MySQL Replication 梳理详解
MySQL Replication
1 MySQL5.5以前的复制
异步、SQL线程串行化回放
MySQL内建的复制功能是构建大型,高性能应用程序的基础。主服务器将更新写入二进制日志文件,从服务器重新执行一遍来实现的
1.1 MySQL支持的复制类型
- 基于语句的复制:
在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。
MySQL 5.0及之前的版本仅支持基于语句的复制(也叫做逻辑复制,logical replication),这在数据库并不常见。master记录下改变数据的查询,然后,slave从中继日志中读取事件,并执行它,这些SQL语句与master执行的语句一样。
这种方式的优点就是实现简单。此外,基于语句的复制的二进制日志可以很好的进行压缩,而且日志的数据量也较小,占用带宽少——例如,一个更新GB的数据的查询仅需要几十个字节的二进制日志。而mysqlbinlog对于基于语句的日志处理十分方便。
但是,基于语句的复制并不是像它看起来那么简单,因为一些查询语句依赖于master的特定条件,例如,master与slave可能有不同的时间。所以,MySQL的二进制日志的格式不仅仅是查询语句,还包括一些元数据信息,例如,当前的时间戳。即使如此,还是有一些语句,比如,CURRENT USER函数,不能正确的进行复制。此外,存储过程和触发器也是一个问题。
另外一个问题就是基于语句的复制必须是串行化的。这要求大量特殊的代码,配置,例如InnoDB的next-key锁等。并不是所有的存储引擎都支持基于语句的复制。
- 基于行的复制:
把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
MySQL增加基于记录的复制,在二进制日志中记录下实际数据的改变,这与其它一些DBMS的实现方式类似。这种方式有优点,也有缺点。优点就是可以对任何语句都能正确工作,一些语句的效率更高。主要的缺点就是二进制日志可能会很大,而且不直观,所以,你不能使用mysqlbinlog来查看二进制日志。
- 混合类型的复制:
默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
1.2 复制相关的文件
除了二进制日志和中继日志文件外,还有其它一些与复制相关的文件。
- mysql-bin.index
服务器一旦开启二进制日志,会产生一个与二日志文件同名,但是以.index结尾的文件。它用于跟踪磁盘上存在哪些二进制日志文件。MySQL用它来定位二进制日志文件。
- mysql-relay-bin.index
该文件的功能与mysql-bin.index类似,但是它是针对中继日志,而不是二进制日志。
- master.info
保存master的相关信息。不要删除它,否则,slave重启后不能连接master。I/O线程更新master.info文件
- relay-log.info
包含slave中当前二进制日志和中继日志的信息。
1.3 复制的原理
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将更改应用到自己的数据上。
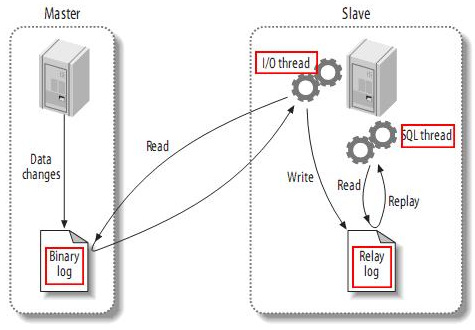
在每个事务更新数据完成之前,MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件还包括文件的名称以及bin-log的位置,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
复制过程有一个很重要的限制——复制在slave上是串行化的(完全顺序的执行日志中所记录的各种操作),也就是说master上的并行更新操作不能在slave上并行操作。
Slave继续作为其他节点的master,当设置log_slave_updates时,你可以让slave扮演其它slave的master。此时,slave把SQL线程执行的事件写进行自己的二进制日志(binary log),然后,它的slave可以获取这些事件并执行它。

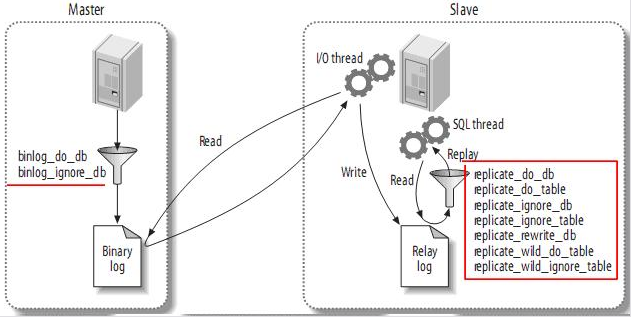
复制过滤,复制过滤可以让你只复制服务器中的一部分数据,有两种复制过滤:在master上过滤二进制日志中的事件;在slave上过滤中继日志中的事件。
1.4 复制的常用拓扑结构
- 单一master和多slave
由一个master和一个slave组成复制系统是最简单的情况。Slave之间并不相互通信,只能与master进行通信。
