大数据中间件MongoDB
1.前言
相信说起MongoDB很多人都知道是NoSql,非关系型之类的,但是需要注意
1.和传统关系型数据库
Sqlserver、Mysql、Oracle相比,MongoDB身为非关系型数据库,在数据存储结构和数据查询以及数据海量存储上,拥有绝对的优势,并且可以说它与关系型数据库是互为优缺点,互补的关系,所以不要
主观的去给它们定义`谁更好一些",在实际中可以将模式固定的结构化数据存储在RDS,灵活的业务存储在MongoDB中
2.虽然
Redis也是非关系型数据库,但它和MongoDB没有可比性,因为Redis是操作内存,关注的是性能,多用于缓存和系统缓冲场景,而MongoDB则是文档型数据库,基于存储结构的灵活,适用于存储一些非标准且数据结构不固定的数据,所以不要去问
MongoDB可不可以用来做缓存,选择正确的方式做正确的事,才是最佳实践,因为业务场景决定技术点。
2.MongoDB基本操作及安装
1.MongoDB的安装参考这里,有专门记录Linux安装步骤,至于windows下的太简单,就不做记录了
2.一些常用基本的命令,更多的就不介绍了,这些可以在官方手册中查询学习
1.数据库操作
//查看已有数据库
show dbs
//1.使用数据库
//2.查看集合
use UserDB
show collecitons
//1.删除数据库
//2.修复数据库
//3.从127.0.0.1克隆一份数据库
db.dropDatabase();
db.repairDatabase();
db.cloneDatabase("127.0.0.1");
//1.获取数据库状态,可以查看集合等信息
//2.获取当前数据库名字
//3.客户端连接服务端的信息
//4.查看当前服务版本
db.stats();
db.getName();
db.getMongo();
db.version();
集合操作
//1.创建一个用户集合,最大存放1000个文档,达到容量自动删除旧数据
//2.查看用户表状态
db.createCollection("User",{"size":1024,capped:true,max:1000});
db.User.stats();
//1.查询所有用户数据
//2.查询指令列
db.User.find();
db.User.find({}, {name: 1, Code: 1});
//1.查询用户集合id大于5的数据
//2.查询用户集合id小于5的数据
//3.查询用户集合id大于3并且小9的数据
db.User.find({id: {$gt: 5}});
db.User.find({id: {$lt: 5}});
db.User.find({id: {$gte: 3, $lte: 9}});
//1.新增一条用户数据
//2.修改一条用户数据
//3.删除一条用户数据
db.User.save({name: '特朗普', id: 1, sex: unknow,age:8});
db.User.update({age: 9}, {$set: {name: '特朗普'}}, false, true);
db.User.remove({id: 1});
MongoDBHelper
1.首先需要通过Nuget或者手动下载Mongodb在C#中的驱动
MongoDB.Bson、
MongoDB.Driver、
MongoDB.Driver.Builders
2.实现简单的增删改查,在此仅供参考,没有很完善所以再拷贝去用的时候需要注意
internal class MongoHelper
