,那么返回的就是这个子组
imglist=re.findall(p,html)#用正则匹配自己想要的图片地址信息并提取出来
'''
for each in imglist:
print(each)
'''
for each in imglist:
filename=each.split("/")[-1]
urllib.request.urlretrieve(each,filename,None)#urlretrieve函数将URL表示的网络对象复制到本地文件
def save_imgs(folder,img_addrs):
pass
def download_img(folder='new_img'):
os.mkdir(folder)#mkdir是生成一个文件夹
os.chdir(folder)#chdir的目的是切换工作目录到指定文件夹
url="https://tieba.baidu.com/p/5483070492"
find_imgs(url,url_open(url))
if __name__=='__main__':
download_img()
这样就可以得到自己想要的图片了:
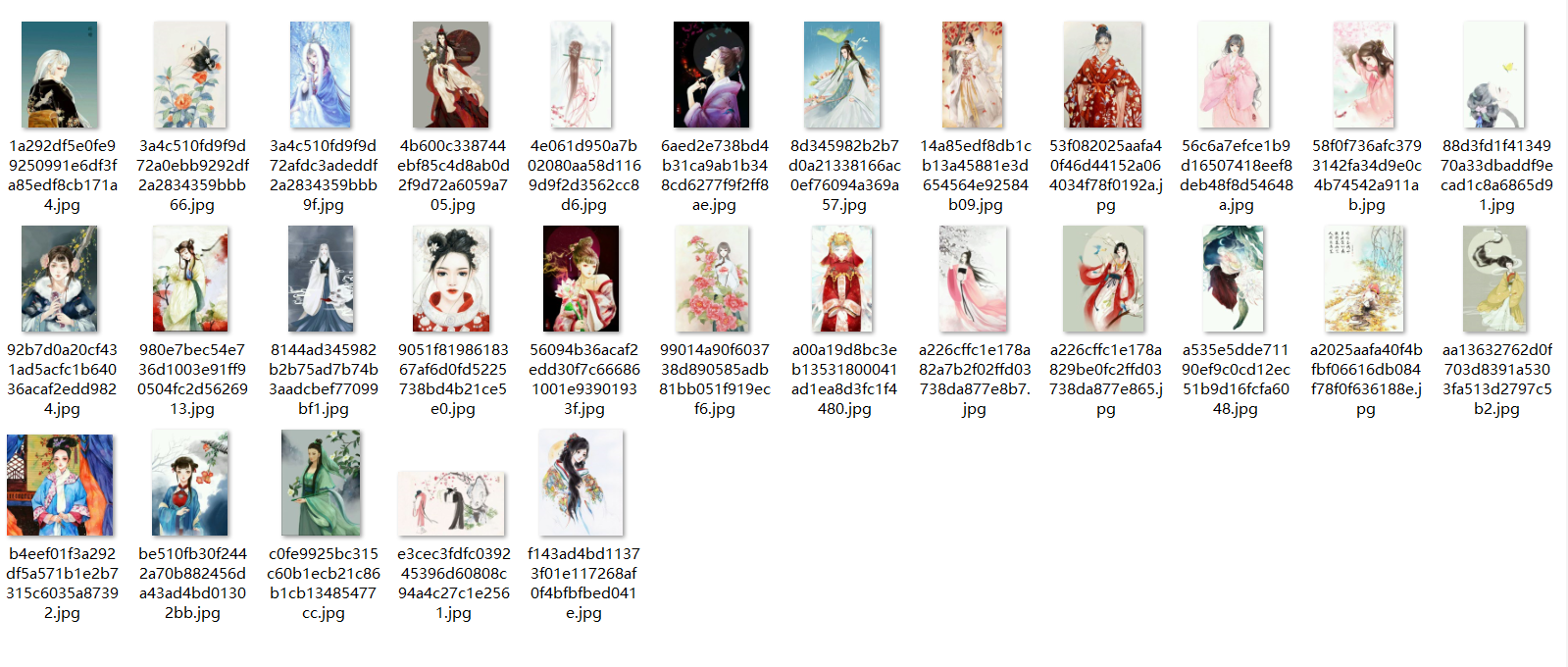

相关文章推荐
- python 跨语言数据交互、json、pickle(序列化)、urllib、requests(爬虫模块)、XML。
- Python爬虫 - 使用requests和re模块爬取慕课网课程信息
- Python爬虫实例(4)-用urllib、re和正则表达式爬取网页图片
- python利用urllib实现爬取京东网站商品图片的爬虫实例
- 使用requests+beautifulsoup模块实现python网络爬虫功能
- python爬虫--re结合xpath爬取图片
- python os模块实例(批量修改图片名称)
- [爬虫入门]Python中使用scrapy框架实现图片爬取
- Python 爬虫学习笔记一: requests 模块
- 使用 Python 模块 re 实现解析小工具
- Python2中的urllib、urllib2与Python3中的urllib以及第三方模块requests变化分析
- Python爬虫实现抓取网页图片
- Python爬虫实例——基于BeautifulSoup和requests实现
- Python 爬虫 urllib模块:get方式
- Python爬虫实现爬取京东手机页面的图片(实例代码)
- 用python实现的一个抓取图片的爬虫
- 使用 Python 模块 re 实现解析小工具
- python(1)-实现简单的图片爬虫
- python爬虫requests模块
- Python爬虫,Urllib模块