在实际应用场景中,MySQL复制90%以上都是一个Master复制到一个或者多个Slave的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。因为只要Master和Slave的压力不是太大(尤其是Slave端压力)的话,异步复制的延时一般都很少很少。尤其是自从Slave端的复制方式改成两个线程处理之后,更是减小了Slave端的延时问题。而带来的效益是,对于数据实时性要求不是特别Critical的应用,只需要通过廉价的pcserver来扩展Slave的数量,将读压力分散到多台Slave的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈,毕竟在大多数数据库应用系统中的读压力还是要比写压力大很多。这在很大程度上解决了目前很多中小型网站的数据库压力瓶颈问题,甚至有些大型网站也在使用类似方案解决数据库瓶颈。

如果写操作较少,而读操作很时,可以采取这种结构。你可以将读操作分布到其它的slave,从而减小master的压力。但是,当slave增加到一定数量时,slave对master的负载以及网络带宽都会成为一个严重的问题。
这种结构虽然简单,但是,它却非常灵活,足够满足大多数应用需求。一些建议:
- 不同的slave扮演不同的作用(例如使用不同的索引,或者不同的存储引擎);
- 用一个slave作为备用master,只进行复制;
- 用一个远程的slave,用于灾难恢复;
- 主动模式的Master-Master(Master-Master in Active-Active Mode)
Master-Master复制的两台服务器,将对方作为自己的master,同时将自己作为对方的slave。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
可能有些读者朋友会有一个担心,这样搭建复制环境之后,难道不会造成两台MySQL之间的循环复制么?实际上MySQL自己早就想到了这一点,所以在MySQL的BinaryLog中记录了当前MySQL的server-id,而且这个参数也是我们搭建MySQLReplication的时候必须明确指定,而且Master和Slave的server-id参数值必须要不一致才能使MySQLReplication搭建成功。一旦有了server-id的值之后,MySQL就很容易判断某个变更是从哪一个MySQLServer最初产生的,所以就很容易避免出现循环复制的情况。而且,如果我们不打开记录Slave的BinaryLog的选项(--log-slave-update)的时候,MySQL根本就不会记录复制过程中的变更到BinaryLog中,就更不用担心可能会出现循环复制的情形了。
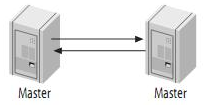
主动的Master-Master复制有一些特殊的用处。例如,地理上分布的两个部分都需要自己的可写的数据副本。这种结构最大的问题就是更新冲突。
- 主动-被动模式的Master-Master(Master-Master in Active-Passive Mode)
这是master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中一个服务只能进行只读操作。

- 级联复制架构 Master –Slaves - Slaves
在有些应用场景中,可能读写压力差别比较大,读压力特别的大,一个Master可能需要上10台甚至更多的Slave才能够支撑注读的压力。这时候,Master就会比较吃力了,因为仅仅连上来的SlaveIO线程就比较多了,这样写的压力稍微大一点的时候,Master端因为复制就会消耗较多的资源,很容易造成复制的延时。
遇到这种情况如何解决呢?这时候我们就可以利用MySQL可以在Slave端记录复制所产生变更的BinaryLog信息的功能,也就是打开—log-slave-update选项。然后,通过二级(或者是更多级别)复制来减少Master端因为复制所带来的压力。也就是说,我们首先通过少数几台MySQL从Master来进行复制,这几台机器我们姑且称之为第一级Slave集群,然后其他的Slave再从第一级Slave集群来进行复制。从第一级Slave进行复制的Slave,我称之为第二级Slave集群。如果有需要,我们可以继续往下增加更多层次的复制。这样,我们很容易就控制了每一台MySQL上面所附属Slave的数量。这种架构我称之为Master-Slaves-Slaves架构
这种多层级联复制的架构,很容易就解决了Master端因为附属Slave太多而成为瓶颈的风险。