{
private readonly MongoDatabase _db = null;
public MongoHelper()
{
var clientServer = new MongoClient("mongodb://127.0.0.1:27017").GetServer();
this._db = clientServer.GetDatabase("UserDB");
}
public bool Insert<T>(T entity)
{
BsonDocument doc = entity.ToBsonDocument();
WriteConcernResult result = this._db.GetCollection(typeof(T).Name).Insert(entity);
return result.Ok;
}
public bool DelEntity<T>(string whereField, string whereValue)
{
var query = Query.EQ(whereField, whereValue);
WriteConcernResult result = this._db.GetCollection(typeof(T).Name).Remove(query);
return result.Ok;
}
public bool UpdateEntity<T>(string whereField, string whereValue, string updateField, string updateValue)
{
var query = Query.EQ(whereField, whereValue);
var update = Update.Set(updateField, updateValue);
WriteConcernResult result = this._db.GetCollection(typeof(T).Name).Update(query, update);
return result.Ok;
}
public T FindOne<T>(string Field, string Value)
{
T oneEntity = default(T);
FindOneArgs args = new FindOneArgs { Query = Query.EQ(Field, Value) };
oneEntity = this._db.GetCollection(typeof(T).Name).FindOneAs<T>(args);
return oneEntity;
}
}
2.MongoDB适用场景
其实对于已经了解过基本概念的来说,我们更想知道什么时候使用它,怎么发挥他的特点,既然前面说到,他和关系传统数据库是互补的,并且拥有存储不规则数据的绝对优势,那么我们可以扩展出对业务数据的解耦,例如存储需要查询不同系统的高并发数据,将他们组合起来存储在MongoDB,避免使用时跨库跨服务查询以节约性能,具体如下
1.在我们的员工管理系统中,我们有3个不同的微服务,考勤、申请、以及用户服务,员工的考勤信息与申请服务挂钩,实际情况下一个微服务对应的数据表很多个,每天需要统计考勤信息,那么就需要调用3个不同的服务以及多个库表之间的连接,用于组合出需要的数据,此时我们可以利用,
数据异构工具,例如
DataX、
Canal、
Kettle等,在后台将数据组合存储到MondoDB,方便查询,以缓解防止集中访问时对服务器的压力
