【Java面试】Mysql为什么使用B+Tree作为索引结构
一个工作8年的粉丝私信了我一个问题。
他说这个问题是去阿里面试的时候被问到的,自己查了很多资料也没搞明白,希望我帮他解答。
问题是: “Mysql为什么使用B+Tree作为索引结构”
关于这个问题,看看普通人和高手的回答。
普通人:
B+数它的特征就是相对B数来说他的这个非叶子节点不存数据,所有的数据都存在叶子节点
相对于B数来说他的查询次数IO次数会更稳。
高手:
关于这个问题 ,我从几个方面来回答。
首先,常规的数据库存储引擎,一般都是采用B树或者B+树来实现索引的存储。
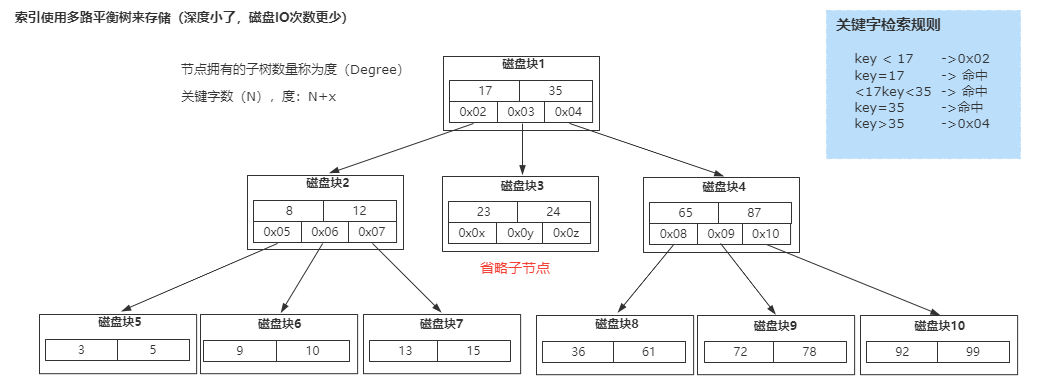
因为B树是一种多路平衡树,用这种存储结构来存储大量数据,它的整个高度会相比二叉树来说,会矮很多。
而对于数据库来说,所有的数据必然都是存储在磁盘上的,而磁盘IO的效率实际上是很低的,特别是在随机磁盘IO的情况下效率更低。
所以树的高度能够决定磁盘IO的次数,磁盘IO次数越少,对于性能的提升就越大,这也是为什么采用B树作为索引存储结构的原因。
但是在Mysql的InnoDB存储引擎里面,它用了一种增强的B树结构,也就是B+树来作为索引和数据的存储结构。
相比较于B树结构,B+树做了几个方面的优化。
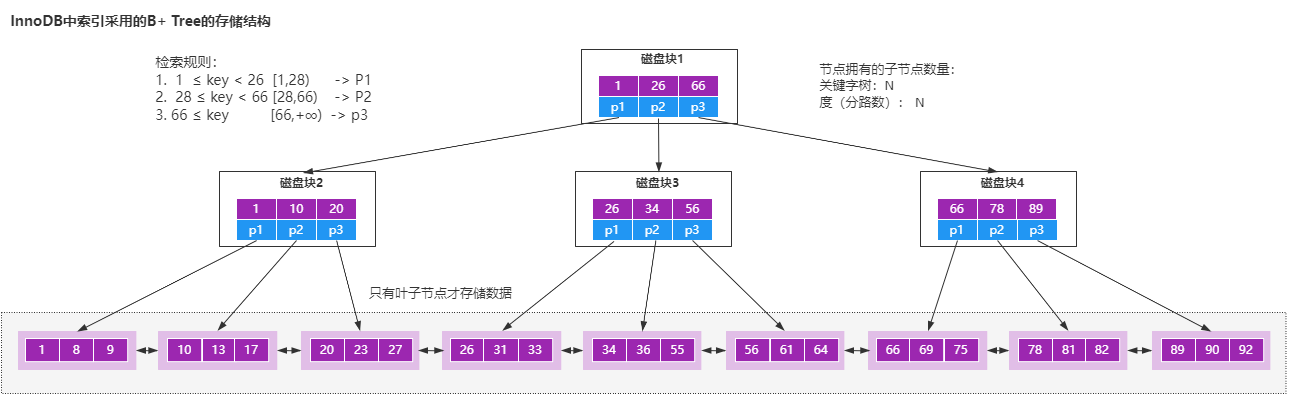
- B+树的所有数据都存储在叶子节点,非叶子节点只存储索引。
- 叶子节点中的数据使用双向链表的方式进行关联。
使用B+树来实现索引的原因,我认为有几个方面。
- B+树非叶子节点不存储数据,所以每一层能够存储的索引数量会增加,意味着B+树在层高相同的情况下存储的数据量要比B树要多,使得磁盘IO次数更少。
- 在Mysql里面,范围查询是一个比较常用的操作,而B+树的所有存储在叶子节点的数据使用了双向链表来关联,所以在查询的时候只需查两个节点进行遍历就行,而B树需要获取所有节点,所以B+树在范围查询上效率更高。
- 在数据检索方面,由于所有的数据都存储在叶子节点,所以B+树的IO次数会更加稳定一些。
- 因为叶子节点存储所有数据,所以B+树的全局扫描能力更强一些,因为它只需要扫描叶子节点。但是B树需要遍历整个树。
另外,基于B+树这样一种结构,如果采用自增的整型数据作为主键,还能更好的避免增加数据的时候,带来叶子节点分裂导致的大量运算的问题。
总的来说,我认为技术方案的选型,更多的是去解决当前场景下的特定问题,并不一定是说B+树就是最好的选择,就像MongoDB里面采用B树结构,本质上来说,其实是关系型数据库和非关系型数据库的差异。