当然,如果条件允许,我更倾向于建议大家通过拆分成多个Replication集群来解决
上述瓶颈问题。毕竟Slave并没有减少写的量,所有Slave实际上仍然还是应用了所有的数据变更操作,没有减少任何写IO。相反,Slave越多,整个集群的写IO总量也就会越多,我们没有非常明显的感觉,仅仅只是因为分散到了多台机器上面,所以不是很容易表现出来。
此外,增加复制的级联层次,同一个变更传到最底层的Slave所需要经过的MySQL也会更多,同样可能造成延时较长的风险。
而如果我们通过分拆集群的方式来解决的话,可能就会要好很多了,当然,分拆集群也需要更复杂的技术和更复杂的应用系统架构。
- 带从服务器的Master-Master结构(Master-Master with Slaves)
这种结构的优点就是提供了冗余。在地理上分布的复制结构,它不存在单一节点故障问题,而且还可以将读密集型的请求放到slave上。
级联复制在一定程度上面确实解决了Master因为所附属的Slave过多而成为瓶颈的问题,但是他并不能解决人工维护和出现异常需要切换后可能存在重新搭建Replication的问题。这样就很自然的引申出了DualMaster与级联复制结合的Replication架构,我称之为Master-Master-Slaves架构
和Master-Slaves-Slaves架构相比,区别仅仅只是将第一级Slave集群换成了一台单独的Master,作为备用Master,然后再从这个备用的Master进行复制到一个Slave集群。
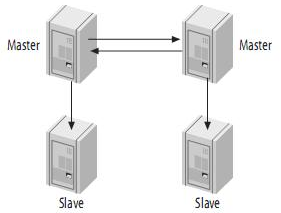
这种DualMaster与级联复制结合的架构,最大的好处就是既可以避免主Master的写入操作不会受到Slave集群的复制所带来的影响,同时主Master需要切换的时候也基本上不会出现重搭Replication的情况。但是,这个架构也有一个弊端,那就是备用的Master有可能成为瓶颈,因为如果后面的Slave集群比较大的话,备用Master可能会因为过多的SlaveIO线程请求而成为瓶颈。当然,该备用Master不提供任何的读服务的时候,瓶颈出现的可能性并不是特别高,如果出现瓶颈,也可以在备用Master后面再次进行级联复制,架设多层Slave集群。当然,级联复制的级别越多,Slave集群可能出现的数据延时也会更为明显,所以考虑使用多层级联复制之前,也需要评估数据延时对应用系统的影响。
1.5 参考资料:
http://blog.sina.com.cn/s/blog_aed82f6f01019nzj.html
http://www.linuxidc.com/Linux/2015-02/112647.htm
http://www.cnblogs.com/kristain/articles/4142970.html
2 MySQL5.6的复制
2.1 半同步复制
由于Mysql的复制都是基于异步进行的,在特殊情况下不能保证数据的成功复制,因此在mysql5.5之后使用了来自google补丁,可以将Mysql的复制实现半同步模式。MySQL5.6的官方版本已经收录了半同步复制功能,需要为主服务器加载对应的插件。在Mysql的安装目录下的lib/plugin/目录中具有对应的插件semisync_master.so,semisync_slave.so,其中semisync_master.so是主服务器上的插件,而semisync_slave.so则是从服务器上的插件。
随着MySQL 5.6中引入了全局事务ID(GTIDs)
- 在主服务器的mysql服务器上执行如下命令
mysql> install pluginrpl_semi_sync_master soname 'semisync_master.so'; 安装模块
mysql> set global rpl_semi_sync_master_enabled = 1; 启用半同步复制主节点
mysql> set global rpl_semi_sync_master_timeout = 1000; 超时时间
mysql> show variables like '%semi%'; 查看设置是否成功

- 在从服务器的mysql服务器上执行如下命令
mysql> install pluginrpl_semi_sync_slave soname 'semisync_slave.so'; 安装模块
mysql> set global rpl_semi_sync_slave_enabled = 1; 启用半同步复制从节点
mysql> stop slave;
mysql> start slave;