2.用户系统中线上运行的服务会产生大量的运行及访问日志,日志里会包含一些错误、警告、及用户行为等信息,通常服务会以文本的形式记录日志信息,这样可读性强,方便于日常定位问题,但当产生大量的日志之后,要想从大量日志里挖掘出有价值的内容,则需要对数据进行进一步的存储和分析。
3.项目初期数据库结构不稳定的情况下,这时不确定哪些表会有改变,可以使用Mongodb,例如一个表存储系统不同类型的数据, 某一天需求变更需要为某一个类型增加字段,对于动态存储,这时使用Mongodb就体现了优势所在
3.MongoDB架构设计
MongoDB分为3个大的核心模块,分别为
MongoDB query Language、
MongoDB Data Model、
查询引擎,首先将客户端请求通过
MongoDB query Language转换为MongoDB可识别的语句命令,再通过
MongoDB Data Model转换为Bson文档,最终交给存储引擎将数据存储或读取。 1.Wiredtiger引擎写入原理
当数据给到MongoDB 引擎后,首先写入内部缓存,然后将缓存数据同步磁盘,为防止在缓存写入磁盘数据丢失,MongoDB 采用双写的策略,在写入缓存的同时,利用
journaling buffer来存储数据的日志信息到
journal文件中
1.
journaling buffer是用于存放 mongodb 增删改 指令的缓冲区
2.
journal文件类似于关系数据库中的事务日志 2.索引与查询
1.
单个索引每个索引对应文档中的单个值,默认索引在id上
2.
复合索引可以在查询中使用多个索引,查询数据,如果经常查询多个字段,我们可以使用建立复合索引来提升性能,但是需要注意复合索引的顺序非常重要,大范围在前小范围在后
3.如果索引太多,插入更新数据会导致索引的重排,所以可以根据自身系统监控查询的字段,将查询较多的设为索引键
4.索引在内存中大概占据4kb的大小,并且是非聚集的
4.MongoDB复制集
在上面介绍中,我们使用的是一台服务器,一个
mongod服务进程.如果单纯的做学习和开发是完全可以承载的,但是在生产环境中,风险会增高,如果服务器宕机或者故障导致数据库有一段时间不可访问,而使用mongodb的复制功能来将数据副本保存在多台服务器上,即使一台服务器出错,也可以保证程序正常运行和数据安全,在实际落地中实现
MongoDB高可用方案
主从复制建议最少3个节点,一个
主节点用于读写,2个从节点用于
同步主节点数据在主节点故障时保证可以提供服务。 1.集群搭建
1.在MongoDB中创建多个配置文件,
数据和
日志需要创建实例自己独立的文件夹,
端口需要设置为不同,或者拷贝3个mongodb文件作为独立文件,然后独立启动
#复制三份配置文件 # Where and how to store data. storage: dbPath: /usr/local/mongodb/mongoserver/data/27017data #数据文件存放目录 journal: enabled: true systemLog: destination: file logAppend: true path: /usr/local/mongodb/mongoserver/log/mongodb27017.log # network interfaces net: port: 27017 #27018 #27019 bindIp: 127.0.0.1 replication: replSetName: rs0 #复制集名称,多个配置写一样的
2.根据配置启动不同端口的3个不同实例
