大数据第三次作业
题目一:信息的聚类分类练习(文件:wholesaledata.csv)
(1)聚类
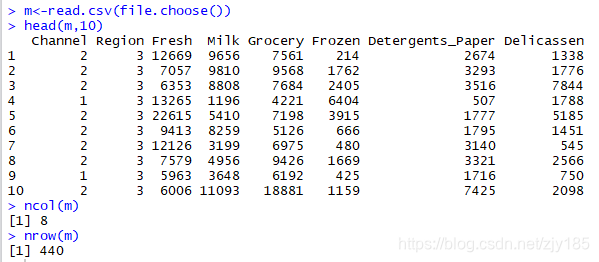
a.打开文件,由于行数过多,所以取前十行输出观察,并输出其行列数。
m<-read.csv(file.choose())
head(m,10)
ncol(m)
nrow(m)
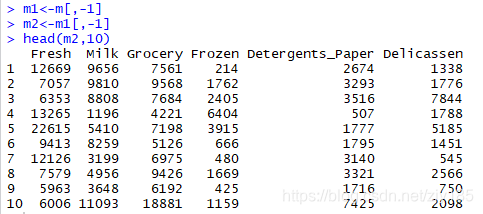
b.去掉数据中的前两列(频道和地区)
m1<-m[,-1]
m2<-m1[,-1]
head(m2,10)
c.计算变量间距离,形成相异度矩阵,聚类,画出聚类模型图
mydist<-dist(scale(m2),method=“euclidean”)
mycluster=hclust(mydist)
plot(mycluster)

d.数据较多,可以多分几类,在这里我把数据分成了十类
result<-cutree(mycluster,10)
result
下图表示每条数据在哪个类中

(2)分类
a.打开文件,由于行数过多,所以取前十行输出观察,并输出其行列数。
m<-read.csv(file.choose())
head(m,10)
ncol(m)
nrow(m)
b.在rpart和rpart.plot包上打钩,并生成训练集和测试集
library(“rpart”, lib.loc=“C:/Program Files/R/R-3.5.0/library”)
library(“rpart.plot”, lib.loc="~/R/win-library/3.5")
traindata<-m[2*(1:220)-1,]
testdata<-m[2*(1:220),]

c.生成决策树模型,绘制决策树
model<-rpart(Channel~.,traindata,method=“class”)
rpart.plot(model)

d.对测试集进行预测,并计算准确率
mypredict<-predict(model,testdata[,-1],type=“class”)
table(testdata[,1],mypredict)

准确率=(129+66)/220*100%=88.64%
题目二: A<-c(‘Y’,‘Y’,‘N’,‘N’,‘Y’)
B<-c(‘N’,‘Y’,‘Y’,‘Y’,‘N’)
C<-c('Y’,‘Y’,‘Y’,‘Y’,‘N’)
D<-c(‘Y’,‘Y’,‘y’,‘y’,‘Y’)
E<-c(‘N’,‘n’,‘n’,‘Y’,‘N’)
F<-c('Y’,‘n’,‘Y’,‘Y’,‘y’)
求上述信息的相异度矩阵。
A<-c(‘Y’,‘Y’,‘N’,‘N’,‘Y’)
B<-c(‘N’,‘Y’,‘Y’,‘Y’,‘N’)
C<-c(‘Y’,‘Y’,‘Y’,‘Y’,‘N’)
D<-c(‘Y’,‘Y’,‘y’,‘y’,‘Y’)
E<-c(‘N’,‘n’,‘n’,‘Y’,‘N’)
F<-c(‘Y’,‘n’,‘Y’,‘Y’,‘y’)
mydata<-rbind(A,B,C,D,E,F)
mydata
mydata[which(mydata==‘Y’)]=1
mydata[which(mydata==‘N’)]=0
mydata[which(mydata==‘y’)]=1
mydata[which(mydata==‘n’)]=0
distdata<-dist(mydata,method=“binary”)
distdata