以上就是我对这个问题的理解。
总结
对于“为什么要选择xx技术”的问题,其实很好回答。
只要你对这个技术本身的特性足够了解,那么自然就知道为什么要这么设计。
就像,我们在业务开发中,知道什么时候使用List,什么时候使用Map,道理是一样的。
如果有任何面试问题、职业发展问题、学习问题,都可以私信我。
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
Mic带你学架构! 如果本篇文章对您有帮助,还请帮忙点个关注和赞,您的坚持是我不断创作的动力。欢迎关注「跟着Mic学架构」公众号公众号获取更多技术干货!

- 为什么mysql使用了B+tree和Hash表作为索引,他们两者的区别是什么?为什么不使用数组或平衡二叉树又或者采用B-Tree呢?
- 为什么Mysql的常用引擎都默认使用B+树作为索引?
- mysql5.6.19下子查询为什么无法使用索引
- MySQL索引使用的数据结构:B-Tree和B+Tree
- 数据库为什么要用B+树结构--MySQL索引结构的实现
- MySQL进阶篇(02):索引体系划分,B-Tree结构说明
- mysql 索引B-Tree类型对索引使用的生效和失效情况详解
- 数据库为什么要用B+树结构--MySQL索引结构的实现
- 使用递归删除树形结构的所有子节点(java和mysql实现)
- 详述 MySQL 中 InnoDB 的索引结构以及使用 B+ 树实现索引的原因
- DB疑问解答之 --- 为什么使用树结构组织索引
- 观后感-数据库为什么要使用索引这种结构
- mysql5.6.19下子查询为什么无法使用索引
- 使用递归算法结合数据库解析成java树形结构 1、准备表结构及对应的表数据 a、表结构: create table TB_TREE ( CID NUMBER not null, CNAME VAR
- 数据库为什么要用B+树结构--MySQL索引结构的实现
- Java异常机制心得 作为一个C++程序员,长期使用返回值表示错误,接触Java以后,一直不习惯也不理解Java的异常机制,为什么返回一个错误要抛出一个异常,...
- 使用java程序比较mysql表结构
- 数据库为什么要用B+树结构--MySQL索引结构的实现
- 深入分析mysql为什么不推荐使用uuid或者雪花id作为主键
- 面试官:为什么Mysql中Innodb的索引结构采取B+树?