./mongod -f mongo27017.conf ./mongod -f mongo27018.conf ./mongod -f mongo27019.conf
3.使用客户端连接,然后使用
rs.initiate()集群初始化
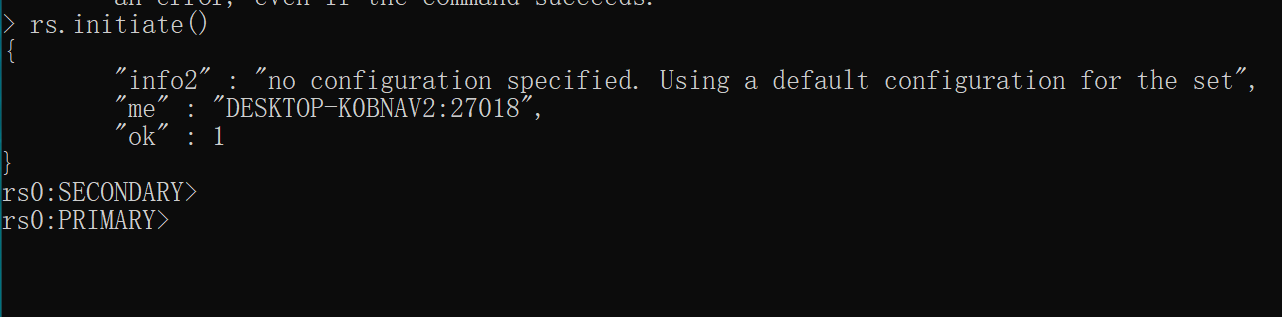
//局域网连接需要将ip设置为0.0.0.0 mongodb.exe --host 192.168.0.106 --port 27018 rs.initiate()
4.查看集群状态
rs.status(),然后使用
rs.add("192.168.0.106:27019")向集群中添加另外2个节点
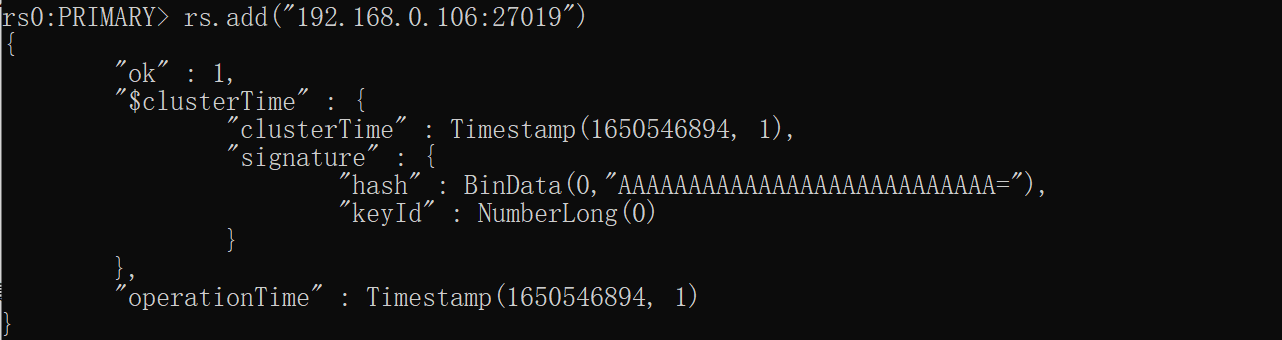
5.然后客户端连接集群
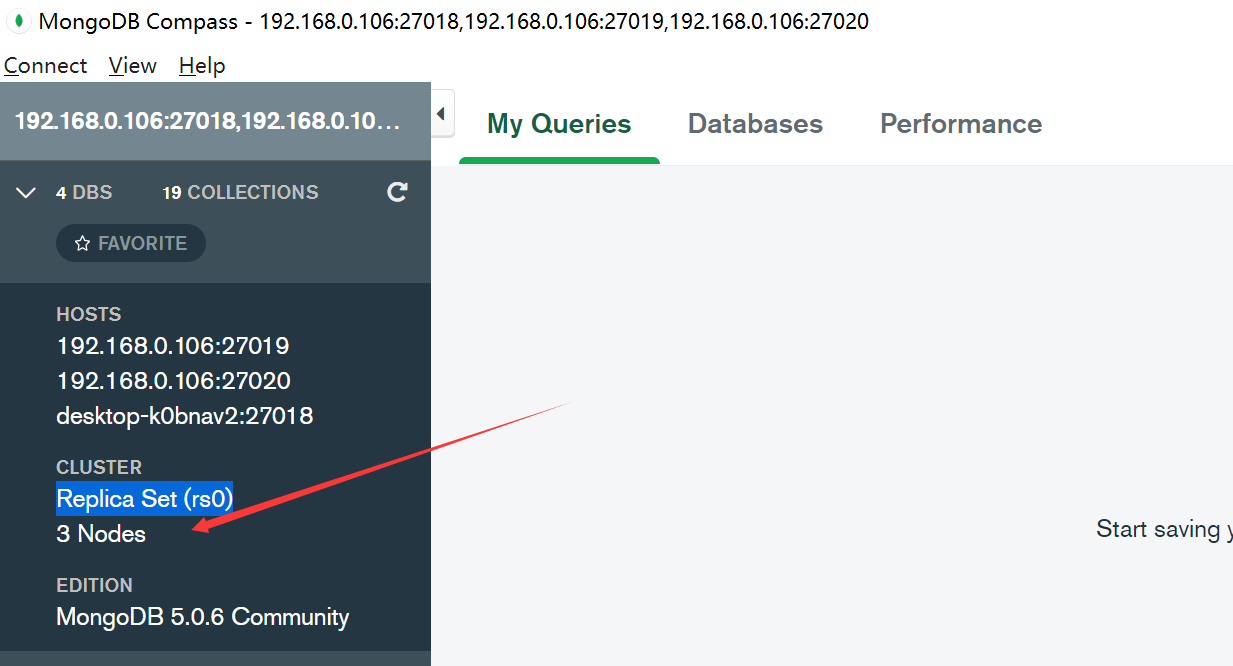
//连接字符串
mongodb://192.168.0.106:27018,192.168.0.106:27019,192.168.0.106:27020/?readPreference=primary&ssl=false
var clientServer = new MongoClient("mongodb://192.168.0.106:27018,192.168.0.106:27019,192.168.0.106:27020").GetServer();
2.选举机制
1.现在有27018、27019、27020 一主2从,那么当27018主节点宕机后,在各个节点有
心跳检测机制,如果在一定时间内,没有回复,那么从节点就会触发
选举机制选出新的主节点
- 1.从节点首先会各自投票
vote
自己为主节点 - 2.然后向其他节点拉票,如果节点给自己投了,就不能给别人投,选举规则过半数则为主节点,集群节点为奇数节点,偶数节点会产生脑裂,形成多个主节点
- 3.当主节点连接后,自动变为从节点

- SDP(10):文本式大数据运算环境-MongoDB-Engine功能设计
- MongoDB4.0分片集群搭建实现高并发大数据处理详解_一点课堂(多岸学院)
- 工具和中间件——Mongodb小白入门
- 大数据时代的数据存储,非关系型数据库MongoDB
- 大数据时代的数据存储,非关系型数据库MongoDB
- 7月目标 socket , 一致性哈希算法 ; mongodb分片; 分布式消息队列; 中间件的使用场景
- 大数据环境下mongoDB要加索引
- 大数据NOSQL,使用Redis常用命令 使用MongoDB常用命令
- 大数据时代的数据存储,非关系型数据库MongoDB
- 大数据环境下mongoDB为何要加索引浅析
- 大数据时代的数据存储,非关系型数据库MongoDB(一)(转)
- 数据库中间件 MyCAT 源码分析 —— SQL ON MongoDB
- MySQL数据库分布式服务中间件(添加id-generator的相关支持)mongodb
- 大数据复习复习(hadoo+hive+mongodb+hbase)
- nodejs+mongodb系列教程之(3/5)--理解路由和中间件
- 大数据时代的数据存储,非关系型数据库MongoDB
- 大数据时代的数据存储,非关系型数据库MongoDB(一)
- 小项目-数据爬取篇:scrapy框架,手机网页,工作信息存入MongoDB,代理ip中间件
- 大数据应用之:MongoDB从入门到精通你不得不知的21个为什么?
- 大数据时代的数据存储,非关系型数据库MongoDB