mysql> show variables like '%semi%'; 查看设置是否成功

- 验证半同步复制是否生效在主服务器上执行如下命令
mysql> show global status like 'rpl_semi%';

2.2 并行复制
MySQL 5.6版本也支持所谓的并行复制,但是其并行只是基于schema的,也就是基于库的。如果用户的MySQL数据库实例中存在多个schema,对于从机复制的速度的确可以有比较大的帮助。
在下图的红色框框部分就是实现并行复制的关键所在。在MySQL 5.6版本之前,Slave服务器上有两个线程I/O线程和SQL线程。I/O线程负责接收二进制日志(更准确的说是二进制日志的event),SQL线程进行回放二进制日志。如果在MySQL 5.6版本开启并行复制功能,那么SQL线程就变为了coordinator线程,coordinator线程主要负责以前两部分的内容:
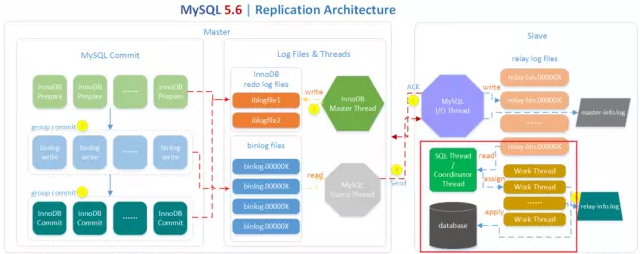
- 若判断可以并行执行,那么选择worker线程执行事务的二进制日志
- 若判断不可以并行执行,如该操作是DDL,亦或者是事务跨schema操作,则等待所有的worker线程执行完成之后,再执行当前的日志
这意味着coordinator线程并不是仅将日志发送给worker线程,自己也可以回放日志,但是所有可以并行的操作交付由worker线程完成。coordinator线程与worker是典型的生产者与消费者模型。
上述机制实现了基于schema的并行复制存在两个问题,首先是crash safe功能不好做,因为可能之后执行的事务由于并行复制的关系先完成执行,那么当发生crash的时候,这部分的处理逻辑是比较复杂的。从代码上看,5.6这里引入了Low-Water-Mark标记来解决该问题,从设计上看(WL#5569),其是希望借助于日志的幂等性来解决该问题,不过5.6的二进制日志回放还不能实现幂等性。另一个最为关键的问题是这样设计的并行复制效果并不高,如果用户实例仅有一个库,那么就无法实现并行回放,甚至性能会比原来的单线程更差。而单库多表是比多库多表更为常见的一种情形。
2.3 参考资料
http://jilili.blog.51cto.com/6617089/1203805
http://mp.weixin.qq.com/s?__biz=MjM5MjIxNDA4NA==&mid=205236417&idx=1&sn=15281c834348911cea106478aa819175&3rd=MzA3MDU4NTYzMw==&scene=6#rd
http://blog.itpub.net/24945919/viewspace-764369/
3 MySQL5.7的复制
3.1 真正的并行复制
MySQL 5.7才可称为真正的并行复制,这其中最为主要的原因就是slave服务器的回放与主机是一致的即master服务器上是怎么并行执行的slave上就怎样进行并行回放。不再有库的并行复制限制,对于二进制日志格式也无特殊的要求(基于库的并行复制也没有要求)。
MTS: Prepared transactions slave parallel applier,可见:WL#6314。该并行复制的思想最早是由MariaDB的Kristain提出,并已在MariaDB 10中出现,相信很多选择MariaDB的小伙伴最为看重的功能之一就是并行复制。
MySQL 5.7并行复制的思想简单易懂,一言以蔽之:一个组提交的事务都是可以并行回放,因为这些事务都已进入到事务的prepare阶段,则说明事务之间没有任何冲突(否则就不可能提交)。
为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:
- DATABASE:默认值,基于库的并行复制方式
- LOGICAL_CLOCK:基于组提交的并行复制方式
3.2 并行复制配置与调优
- master_info_repository
开启MTS功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于元master.info这个文件的更新将会大幅提升,资源的竞争也会变大。在之前InnoSQL的版本中,添加了参数来控制刷新master.info这个文件的频率,甚至可以不刷新这个文件。因为刷新这个文件是没有必要的,即根据master-info.log这个文件恢复本身就是不可靠的。在MySQL 5.7中,Inside君推荐将master_info_repository设置为TABLE,来减小这部分的开销。
- slave_parallel_workers
若将slave_parallel_workers设置为0,则MySQL 5.7退化为原单线程复制,但将slave_parallel_workers设置为1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程复制。然而,这两种性能却又有一些的区别,因为多了一次coordinator线程的转发,因此slave_parallel_workers=1的性能反而比0还要差,在Inside君的测试下还有20%左右的性能下降。
3.3 Enhanced Multi-Threaded Slave配置
说了这么多,要开启enhanced multi-threaded slave其实很简单,只需根据如下设置:
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
并行复制监控
复制的监控依旧可以通过SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema架构下多了以下这些元数据表,用户可以更细力度的进行监控:
mysql> show tables like 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)
3.4 参考资料
http://mp.weixin.qq.com/s?__biz=MjM5MjIxNDA4NA==&mid=205236417&idx=1&sn=15281c834348911cea106478aa819175&3rd=MzA3MDU4NTYzMw==&scene=6#rd
4 复制延迟检测
4.1 通过Slave状态监控
在MySQL复制环境中,我们通常只根据 Seconds_Behind_Master 的值来判断SLAVE的延迟。这么做大部分情况下尚可接受,但并不够准确,而应该考虑更多因素。
- 首先看 Relay_Master_Log_File 和 Master_Log_File 是否有差异;
- 如果Relay_Master_Log_File 和 Master_Log_File 是一样的话,再来看Exec_Master_Log_Pos 和 Read_Master_Log_Pos 的差异,对比SQL线程比IO线程慢了多少个binlog事件;
- 如果Relay_Master_Log_File 和 Master_Log_File 不一样,那说明延迟可能较大,需要从MASTER上取得binlog status,判断当前的binlog和MASTER上的差距;
4.2 通过pt工具实时监控延迟
percona-toolkit源自Maatkit 和Aspersa工具,这两个工具是管理mysql的最有名的工具,现在Maatkit工具已经不维护了,请大家还是使用percona-toolkit吧!这些工具主要包括开发、性能、配置、监控、复制、系统、实用六大类,作为一个优秀的DBA,里面有的工具非常有用,如果能掌握并加以灵活应用,将能极大的提高工作效率。
4.3 参考资料
http://blog.chinaunix.net/uid/20639775/list/1.html?sid=159653
http://www.jb51.net/article/75070.htm
http://www.cnblogs.com/zping/p/5678652.html
http://www.cnblogs.com/kevingrace/p/5685511.html
(adsbygoogle = window.adsbygoogle || []).push({});

- View 绘制流程梳理及 Measure 过程详解
- 《这就是搜索引擎-核心技术详解》简单梳理+一些知识图谱的知识
- MySQL 基础知识梳理学习(五)----详解MySQL两次写的设计及实现
- JVM梳理-(3)jvm参数详解
- js知识梳理--apply()使用详解
- (复学梳理) 快速幂求模[代码思想详解]
- 基于C++ cin、cin.get()、cin.getline()、getline()、gets()函数的使用详解
- TCP协议详解
- web_custom_request函数详解
- (总结)CentOS Linux搭建SVN Server配置详解
- 2.X集群启动详解
- ADO.NET - 全面梳理
- Epoll模型详解
- java enum(枚举)使用详解 + 总结
- requestWindowFeature使用详解
- OnEraseBkGnd函数详解
- C语言条件编译详解
- TCP-IP协议详解(1)邮差与邮局 (网络协议概观)
- (总结)Nginx配置文件nginx.conf中文详解